1月21日,中国计算机学会(CCF)推荐的A类国际学术会议ICLR 2023论文接收结果公布。中国人民大学高瓴人工智能学院师生有6篇论文被录用。国际表征学习大会(International Conference on Learning Representations,简称ICLR ) 是深度学习领域的顶级会议,关注有关深度学习各个方面的前沿研究,本届会议录用率为31.8%。

论文介绍
论文题目:Uni-Mol: A Universal 3D Molecular Representation Learning Framework
作者:周耕墨*,高志锋*,丁乾坤,郑行,许洪腾,魏哲巍,张林峰,柯国霖
论文概述:分子表示学习近期获得了研究者们极大的关注。主要是因为它在有限的监督数据学习中表现出色,如药物设计领域。然而在大多数方法中,分子被视为一维序列字符串或二维拓扑图,这限制了方法在下游任务中引入三维信息的能力,特别是几乎无法用于三维相关的几何预测或生成。在此,我们提出了Uni-Mol,一个通用的三维分子表示学习框架,它大大扩展了方法的表示能力和应用范围。Uni-Mol由两个具有相同SE(3)-等变性的自注意力模型组成:一个由两亿余分子构象训练的分子预训练模型;一个是由三百万蛋白口袋数据训练的口袋预训练模型。这两个模型独立用于不同的下游任务,而蛋白质-配体结合任务中则结合起来用。通过适当引入三维信息,Uni-Mol在分子性质预测任务中优于之前的工作。此外,Uni-Mol在三维空间任务中取得了优异表现,包括蛋白质-配体结合姿态预测、分子构象生成等。最后,我们也通过实验表明,Uni-Mol可以成功地应用于具有少量数据的任务,如口袋可药性预测。代码、模型和数据均已开源。
论文介绍
论文题目:Symbolic Physics Learner: Discovering governing equations via Monte Carlo tree search
作者:孙方正,刘扬,王建勋,孙浩
通讯作者:孙浩
论文概述:现代科学的发展主要依赖于简洁而优美的数学方程,得益于符号方程可解释、可通用的特征,即便是复杂系统,其运行机制也可以被合理诠释。基于测量数据挖掘非线性动力系统的控制方程,在科学探索和工程应用中扮演重要角色,但同时面临巨大挑战。为此,本文提出了一种新颖的“符号物理学习机”(SPL),实现自动化数学方程符号回归:首先,利用有限的数学算子作为基础符号单元,建立简明、易计算且具有强表示能力的数学符号解析树;然后,采用蒙特卡洛树搜索策略,在离散无穷大可行域内实现兼顾探索和利用的优化目标,从稀疏噪声测量数据中自动搜寻最优解析树表达形式,具备计算效率高、延展性好特征。实验结果表明,本文提出的SPL方法提供了一种有效的符号回归新范式,优于已有方法,可用于探索复杂动力系统状态演化机理、变量隐含物理关系和潜在控制方程/定律。【注:本文录用标签为Accept (oral): notable-top-5%】
论文介绍
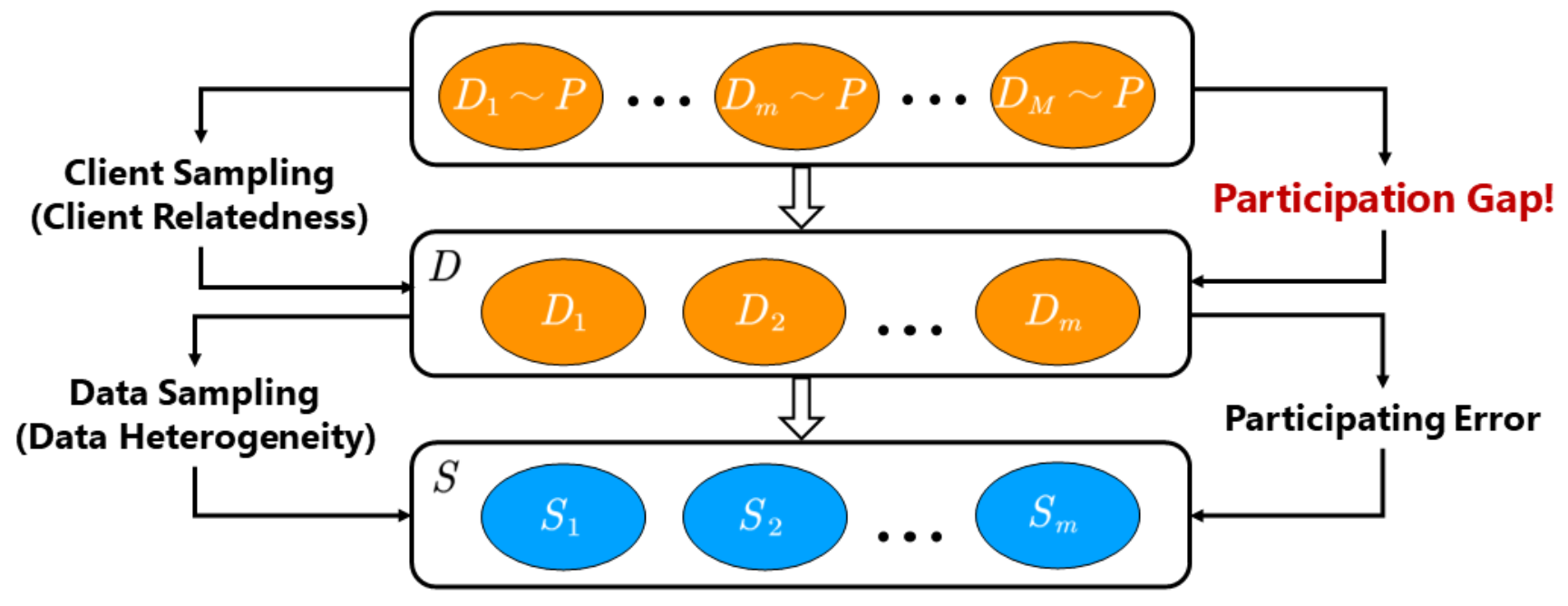
论文题目:Generalization Bounds for Federated Learning: Fast Rates, Unparticipating Clients and Unbounded Losses
作者:胡啸林,李少杰,刘勇
通讯作者:刘勇
