信息来源:数据工程与知识工程教育部重点实验室网站 发布日期:2025-06-25
近日,第51届International Conference on Very Large Databases(简称VLDB)最新一期的论文录用结果揭晓。截至目前,数据工程与知识工程教育部重点实验室共有9篇论文获得录用。以下是被录用论文的简要介绍。
研究方向一:数据管理
论文 1
A Hybrid Approach to Integrating Deterministic and Non-deterministic Concurrency Control in Database Systems
论文作者:洪殷昊,赵泓尧,卢卫,杜小勇,陈育兴,潘安群,郑礼雄
通讯作者:卢卫
论文简介:数据库并发控制是确保事务正确性和效率的核心关键技术。它主要分为确定性(Deterministic)与非确定性(Non-deterministic)两大类,各自在不同工作负载下展现出独特优势:确定性并发控制擅长处理高冲突和分布式场景,而非确定性并发控制则更适用于中低冲突和单机环境。因此,将两者融合以取长补短,是提升数据库系统整体性能的自然方向。
然而,将确定性与非确定性算法有效结合极具挑战:确定性并发控制算法通常依赖严格假设(如批处理、已知读写集),且机制与非确定性并发控制算法截然不同,保证混合后事务执行和故障恢复的正确性是困难的。而现有混合并发控制方法多集中于非确定性算法间的融合。已有的混合确定性和非确定性并发控制的工作未能充分发挥不同并发控制各自的性能优势。
为了突破这一瓶颈,本文提出了一种新的混合并发控制算法 HDCC。HDCC能够在同一数据库系统中自适应地结合确定性并发控制算法Calvin和非确定性并发控制算法OCC。为确保混合后事务的串行化执行和系统恢复的正确性,本文引入了锁共享(lock-sharing)、全局验证(global validation)和双日志交错(two-log-interleaving)等三项关键机制。此外,本文还设计了基于规则的分配机制,能够根据工作负载的特性为事务动态选择并发控制算法。
通过在TPC-C和YCSB基准测试上的实验验证,HDCC的性能显著优于现有混合方法,事务吞吐量提升最高可达3.1倍。HDCC为复杂多变的数据库工作负载提供了一种新的高效解决方案。
论文 2
Chimera: Mitigating Ownership Transfers in Multi-Primary
Shared-Storage Cloud-Native Databases
论文作者:黄纯悦,刘爽,张心怡,李文昊,卢卫,杜小勇
通讯作者:卢卫
论文简介:支持多写的共享存储云原生数据库系统,凭借其在写密集型负载场景下优于一写多读系统的卓越性能,成为工业界和学术界的研究热点。然而,随着共享数据占比不断攀升,此类系统的运行效率呈现显著下滑趋势。
本研究深入剖析发现,现有的多写系统均采用了“先来先服务”(First-come,first-served)的事务调度策略,造成了各个写节点间频繁的页面所有权转移,这是导致性能瓶颈的核心因素。为了解决这一问题,本研究提出了Chimera,一种新颖的支持多写的共享存储云原生数据库系统并着重优化了事务调度策略。
