信息来源:人大高瓴人工智能学院 发布日期:2026年2月6日 11:49
引言:拉低代码智能体训练门槛
智能体训练的主流任务,大致可以按环境交互强度与工程成本分两类:(1)轻环境:如检索(Search Agent)、简单代码执行,环境相对简单;(2)重环境:以软件工程(SWE Agent)和图形界面(GUI Agent)为代表,需要依赖完备的环境(如Docker),且长程训练难度大。我们针对第二类“重环境 + 长链路”的难题,提供了两块互补的解法:SWE-Master 打通 SWE Agent从数据合成、监督微调、强化学习到测试时扩展的完整后训练流程,并开放关键细节与技巧;SWE-World 则进一步使用世界模型模拟环境反馈,实现完全不依赖于 Docker 的完整后训练流程,从而显著降低 SWE Agent 训练门槛。
SWE-Master
端到端的软件工程智能体后训练流水线:把轨迹合成,数据筛选,监督微调,强化学习,测试时扩展以及推理工具能力增强整合为完整的方案。
1
研究动机
学术界软件工程智能体的研究相对较少,主要原因有两个:一是SWE数据的蒸馏与训练难度较大,每一条数据都需要配套的可执行镜像;二是缺乏系统化、完整的后训练流程作为研究指导。针对这一问题,我们发布了详细的后训练流程,旨在提供一套完整的工具和方法,披露SWE Agent的训练细节,推动SWE Agent领域的进一步探索与发展。
2
框架覆盖:从数据到训练到推理
SWE-Master 主线包括:
3
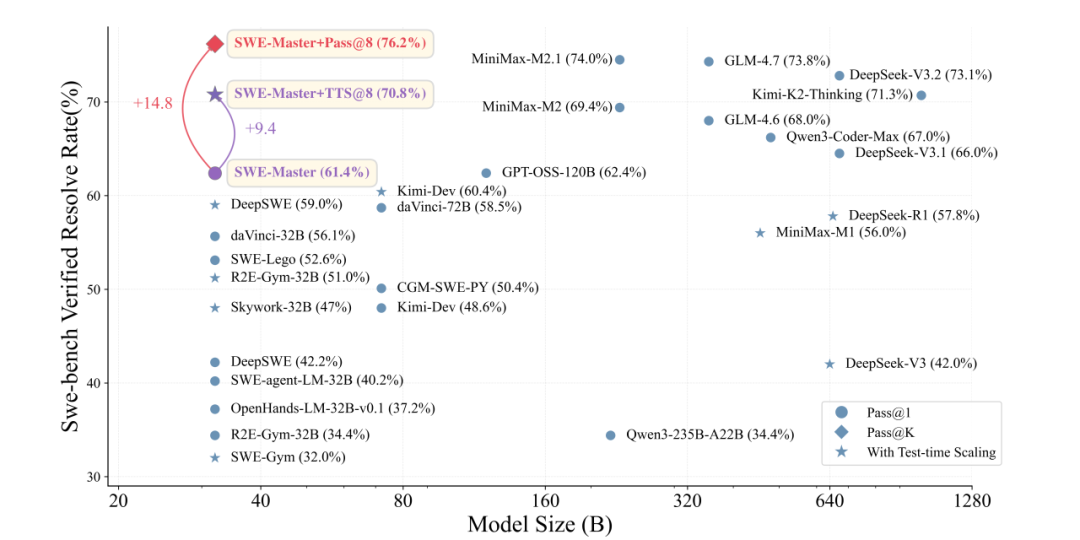
整体表现:开源代码智能体前沿
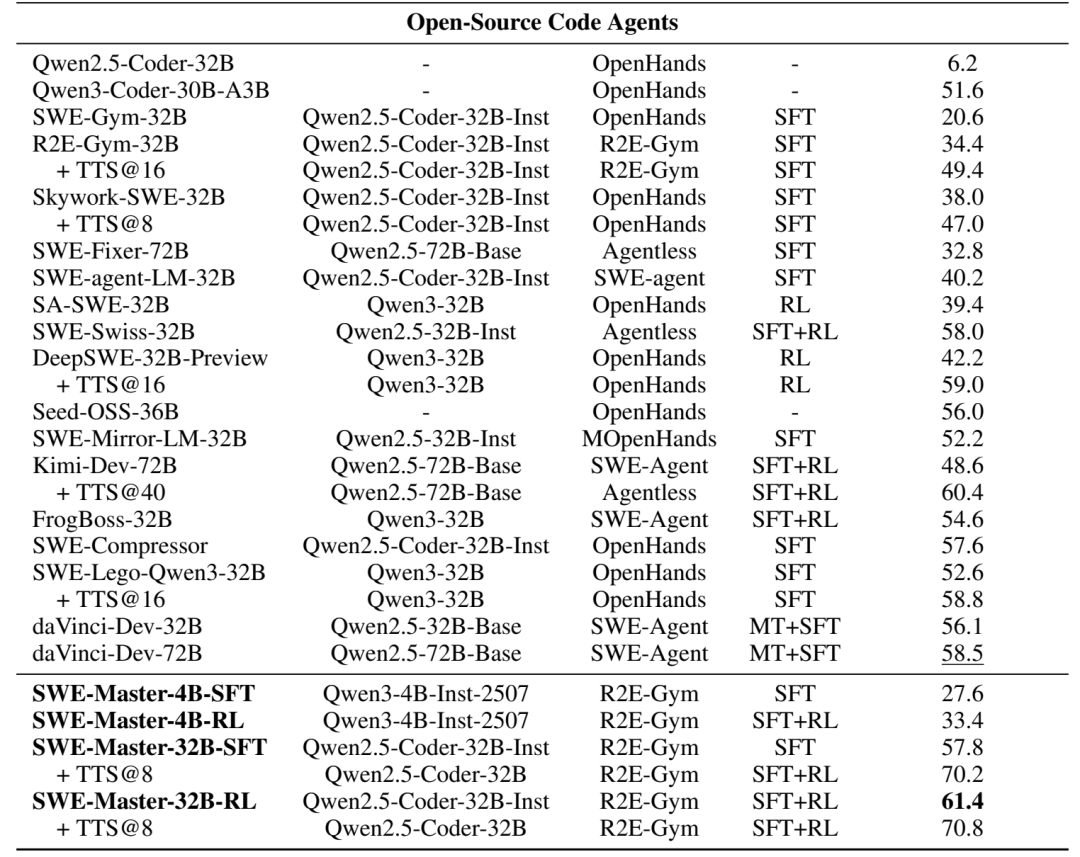
在 SWE-bench Verified 上,通过监督微调将Qwen2.5-Coder-32B的解决率从6.2%提高到56.8%,通过强化学习训练提升到61.4%,然后通过测试时拓展在TTS@8上达到了70.8%,达到了开源代码智能的前沿水平,同时可迁移到4B模型的训练上,同样取得了一定的收益。
4
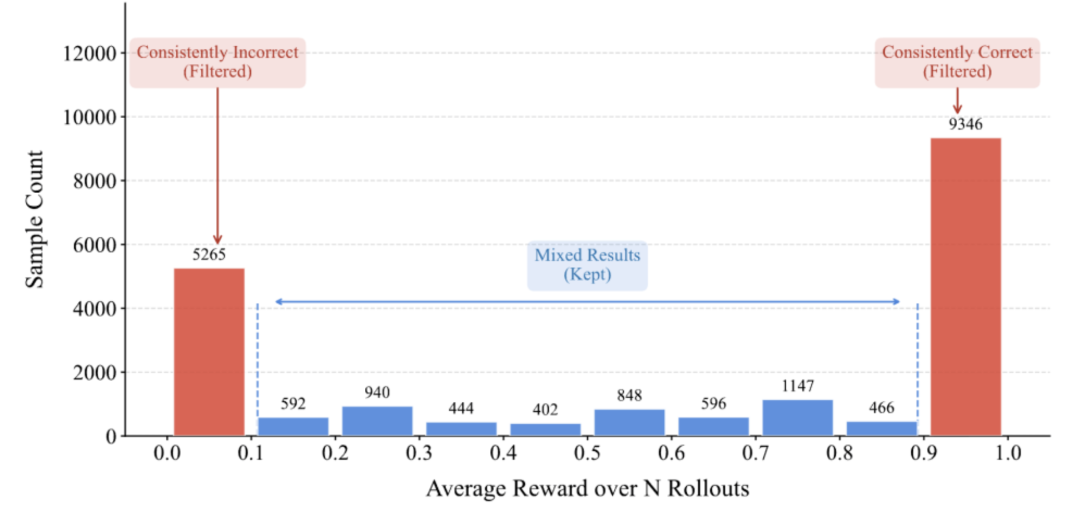
数据与筛选:基于平均奖励的任务难度估计
对开源数据集的issue进行精细的难度分级与筛选,对每个 issue 做 N 次生成,用平均解决率进行难度分级;观察到“容易/困难”两端分布较集中,因此在候选池中剔除极端样本,保留更有训练价值的中间区间。