论文概述:在典型的联邦学习场景中,不同客户端(用户)对应的数据分布并不相同。由于隐私保护和无线网络稳定性等因素的限制,实际参与联邦学习训练的客户端往往只占全部客户端的一小部分。考虑到未参与训练的客户端与参与训练的客户端存在数据分布上的差异,参与训练的客户端训练好的模型能不能使得未参与训练的客户端获益成为亟待回答的问题。联邦学习社区已有工作大多只关注训练过程中的优化收敛速度,泛化分析方面仅有的工作也只是考虑了参与训练的客户端。本文对未参与训练的客户端对应的泛化性能进行了分析,从理论上阐明了影响未参与训练的客户端获益的因素。
具体来讲,针对数据分布不同的特点,本文采用了双层分布的理论分析框架,即假设不同客户端的数据分布采样自一个元分布。该假设不仅体现了不同客户端之间数据异质性的特点,还刻画了数据分布之间的联系。本文在损失有界的假设下基于复杂度方法得到了更快的泛化收敛率,在损失无界的假设下给出了基于小球法的理论结果,无界损失下的理论结果适用于损失函数为重尾分布的情况。
作者:钟勇*,刘洪涛*,刘晓东,鲍凡,沈蔚然,李崇轩
通讯作者:沈蔚然,李崇轩
论文概述:深度生成模型(Deep generative model,DGM)非常渴望数据,因为在有限的数据上学习复杂的模型会遭遇大方差并且容易过拟合。受偏差-方差权衡的经典观点启发,我们提出了正则化深度生成模型(Reg-DGM),该模型利用不可迁移的预训练模型来减少有限数据下生成模型的方差。形式上,Reg-DGM优化了某个散度和能量函数期望值的加权和,其中散度定义在数据分布和模型分布之间以及能量函数由预训练模型分布定义。我们分析了一个简单但具有代表性的高斯拟合情况,以展示加权超参数如何权衡偏差和方差。理论上,我们描述了Reg-DGM在非参数设置下的全局最小值的存在性和唯一性,并证明了其收敛性在使用基于梯度的方法训练神经网络情况下。实验上,Reg-DGM利用各种预先训练的特征提取器和依赖于真实数据的能量函数,一致提升有限数据下的强DGM的生成性能,并获得与最先进方法相比具有竞争力的结果。
作者:鲍凡*,赵敏*,郝中楷,李沛尧,李崇轩,朱军
通讯作者:李崇轩,朱军
论文概述:可逆分子设计任务在材料科学、药物发现等领域至关重要,其目的是生成满足特定性质的分子。本文提出了一种一般的3D分子可控生成框架:等变能量函数引导的随机微分方程(EEGSDE),即通过定义能量函数对扩散模型进行指导生成。理论上,我们证明了只要能量函数具有旋转不变性, 则EEGSDE可以保留3D分子构象中的几何对称性。实验上,我们在生成满足特定量子性质和分子结构的分子中取得了SOTA的结果。此外,通过对能量函数线性组合,EEGSDE可以生成具有多种目标性质的分子。
论文介绍
论文题目:Conditional Antibody Design as 3D Equivariant Graph Translation
作者:孔祥哲,黄文炳,刘洋
通讯作者:黄文炳,刘洋
论文概述:作为一种特殊的蛋白质,抗体在人体免疫机制中扮演重要角色,是药物研发的重点对象。如何利用人工智能方法加速抗体特别是其CDR区域的设计和优化,是智能药物发现领域的焦点问题。已有方法存在几点不足:1)没考虑抗体的完整作用区域;2)没有很好建模抗体3维结构的几何对称性;3)自回归地预测抗体1维氨基酸序列的方式较为低效。本文提出了一种多通道等变图神经网络的设计方法MEAN,能基于抗原-抗体的完整可变区域,同时生成抗体CDR区域的1维序列和对接后的3维几何结构。MEAN满足E(3)等变性,因而具备高泛化性;MEAN能一次性预测CDR所有氨基酸类别,因而具备高效性。与传统方法相比,MEAN的生成效果更佳;特别针对抗体优化任务,MEAN优化后的抗体在目标抗原的中和力上比传统方法提升34%以上。
来源:高瓴人工智能学院
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号