具体来说,Chimera通过引入两阶段事务调度机制,配合延迟获取所有权转移策略,有效减少了所有权转移的频率并显著提升系统的吞吐量。
在 SmallBank 和 TPC-C 基准测试下的大量实验证明,Chimera相较于现有的多写系统在吞吐量上实现了 1.86 倍至 19.03 倍的性能提升。该研究为当前支持多写的共享存储云原生数据库的研究技术路线开辟了一个新的视角,并展现出强大的性能优势和应用潜力。
论文 3
TxnSails: Achieving Serializable Transaction Scheduling with Self-Adaptive Isolation Level Selection
论文作者:庄琪钰, 卢卫, 刘爽, 陈育兴, 史心悦, 赵展浩, 孙羿鹏, 潘安群, 杜小勇
通讯作者:卢卫
论文简介:在要求100%数据正确性的关键任务(如金融交易、航空管制)中,数据库的可串行化隔离级别(SER)是黄金标准,但其高昂的性能成本一直是业界难题。我们观察到在应用负载中,事务查询通常遵循固定的模板,并且各个弱隔离级别下出现的数据异常也存在一定的规律特征。据此,我们提出了TxnSails,一种自适应隔离级别选择的可串行化技术,并且扩展了跨隔离级别可串行化理论体系。此外,TxnSails具有通用性且无需修改数据库内核,目前已支持PostgreSQL、MySQL及Neon数据库。TxnSails 的基础架构如图1所示,其中包括三项关键技术。
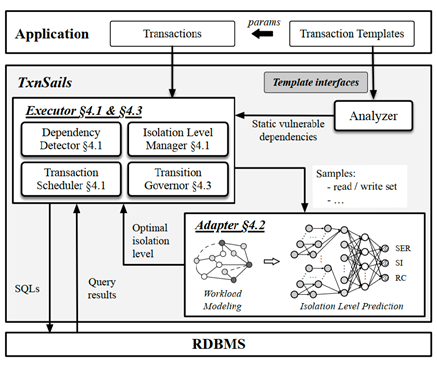
图1 TxnSails 的基础架构
首先,TxnSails分析了各个弱隔离级别下数据异常特征后,提出了统一的并发控制算法,通过动态追踪事务依赖,通过中间层验证锁确保提交顺序与依赖顺序一致;其次,TxnSails将OLTP工作负载建模,通过动态采样和深度学习模型实时预测最优隔离级别。最后,在最优隔离级别发生变化时(如SI→SER),TxnSails定义了跨隔离数据异常特征,同样通过严格控制依赖顺序和提交顺序的一致性,确保过渡期仍满足SER。
实验证明TxnSails在保证SER的同时,相比PostgreSQL原生的可串行化机制最高提升4.8倍,相比于其他对比工作实现最高26.7倍性能提升!
论文 4
Semantic Conformance Testing of Relational DBMS
论文作者:刘爽, 田承霖, 王瑞丰, 孙军, 卢卫, 赵涌鑫, 薛吟兴, 王俊杰, 杜小勇
通讯作者:卢卫