5
强化学习训练:超长程任务的算法与奖励设计
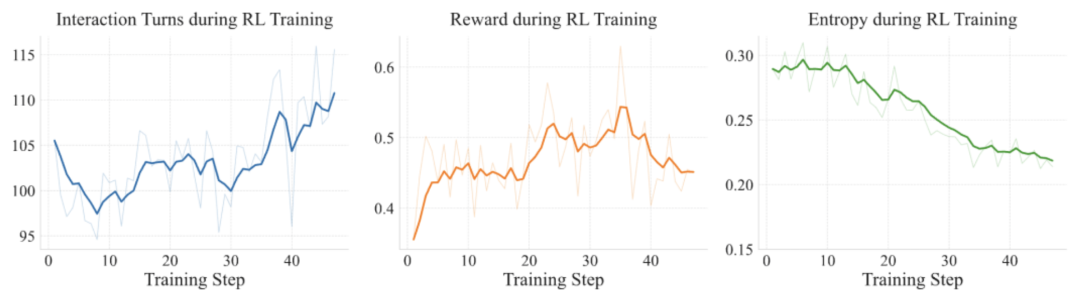
我们使用GRPO训练范式,参考先前优秀工作发现的经验性技巧(如clip-higher,留一法优势估计,缓解固有偏差)同时针对监督微调后的模型,我们发现标准的奖励设置会导致训练逐渐崩溃,所以我们针对不同的交互停止原因设计了不同的奖励和损失计算策略,保证了训练的稳定。
通过在强化学习过程中的训练动态可见,在训练中平均交互轮次稳步上升同时训练集奖励也呈现出整体上升的趋势。
6
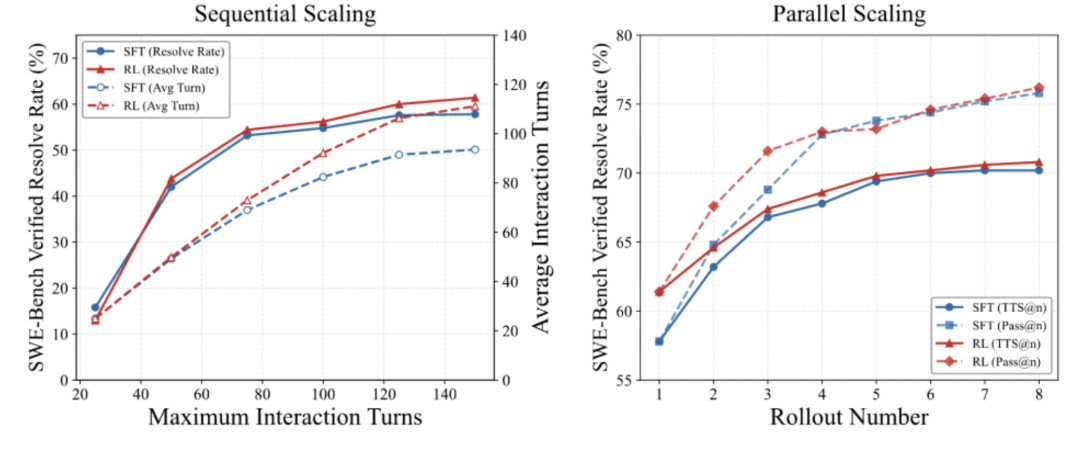
测试时拓展:测试SWE-Master的最终潜力
我们测试了串行和并行的测试时拓展策略,串行场景下,随着交互轮数的增大,SWE-Master的效果也在逐渐提升;并行场景下,会生成多条轨迹与补丁,然后用SWE-World进行模拟奖励计算,选择最佳提交,随着并行生成条数的增加,最终正确率也在增加,在TTS@8是达到70.8分。
7
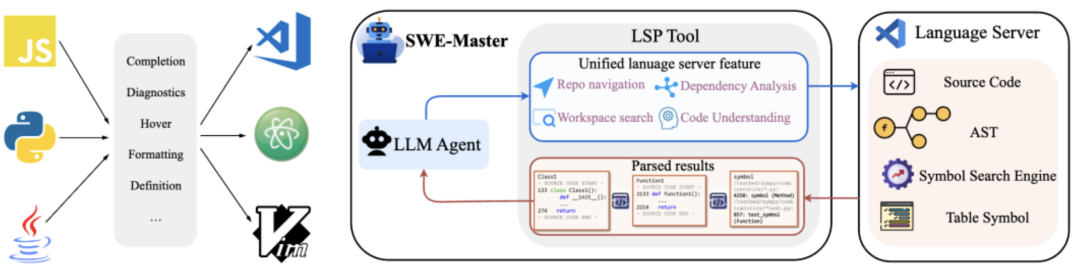
