信息来源:人大高瓴人工智能学院 发布日期:2026年1月29日
近日,国际学术会议ICLR 2026论文接收结果公布。中国人民大学高瓴人工智能学院师生有39篇论文被录用。ICLR,全称为「International Conference on Learning Representations」(国际学习表征会议),被认为是深度学习领域的顶级国际会议之一,与 NeurIPS、ICML 并称为机器学习领域三大顶会。ICLR 2026将于4月23日至27日在巴西里约热内卢举行,会议将呈现和发布深度学习领域前沿研究成果。
论文介绍
论文题目:Prompt and Parameter Co-Optimization for Large Language Models
作者:薄小荷,李锐,孙泽旭,戴全宇,张泽宇,田子杭,陈旭,董振华
通讯作者:陈旭
论文概述:提示优化和微调是提升大型语言模型性能的两种主要方法。它们从互补的角度增强LLM的能力:前者通过显式自然语言,后者通过隐式参数更新。然而,以往的研究通常将它们孤立地进行,导致它们的协同潜力尚未得到充分挖掘。为了弥补这一不足,本文提出了MetaTuner,一个将提示优化和微调相结合的新型框架,用于LLM的训练。具体来说,我们引入了两个神经网络分别生成提示和参数,并允许它们共享一个公共的底层编码层以实现知识共享。在最终监督信号的指导下,我们的框架经过优化,能够更好地发掘提示和参数之间的最佳组合。由于提示学习为离散优化问题,而参数微调为连续型优化,我们设计了一种监督正则化损失来有效地训练我们的框架。在各类基准中的大量实验证明了所提出方法的有效性。
论文介绍
论文题目:Evaluating Text Creativity across Diverse Domains: A Dataset and Large Language Model Evaluator
作者:曹乾,王希廷,袁玉琢,刘亚辉,骆方,宋睿华
通讯作者:王希廷,宋睿华
论文概述:针对大语言模型(LLM)创造力评估依赖高成本人工判断、现有自动化方法泛化性不足的问题,本文提出了一个新颖的成对比较评估框架,通过共享上下文指令提升评估一致性。我们构建了CreataSet,一个涵盖多领域、包含超10万条人类和100万条合成指令-响应对的大规模数据集,并在此基础上训练出基于LLM的评估器CrEval。实验表明,CrEval 在与人类判断的一致性方面超过多个强基线闭源和开源模型,体现出较强的跨领域泛化能力,验证了结合人类与合成数据训练稳健评估器的有效性,并展示了其在增强模型创意生成方面的应用潜力。
项目主页:https://creval-creative-evaluation.github.io
论文介绍
论文题目:JointAVBench: A Benchmark for Joint Audio-Visual Reasoning Evaluation