论文简介:关系型数据库管理系统(RDBMS)的开发应当遵循 SQL 标准。然而,目前尚无工具能够自动验证数据库实现与标准的符合性。造成这一现状的原因主要有两个方面:首先,SQL 标准规范是以自然语言编写的,具有一定的歧义性,且无法直接执行;其次,难以生成能够全面覆盖 SQL 规范中所有关键词和参数等方面的测试查询。在本研究中,我们提出了首个进行关系型数据库语义符合性测试的方法。我们的贡献包括三个方面:首先,形式化定义 SQL 的指称语义,并用 Prolog 实现,构建了一个符合标准的、可执行的参考数据库管理系统,用于与现有数据库系统进行差分测试;其次,基于该形式语义提出三种语义覆盖准则,并设计了一种基于覆盖的查询生成算法,能够有效生成具有高语义覆盖率的查询;最后,我们将该方法应用于六个广泛使用且测试充分的 RDBMS(如MySQL、PostgreSQL 和 OceanBase),共发现 19 个缺陷与13 个不一致行为,均已被相关数据库开发团队确认。
论文 5
Improving Time Series Data Compression in Apache IoTDB
论文作者:唐雨馨,张峰,官佳薇,田原,黄向东,王晨,王建民,杜小勇
通讯作者:张峰
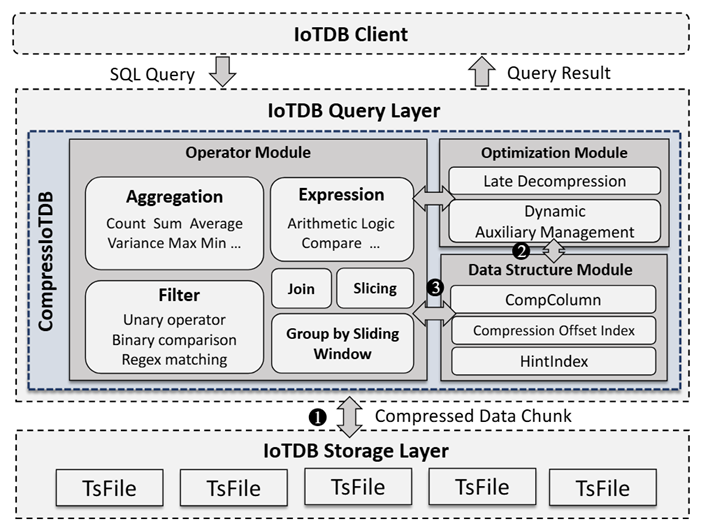
论文简介:随着物联网的发展,各领域产生的时间序列数据规模不断攀升。传统压缩技术虽然能有效节省存储,却往往需要查询前需要对数据进行完整解压,带来较高的延迟和资源消耗。已有压缩数据直接计算技术忽略了时序数据特性,不能有效地应对时序场景。对此,本文首次将同态压缩(HC)理论引入时间序列数据库,提出了一种在压缩态下直接执行查询的解决方案。基于此理论,我们在 Apache IoTDB 中设计并实现了 CompressIoTDB 框架。该框架通过模块化的时序数据压缩态内存数据结构设计,在不解压的情况下支持时间戳及值过滤、聚合计算以及各类滑动窗口统计等常见时序数据查询操作。与此同时,我们引入了延迟解压策略,仅在真正需要访问原始数值时才进行解压;并结合动态时序数据辅助结构管理机制,实时调整索引与缓存策略,以最大限度地降低 I/O 与内存开销。实验结果表明,CompressIoTDB 相较原生IoTDB平均提升查询吞吐量 53.4%,同时将内存使用降低 20%,在大规模场景下优势尤为明显。
论文 6
A Systematic Study on Early Stopping Metrics in HPO and the Implications of Uncertainty
论文作者:官佳薇,张峰,刘洁松,杜小勇,慎熙鹏
通讯作者:杜小勇
论文简介:本文系统研究了超参数优化(HPO)中早停准则的选取问题,首次引入不确定性视角进行量化分析。论文揭示训练误差在早期阶段作为 early stopping metric 可优于验证误差,并进一步提出集成不确定性建模与阶段感知的早停指标,在多个 HPO/NAS 基准任务上显著提升了精度与效率,最多提升24.76%。研究对设计更可靠的HPO策略提供了理论指导与实证依据。
研究方向二:数据治理
论文 7
PBench: Workload Synthesizer with Real Statistics for Cloud Analytics Benchmarking
论文作者:周琰,刘春蔚,Bhuvan Urgaonkar,王郑乐,Magnus Mueller,张超,张松岳,Pascal Pfeil,Dominik Horn,刘正春,Davide Pagano,Tim Kraska,Samuel Madden,范举