基于语言服务器协议的高阶能力接入
我们引入基于Language Server Protocol的高阶工具,把“跳转到定义、引用、符号解析”等 IDE 级语义能力封装成更确定、可控的工具接口,从而降低纯文本搜索的脆弱性,提高跨文件理解与导航效率。
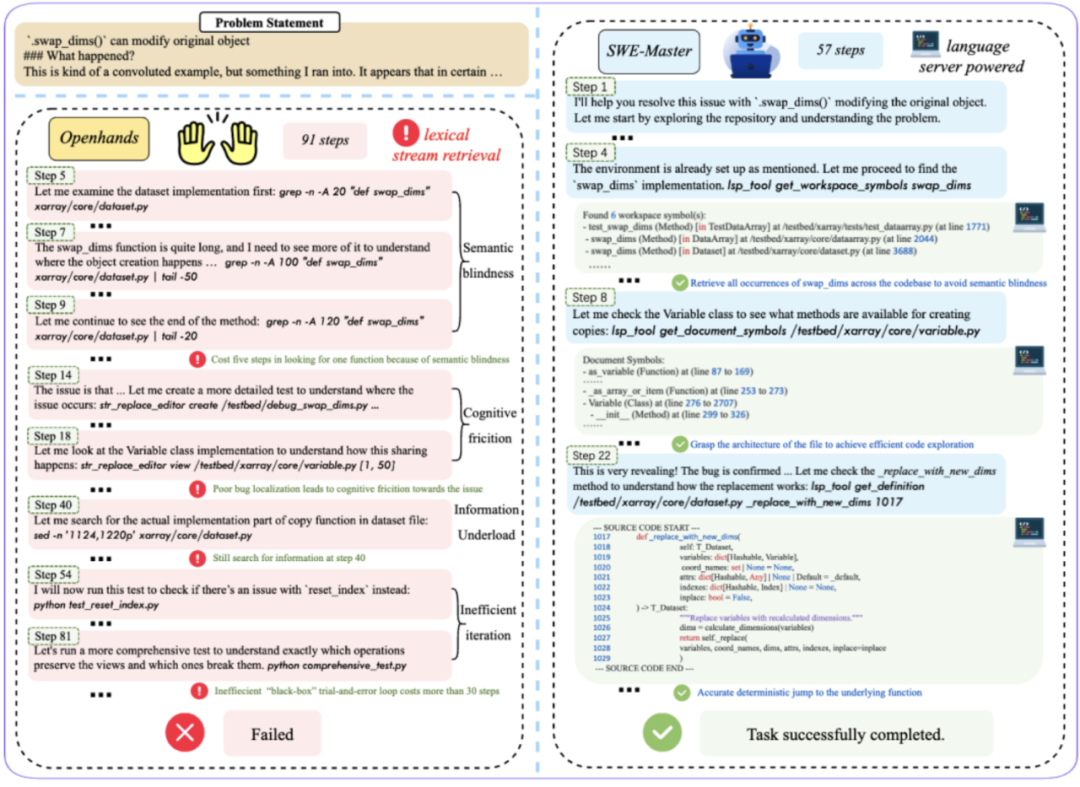
SWE-bench Verified中 的 pydata_xarray-6812的案例分析如下,对比展示 LSP 工具对轨迹质量的影响(详细分析请参见论文)。
SWE-World
1
研究动机:从根本上解决环境拓展问题
当前主流 SWE Agent 通常依赖 Docker 执行环境来获得执行反馈和评测结果。真实执行带来了较强的可信度,但也引入了现实瓶颈:环境构建昂贵、可扩展性差,尤其在大规模数据生成与后训练阶段会显著放大成本与工程负担。
我们希望在保持“智能体-环境-反馈”交互范式不变的前提下,用大语言模型模拟执行反馈与测试结果,从而实现完全 Docker-free 的数据生成、训练、测试时扩展。
2
SWE-World 架构:从推理到训练的全流程支持