作者:晁姜晗,高剑章,谭文辉,孙宇冲,宋睿华,茹立云
通讯作者:宋睿华
论文概述:目前评估Omni-LLM理解视频能力的测试基准存在缺陷,因为很多问题只看画面或只听声音就能回答,无法真正考验AI的综合能力。为此,我们提出了一个全新的、更严格的基准 JointAVBench。它的核心特点是:所有问题都经过精心设计,必须同时结合视频画面和音频信息才能回答。测试结果表明,即便是当前最顶尖的模型,在这个新基准上的平均准确率也仅有 62.6%,暴露出Omni-LLM在真正的音视频联合理解方面还有很大的提升空间,尤其是在时序推理上表现不佳。
论文介绍
论文题目:IterResearch: Rethinking Long-Horizon Agents with Interaction Scaling
作者:陈国鑫,乔子乐,陈炫中,于东磊,许昊天,赵鑫,宋睿华,尹文彪,尹汇峰,张力文,李宽,廖敏鹏,蒋永,谢鹏俊,黄非,周靖人
通讯作者:赵鑫,宋睿华
论文概述:现有深度研究智能体受限于“单一上下文范式”,在长视距任务中深受上下文窒息与噪声污染之苦。为此,我们提出 IterResearch,一种利用工作区重构与演进报告机制取代传统线性累积的新型迭代范式,从而在任意探索深度下维持稳定的推理能力。配合新开发的效率感知策略优化(EAPO)框架,我们通过几何奖励折扣实现了高效且稳定的模型探索。实验结果显示,IterResearch 在六大基准测试中平均领先开源智能体 14.5%;尤为突破的是,它仅需 40k 上下文即可支持 2048+ 次交互(性能从 3.5% 激增至 42.5%),且作为通用提示策略,其表现比 ReAct 提升高达 19.2% 。
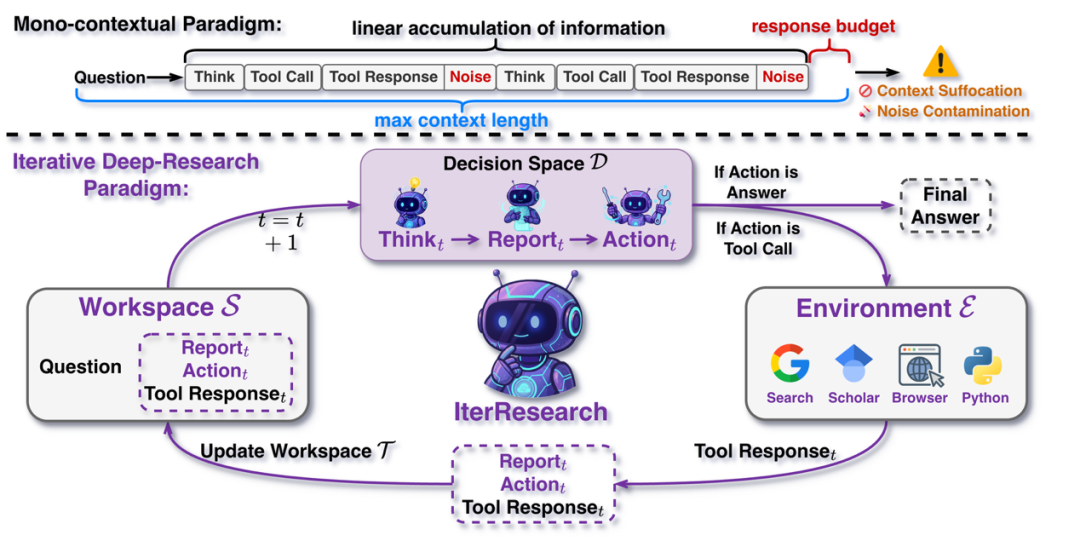
论文介绍
论文题目:ReForm: Reflective Autoformalization with Prospective Bounded Sequence Optimization
作者:陈国鑫,武静,陈欣杰,赵鑫,宋睿华,李承曦,樊楷,刘大一恒,廖敏鹏
通讯作者:赵鑫,宋睿华
论文概述:自动形式化是将自然语言数学问题转化为机器可验证语句的关键技术,但现有大语言模型因缺乏反思机制,常导致语义意图丢失 。为此,我们提出了 ReForm,一种通过集成语义一致性评估来实现迭代生成与自我修正的反思性方法 。为了有效训练该模型,我们引入了 PBSO(前瞻性有界序列优化),利用位置差异化奖励确保模型兼顾形式化准确性与验证质量 。实验表明,ReForm 在四个基准测试中平均超越最强基线 22.6% 。此外,我们构建了 ConsistencyCheck 基准,揭示了即使人类专家也存在高达 38.5% 的语义错误率,进一步验证了自动形式化任务的挑战性 。
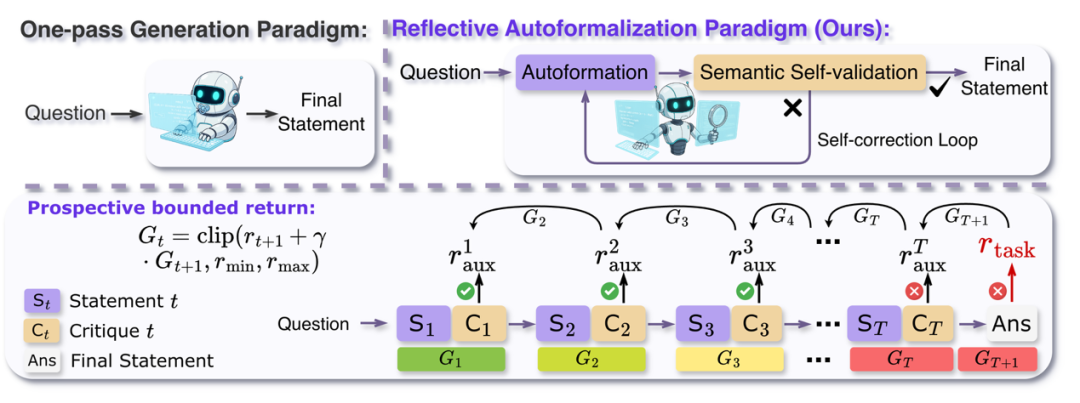
论文介绍