通讯作者:张超、范举
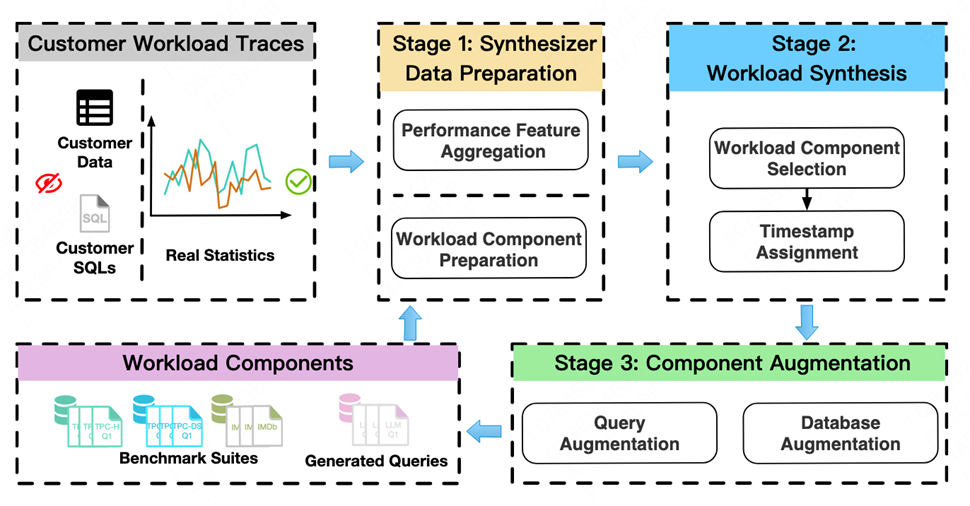
论文简介:云服务提供商通常使用TPC-H、TPC-DS等标准基准测试来评估和优化云数据分析系统。然而,这些基准测试依赖固定的查询模式,无法真实反映生产环境云工作负载的实际执行统计信息。尽管部分云数据库厂商近期公开了真实工作负载追踪数据,但这些数据本身并不能作为基准测试,因为它们通常缺失关键要素(如原始SQL查询语句及底层数据库)。为突破这一局限,本文提出了一种融合真实统计信息的工作负载合成新课题——通过生成合成工作负载,精准逼近真实云工作负载的核心性能指标与算子分布等执行统计特征。
针对该问题,我们开发了新型工作负载合成器PBench。它通过智能筛选与组合现有基准测试中的工作负载组件(即查询与数据库),构建高保真合成工作负载。本文重点研究了PBench面临的三大挑战:首先,我们提出基于多目标优化的组件选择方法,以平衡性能指标与算子分布的拟合精度;其次,为捕捉真实工作负载的时间动态特性,设计了可渐进优化时间戳的分配算法;最后,针对原始工作负载与候选组件间的差异性,创新性地采用大语言模型(LLMs)驱动的组件增强策略,在维持统计保真度的同时生成补充工作负载组件。基于真实云工作负载追踪数据的实验表明,PBench将近似误差最高降低至现有最优方法的1/6。
论文 8
AutoPrep: Natural Language Question-Aware Data Preparation with a Multi-Agent Framework
论文作者:范梅浩,范举,汤南,曹磊,李国良,杜小勇
通讯作者:范举
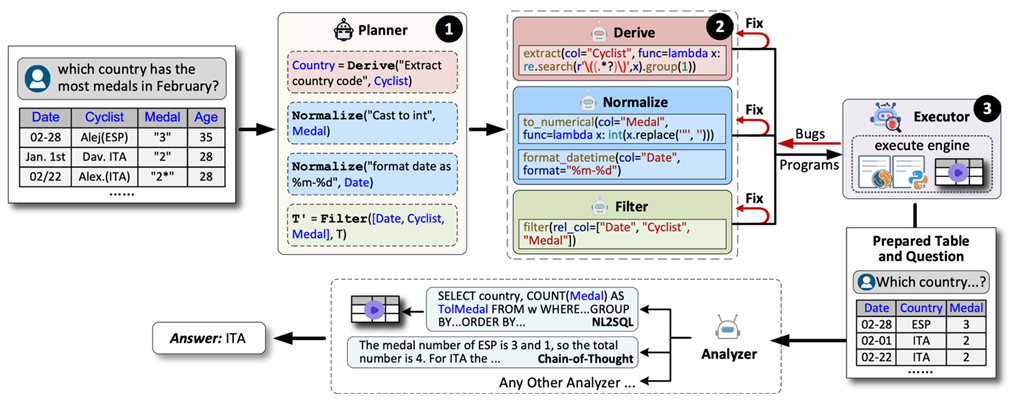
论文简介:表格问答(TQA)作为回答关于表格的自然语言(NL)问题的任务至关重要,因为它能让用户从结构化数据中快速高效地提取有价值的见解,有效架起人类语言与机器可读格式之间的桥梁。这些表格大多源自网络资源或真实场景,需要经过细致的数据准备(或数据预处理)以确保回答的准确性。然而,为自然语言问题准备此类表格引入了超越传统数据预处理的新要求。这种面向问题的数据准备涉及特定任务,例如针对特定问题定制的列派生与过滤,以及面向问题的数值规范化或转换,这凸显了在此情境下需要更精细方法的必要性。
由于上述每项任务都具有独特性,单一模型(或代理)可能无法在所有场景中均表现高效。本文提出 AutoPrep,这是一种基于大语言模型(LLM)的多代理框架,它利用多个代理的优势 —— 每个代理专门处理某类数据预处理任务,从而确保生成更准确且与上下文相关的回答。给定一个针对表格的自然语言问题,AutoPrep 通过三个关键组件执行数据预处理:
规划器:确定逻辑计划,勾勒出一系列高层次操作的顺序;
编程器:通过生成相应的低层次代码,将该逻辑计划转换为物理计划;
执行器:执行生成的代码以处理表格。