SWE-World 把“环境能力”分解成三个部分,分别覆盖轻量操作、代码执行与最终评测:
Sandbox:处理轻量的文件导航与编辑操作;
SWT(Transition Model):模拟仓库级代码执行的单步反馈;
SWR(Reward Model):在轨迹结束时充当“虚拟测试运行器”,生成结构化测试报告并输出二值 reward。
3
基于 SWE-World 训练 SWE Agent
基于 SWE-World 的世界建模能力,我们实现了全流程的 Docker-free 训练:
数据准备:开源 SWE 数据集 + 新构建的 SWE-World Dataset。
Docker-free SFT:基于 SWE-World,使用教师智能体生成轨迹,结合规则与 SWR 过滤,进行 Agentic SFT。
Docker-free RL:基于 SFT 得到的模型初始化训练,基于SWT 提供单步反馈,SWR 提供奖励信号,进行 Agentic RL 。
Docker-free TTS:对每个问题采样多条候选轨迹,用 SWR 多次打分排序,提交最优的轨迹。
需要注意的是,从轨迹合成,到 RL 训练,整个过程均为 Docker-free 的。
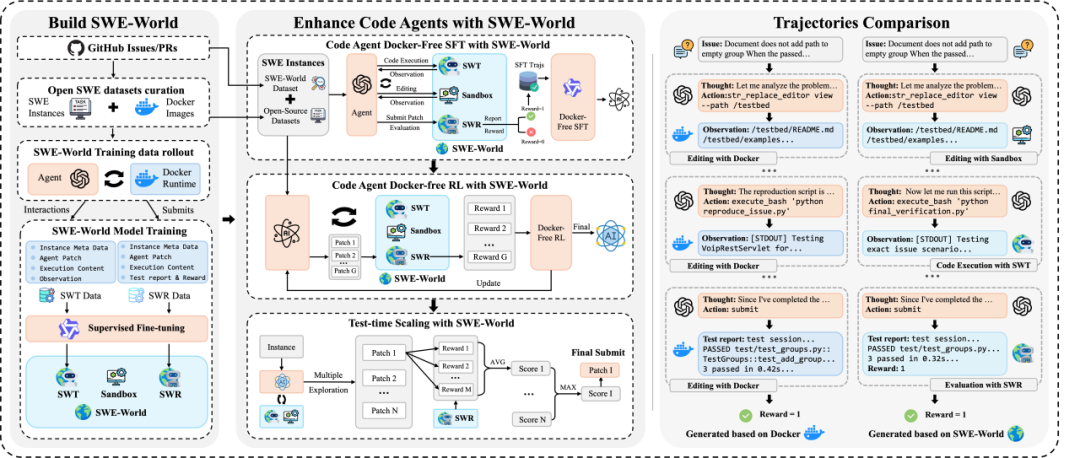
SWE-World 整体框架与训练流程
4
实验效果:环境模拟不输真实反馈
在 SWE-bench Verified 上:将 Qwen2.5-Coder-32B 从 6.2% 提升到 55.0%(Docker-free SFT+RL),并通过 TTS@8 达到 68.2%,远超相同尺寸的SWE Agent,验证了不依赖于Docker,基于SWE-World进行纯粹的环境模拟,仍然可以赋予模型软件工程问题求解能力。
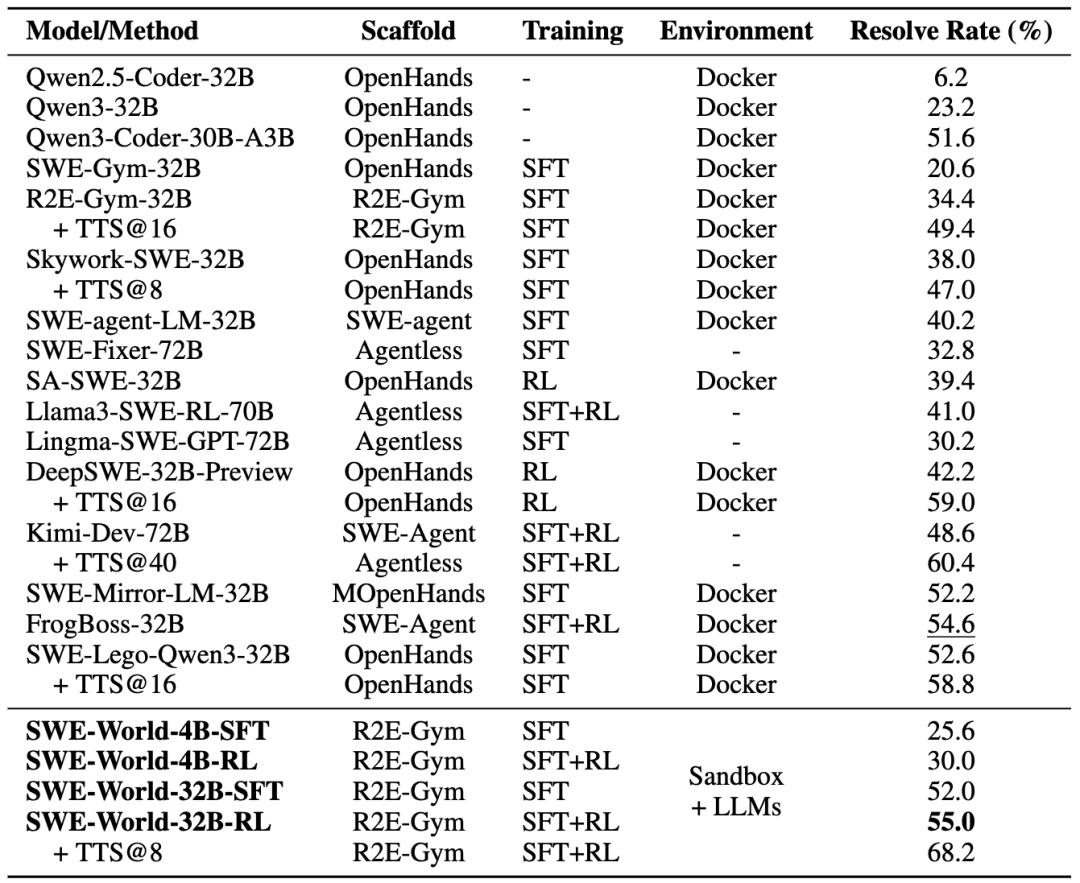
SWE-Bench Verified 评测结果
5
详细分析
RL 训练动态
在基于 SWE-World 的 RL 训练过程中,reward 随训练稳定上升,说明 SWE-World 能提供稳定且与目标一致的训练信号(SWT 的单步反馈 + SWR 的可验证奖励),从而支撑策略持续优化。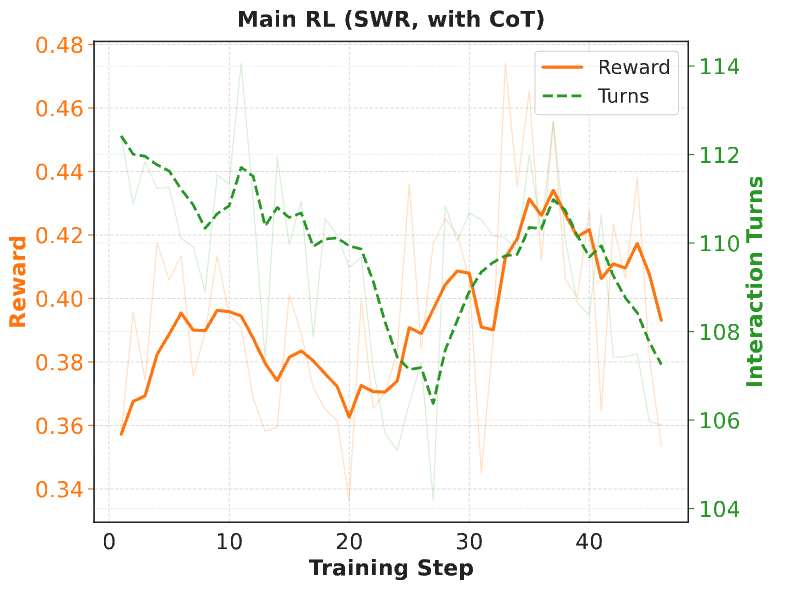
RL训练动态
测试时扩展
