信息来源:人大高瓴人工智能学院 发布日期:2026年3月19日
01 引言
传统图像检索技术依托视觉-语言模型的语义对齐能力,实现了单张图片的物体识别与内容匹配,在公开图像检索场景中取得了长足进步,能够完成基础的语义检索需求。
但这类技术存在根本性的范式局限:将单张图片视为独立个体,仅关注画面本身的视觉特征,无法理解相册中图片之间的时间脉络、空间关联与事件因果逻辑。
面对“找到烟花秀结束后几天前往海边拍摄的照片”这类依赖上下文关联的复杂查询,传统方法难以串联分散的视觉线索,无法完成长程、多步的深度检索任务。
为此,中国人民大学高瓴人工智能学院窦志成教授团队联合OPPO研究院,正式提出了DeepImageSearch,一个将图像检索从“逐张语义匹配”推向“语料库级上下文推理”的全新范式。该研究同时构建了首个相关评测基准DISBench,并设计了智能体框架ImageSeeker。

论文标题:
DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories
作者:
邓琛龙,邓梦洁,吴钧杰,曾趸,王腾,谢青松,黄嘉登,马晟杰,张长旺,王兆祥,王俊,朱余韬,窦志成
论文链接:
https://arxiv.org/abs/2602.10809
Github项目主页:
https://github.com/RUC-NLPIR/DeepImageSearch
Huggingface数据集:
https://huggingface.co/datasets/RUC-NLPIR/DISBench
Leaderboard:
https://huggingface.co/spaces/RUC-NLPIR/DISBench-Leaderboard
02 Demo:探索个人视觉历史的智能助手
团队提出的ImageSeeker智能体不仅在DISBench测试集中表现出强大的推理能力,其开源的Demo还支持加载用户的个人相册,解决用户自定义的复杂相册检索需求。如图所示,用户可以直接用自然语言提出复杂的跨事件问题,ImageSeeker能够在海量照片中自主调用工具、逐步筛选并精准锁定目标图片。