为支持这一多代理框架,我们设计了一种用于高层次操作建议的新型 “子句链” 推理机制,以及一种用于低层次代码生成的工具增强方法。在真实表格问答数据集上进行的大量实验表明,AutoPrep 通过面向问题的数据预处理,能够显著提升当前最先进的表格问答解决方案的性能。
研究方向三:数据智能
论文 9
Decentralized Actor Scheduling and Reference-based Storage in Xorbits: a Native Scalable Data Science Engine
论文作者:鲁蔚征,惠超,汪云海,张峰,陈跃国,刘宝,李成杰,吴昭欣,秦续业
通讯作者:陈跃国
论文简介:在数据科学领域,处理大规模数据并维持与流行单机库(如 pandas)兼容的 API,对任务调度和数据存储管理提出了极高要求。现有的系统在调度任务和细粒度的中间数据管理方面存在不足。为此,中国人民大学、山东大学与 Xorbits 公司的研究团队联合在 VLDB 上发表论文,提出了基于去中心化 Actor 模型(Xoscar)的可扩展数据科学引擎,为数据科学工作负载的扩展提供了创新解决方案。
传统数据科学流水线涉及数据加载、预处理、转换和分析等环节。当工作负载规模扩大时,现有系统如 Dask、Modin on Ray 等依赖集中式调度器协调任务执行,易形成系统瓶颈;而 Ray 的对象级数据 API 无法满足如 groupby 等操作对细粒度数据 shuffling 的需求,导致内存管理低效、数据倾斜等问题。例如,在分布式环境下执行 groupby.agg 操作时,Modin on Ray 因粗粒度存储管理导致内存失衡,甚至无法完成任务,而 Dask 则因调度效率低下出现显著的工作节点空闲。
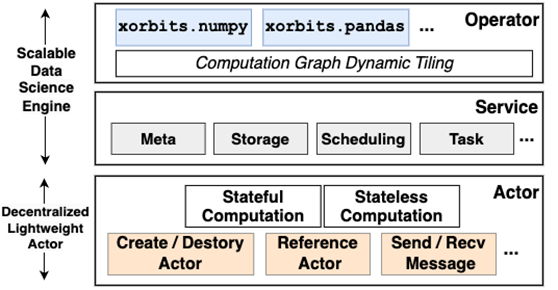
研究团队从底层涉及分布式执行引擎,通过两大核心技术突破现有瓶颈:
(1)去中心化 Actor 调度模型 Xoscar
Xoscar 采用基于 IP 地址的 Actor 创建与引用机制,无需全局调度器即可实现高效任务分配。通过最近公共后继增强的广度优先搜索(BFS)算法,将任务图中的节点分配至相同或邻近的计算节点,最大化数据局部性。实验表明,Xoscar 的任务调度速度比 Ray 快 8 倍,有效避免了集中式调度的性能瓶颈。
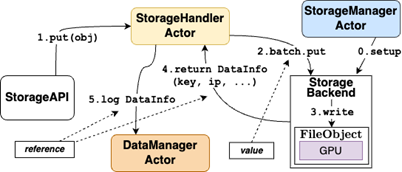
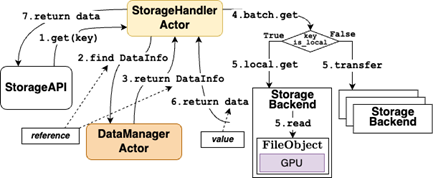
(2)基于引用的分布式存储系统
设计统一的文件句柄式 I/O 接口,将内存、GPU、磁盘等异构存储资源抽象为文件对象,通过键值对上下文(Key-Value Context)实现细粒度数据管理。数据块以唯一键标识,通过 DataInfo 这一元数据管理数据结构,管理数据块的存储位置与生命周期,支持无冗余的数据传输与自动垃圾回收。在 GPU 和磁盘场景下,该机制显著提升了数据访问效率与系统可靠性,例如在 TPC-H SF1000 基准测试中,Xorbits 成功完成所有查询,而 Dask 和 PySpark 均出现失败。
主要作者