我们基于 SWR 进行测试时扩展;随着尝试次数增加,模型性能单调提升,且在同等设置下 SWR 的效果显著优于现有验证器,表明其能提供更精确、可扩展的选择信号。
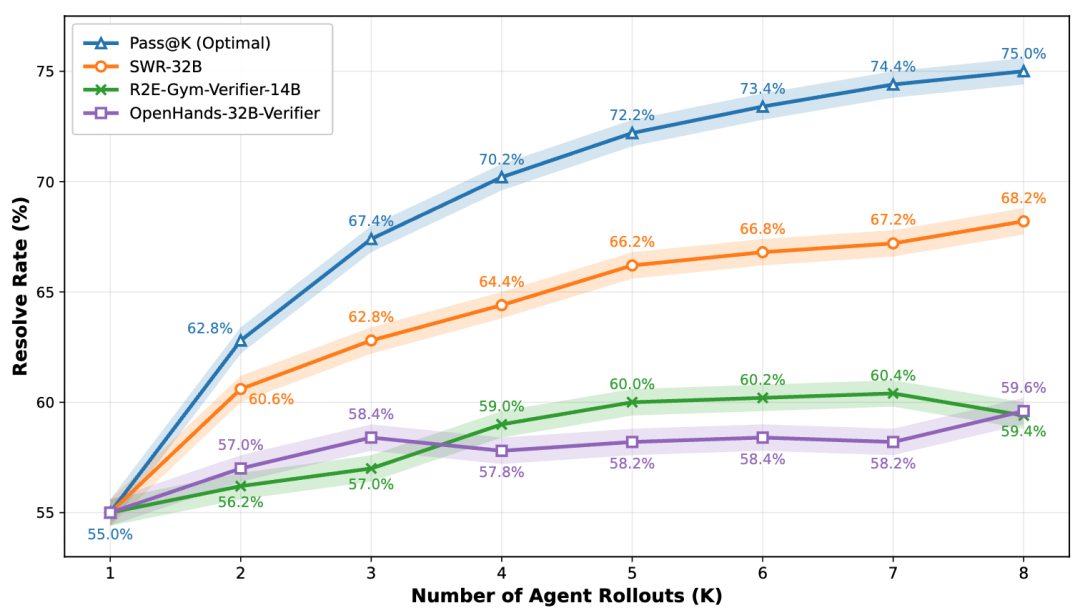
测试时扩展结果
SWT与SWR模拟样例
在相同上下文中,将SWR/SWR的模拟输出与真实输出对比表明,SWT 能近乎逐行复现执行反馈,SWR 可以生成与真实输出一致的评测结果,表明 SWE-World 的模拟反馈真实且可信。

SWT/SWR与真实输出对比
结语
SWE-Master 打通并公开了 SWE 智能体后训练的关键流程与技巧,SWE-World 则用可学习的环境反馈与测试验证摆脱 Docker 依赖、支撑规模化训练与测试时拓展。我们希望它们共同降低代码智能体的训练门槛,推动更多人参与代码智能体的研究与落地。
参与该成果的主要研发人员:
人大高瓴人工智能学院:宋华彤,孙爽,黄礼圣,蒋锦昊,吕智昊,赵鑫,许洪腾,文继荣
Boss直聘南北阁研究团队:乐然,陈宗超,贾一鸣,宋洋
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号