03 DeepImageSearch:
从看图识物到看懂你的人生剧情
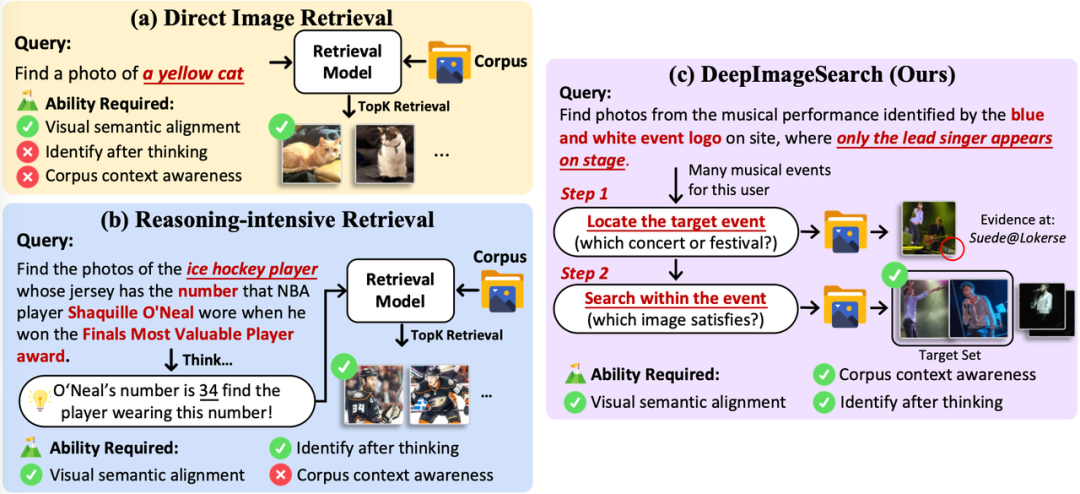
随着视觉-语言模型(VLM)基座的进步,现有检索系统已经可以通过跨模态语义对齐解决语义匹配的检索(如“脸上有黑点的猫”),或通过think-then-embed范式解决简单的推理检索(如“穿奥尼尔取得FMVP时球衣号码的冰球运动员照片”)。
然而,这些方法均基于“单图独立匹配”的核心假设,仅分析单张图片视觉内容,无法挖掘跨图片、跨事件的关联,面对依赖上下文线索的复杂查询完全失效。
DeepImageSearch的核心创新,在于彻底颠覆传统单图检索的底层逻辑,构建全局上下文感知的多步推理检索任务,让智能体能够像人类一样,基于完整视觉历史梳理事件脉络、串联分散线索,完成精准的深度检索,而非单纯的画面内容匹配。
区别于传统方法,DeepImageSearch聚焦语料库级上下文推理:目标图片往往无独特视觉特征,无法通过单图内容直接识别,需要依托关联图片的线索锚定事件范围,再分步筛选目标结果。例如针对“某次音乐节上,只有主唱一个人站在舞台上”的检索,需先通过包含logo的照片锁定对应演出事件,再在该事件范围内筛选目标图片,实现从“被动匹配”到“主动推理探索”的本质升级。
该范式不再将智能体视为单纯的检索工具,而是打造能够理解个人视觉叙事逻辑的智能助手,实现对时间、空间、事件因果的全面感知,真正适配个人相册的深度检索与视觉记忆挖掘需求。
04 DISBench:
面向多步推理的图库评测基准
为了推动这一新范式的研究,团队构建了首个具有高度挑战性的评测基准 DISBench(DeepImageSearch-Bench)。该基准覆盖 57 位用户、近 11 万张照片,平均每位用户的视觉历史跨度长达 3.4 年。
DISBench 的构建包含以下两个核心特点:
特点一:人机协同的隐性关联挖掘。 从数千张跨度数年的照片中发掘隐藏的关联(如“这座雕像在半年内的两次不同旅行中都被拍到了”)成本极高。为此,团队设计了一套自动化流水线:先由 VLM 解析视觉线索,再通过图谱构建自动挖掘不同事件间的隐藏关联,最后由人类专家进行严格的核验与质量把关,确保了数据构建的高效与高质量。
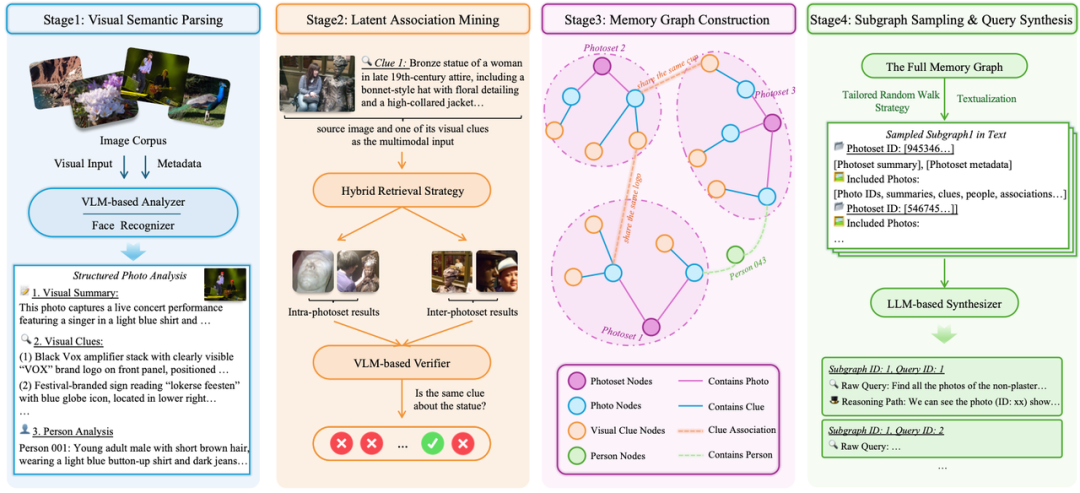
特点二:覆盖两类复杂推理场景。
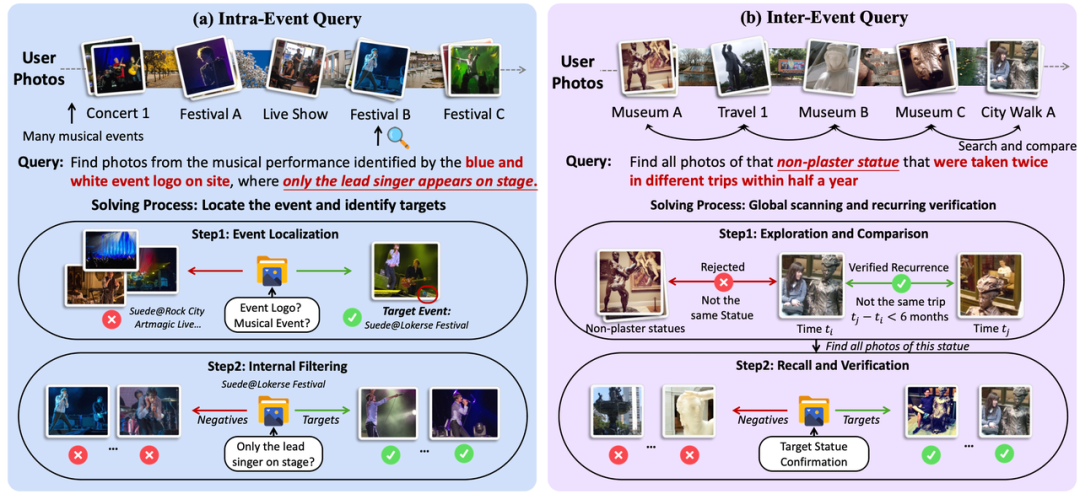
1. Intra-Event 查询(占 46.7%): 考察“先定位事件,再锁定目标”的能力。线索指向单一事件,目标隐藏在事件内部。
2. Inter-Event 查询(占 53.3%): 考察跨越整个相册的多段经历,理解事件间关联关系的能力。要求模型在全局扫描中核实时间或空间约束,召回全部相关照片。
05 ImageSeeker实验
为了系统性地探索“视觉历史深度搜索”所需的核心能力,团队设计了ImageSeeker智能体框架,聚焦解决深度检索中的长程推理、状态管理与工具协同问题,为后续研究提供标准化基线。其关键设计包含两个方面:
一、工具协同机制:该框架整合了语义检索(用自然语言在相册中搜图)、时空过滤(利用时间和地点的元数据筛选图片)、视觉确认(对照片进行细粒度观察)、以及外部知识补充(网络检索补充知识)四项关键工具。
二、双层记忆机制:该框架引入了“显式状态记忆”与“压缩上下文记忆”的双层记忆机制,一层是显式状态记忆,通过命名子集把中间发现持久化保存,确保多步探索中不丢失已有成果;另一层是压缩上下文记忆,在对话历史接近上限时,自动将其提炼为"全局目标"和"当前行动计划"两部分摘要,在有限的空间内尽可能保留关键推理状态。
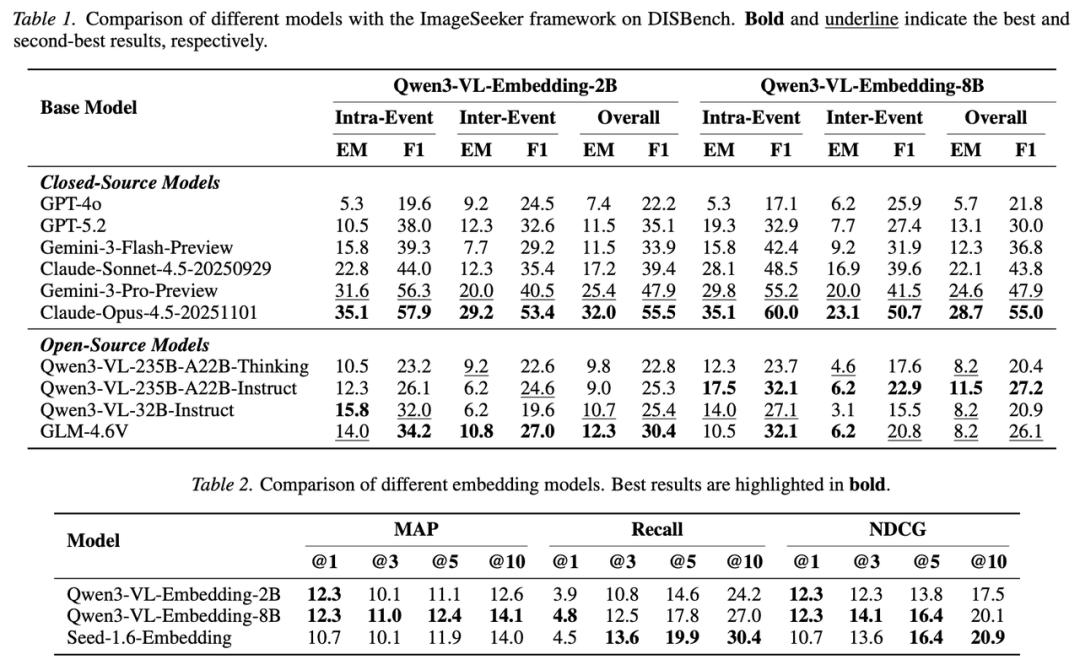