洪殷昊
中国人民大学信息学院2018级直博生,计算机应用技术专业,导师为杜小勇教授和卢卫教授,主要研究方向是确定性并发控制。

黄纯悦
中国人民大学信息学院2023级硕士研究生,计算机应用技术专业,导师为卢卫教授。主要研究方向为云原生数据库系统和分布式数据库系统。

庄琪钰
中国人民大学信息学院2022级直博生,研究方向主要为事务处理和云数据库系统,导师是杜小勇教授和卢卫教授。

刘爽
中国人民大学吴玉章青年学者,副教授。中国计算机学会系统软件专委、数据库专委执行委员,在新加坡国立大学获得博士学位。从事数据库测试、复杂系统测试、大模型测试等相关方向的研究工作。在相关领域国际会议及期刊PVLDB, ICDE, ISSTA, ESEC/FSE, ASE, ICSE, FM, USENIX Security, TSE, TOSEM, 软件学报等发表论文60余篇(其中CCF A类论文30余篇),并获得ESEC/FSE 2020 (CCF A) 最佳论文奖。主讲编译原理(荣誉课程)、软件工程等多门计算机专业核心课程。担任多个会议程序委员会委员和期刊审稿人。主持包括自科面上、青年项目,CCF-蚂蚁联合基金等在内的多项项目。

唐雨馨
中国人民大学信息学院2024级硕士生,计算机应用技术专业,导师为张峰教授,主要研究方向是数据库压缩与高性能计算。

官佳薇
中国人民大学信息学院2022级博士研究生,计算机应用技术专业,研究方向为数据压缩、高性能机器学习与实时AI。

周琰
中国人民大学信息学院应届毕业硕士生,师从范举教授。其研究方向聚焦于 AI4DB(人工智能赋能数据库),尤其致力于数据库工作负载合成相关研究。目前,他正专注于研究更具可用性的云数据库上的基准测试。

范梅浩
中国人民大学信息学院博士生,师从范举教授。其研究方向聚焦于 AI4DB(人工智能赋能数据库),尤其致力于开发面向数据预处理的数据学习算法与系统。目前,他正专注于提升大语言模型(LLMs)对表格数据的理解能力。

鲁蔚征
中国人民大学大型科学仪器共享平台高级实验师,信息学院博士研究生,主要研究方向为高性能计算、数据科学。
通讯作者

杜小勇
中国人民大学数据库团队负责人,吴玉章讲席教授,明理书院首任院长,中国计算机学会(CCF)会士,数据工程与知识工程教育部重点实验室主任。曾先后担任中国计算机学会大数据专委会主任、教育工委主任、数据库专委会主任、国家云计算与大数据重点研发计划专家组成员、教育部科技委信息学部委员等。他长期从事数据库与大数据系统的研究工作,主持承担国家重点研发计划项目、国家自然科学基金重点和面上项目等多个国家级科研项目,在国际顶级会议和学术期刊上发表学术论文300余篇,其成果获国家科学技术进步奖二等奖、教育部科学技术进步奖一等奖(2次)、北京市科学技术奖一等奖等诸多奖项。

卢卫
中国人民大学吴玉章特聘教授,博士生导师,人大-腾讯协同创新实验室执行主任。近年来主要从事数据库基础理论、分布式数据库系统、数据治理等相关领域研究,在SIGMOD、VLDB、VLDB J等国际知名会议和期刊上发表论文60余篇,曾主持国家重点研发计划课题、国家自然科学基金面上、北京市重大专项课题等多个国家级或省部级项目。曾获北京市高等教育教学成果一等奖、深圳市科技进步一等奖、首届华为云难题“火花奖”、微软亚洲研究院青年教师铸星计划、中国计算机学会优秀博士学位论文奖。

张峰
中国人民大学吴玉章青年学者,教授、博士生导师。国家优秀青年科学基金获得者。在数据库系统与计算机系统结构交叉领域开展同态压缩数据库研究,发表CCF A类论文50余篇,获北京市科技新星等奖励。

范举
中国人民大学教授、博士生导师,国家级青年人才,中国计算机学会数据库专委会、大数据专委会执行委员。 研究方向包括:Data+AI技术与系统、数据治理技术、大数据分析等。 相关研究成果在数据领域顶级期刊/会议上发表论文60余篇。 作为负责人先后主持国家自然科学基金优秀青年基金项目、重点项目、面上项目,以及多项产学研合作项目。 先后获得ACM SIGMOD Research Highlight Award、ACM China Rising Award、宝钢优秀教师等奖励。

张超
中国人民大学信息学院讲师、青年英才、玉兰学者。芬兰赫尔辛基大学博士毕业, 清华大学博士后,他作为项目负责人先后承担国家重点研发计划子课题、 CCF-华为胡杨林挑战基金项目、CCF-腾讯犀牛鸟项目、达梦产学研项目等。研究方向为数据库系统,相关研究成果在数据库领域期刊/会议上发表论文20余篇,他在 HTAP 查询优化方面的研究成果落地 GaussDB 数据库内核,荣获 2025 ICDE Best Paper Runner-Up Award,华为火花奖等奖励。

陈跃国
中国人民大学信息学院教授、博士生导师,中国人民大学大型科学仪器共享平台副主任、国家治理大数据和人工智能创新平台执行主任,中国计算机学会数据库专委会秘书长。主要从事金融科技、智能制造、可信数据科学等方面的研究工作,在SIGMOD、VLDB、SIGIR、WWW、ICDE、AAAI、TKDE等国内外学术期刊和学术会议上发表论文40余篇,获得教育部科技进步一等奖一次。
VLDB会议简介
VLDB是数据库领域的顶级国际会议,致力于展示和分享数据库管理系统和数据管理领域的最新研究成果。作为一年一度的重要学术盛会,VLDB在全球学术界和工业界享有很高的声誉,是中国计算机学会(CCF)推荐会议列表中的A类会议。2025年VLDB将于9月1日至9月5日在英国伦敦举行。
数据工程与知识工程教育部重点实验室简介
数据工程与知识工程教育部重点实验室是我国在该领域唯一的省部级重点实验室,由杜小勇教授担任主任。实验室依托计算机科学与技术、图书情报与档案管理两个国家重点一级学科,由信息学院与信息资源管理学院联合共建。实验室聚焦数据管理、数据治理与数据智能三大研究方向,开展面向国家重大需求的应用研究,取得了丰硕成果,获得包括国家科技进步奖、教育部科技进步奖在内的多项重要奖项。
Copyright ©2016 中国人民大学理工学科建设处 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号