基于ImageSeeker框架,团队在DISBench上对当前主流的前沿多模态大模型(包括 GPT-5.2、Claude-Opus-4.5、Gemini-3-Pro 以及 Qwen3-VL、GLM-4.6V 等)进行了系统评测,得出了以下关键发现:
发现一:现有顶级多模态模型在长程视觉推理上存在显著短板。即使是表现最好的模型(Claude-Opus-4.5),准确率也仅约为 28.7%,开源模型中的最高准确率不超过12%。传统图像检索的 Embedding 模型在此任务中表现更是不尽如人意,验证了新范式的高门槛。
发现二:跨事件推理(Inter-Event)是当前核心瓶颈。强模型在单个事件内的搜索表现明显优于跨事件搜索(如 Claude-Opus-4.5 在跨事件任务中性能大幅衰减)。这表明,真正的技术分水岭在于长程的跨事件关联发现能力。
发现三:模型失误的主因在于规划与推理断链,而非纯视觉感知。通过对失败案例的人工归因分析,团队发现36% - 50%的错误源于推理出错。模型往往能找到正确的初期线索,但在执行多步计划的过程中遗失了约束条件或过早终止了探索,说明“推理规划”比“看清图片”更具挑战性。
发现四:Test-time Scaling展现出模型的潜在能力。Best@k 和 Majority Voting等机制能稳步提升模型的效果。这表明多模态大模型具备解决此类问题的潜力,如何通过更好的 Prompt 或架构设计释放其长程推理能力,是未来研究的重要方向。
06 结语
DeepImageSearch范式的提出,重新定义了个人视觉历史与相册检索的技术路径,将图像检索从单图语义匹配推向全局上下文推理的全新阶段,精准解决了传统方法无法挖掘相册关联线索的核心痛点。DISBench基准与ImageSeeker框架的发布,为该领域搭建了标准化研究体系,揭示了当前多模态模型的能力边界。
未来,依托更强的上下文感知与长程推理能力,个人相册检索将真正实现从工具到智能助手的升级,而相关技术的优化与突破,仍有待学界的持续探索。
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号