论文题目:Toward Effective Tool-Integrated Reasoning via Self-Evolved Preference Learning
作者:陈逸飞,董冠霆,窦志成
通讯作者:窦志成
论文概述:现有的工具集成推理(Tool-Integrated Reasoning, TIR)模型在实际应用中经常出现工具调用效率低下、工具调用不足、思维瘫痪等问题。为了解决这些痛点,我们首先从信息熵的视角重新审视了工具调用对推理过程的影响,总结出了信息熵与工具调用的关系。基于此,我们设计了Tool-Light框架。该框架包含数据增强以及多阶段训练两部分。我们设计了创新的熵引导采样策略以构建高质量的正负样本对,并在此基础上引入了包含监督微调和多轮自进化直接偏好优化(DPO)的训练范式。我们将数据采样和训练过程交替进行,这种设计能够让模型逐步学会高效优质推理轨迹的输出模式。实验结果显示,基于该框架训练的模型在10个数学推理与知识密集型数据集上均表现优异,显著提高了工具调用的效率与准确性,并有效抑制了冗余的思维过程。
论文介绍
论文题目:Harder Is Better: Boosting Mathematical Reasoning via Difficulty-Aware GRPO and Multi-Aspect Question Reformulation
作者:代彦琪,姬煜翔,张骁,王永,初祥祥,卢志武
通讯作者:卢志武,王永
论文概述:可验证奖励强化学习(RLVR)为提升大模型的数学推理能力提供了一种稳健的机制。然而,我们发现现有方法在算法和数据两个层面上,系统性地忽视了对高难度问题的关注,尽管这类问题对于完善模型尚未充分发展的能力至关重要。在算法层面,广泛使用的组相对策略优化方法(GRPO)存在一个隐含的不平衡问题:其策略更新幅度在面对更困难的问题时显著减小。在数据层面,现有的数据增强方法主要通过对问题进行重述来提升多样性,却未能系统性地提高问题本身的内在难度。为解决上述问题,我们提出了一个双重视角的 MathForge 框架,从算法与数据两个方面共同聚焦高难度问题,以提升数学推理能力。该框架由难度感知的组策略优化算法(Difficulty-Aware Group Policy Optimization,DGPO)和多视角问题重构策略(Multi-Aspect Question Reformulation,MQR)组成。具体而言,DGPO 首先通过难度平衡的组优势估计纠正 GRPO 中隐含的不平衡问题,并进一步通过难度感知的问题级加权机制优先优化更具挑战性的问题。与此同时,MQR 从多个维度对问题进行重构,在保持原始标准答案不变的前提下,有效提升问题难度。总体而言,MathForge 形成了一个协同增强的闭环:MQR 拓展了高难度数据空间,而 DGPO 则能够高效地从这些增强数据中进行学习。大量实验结果表明,MathForge 在多项数学推理任务上显著优于现有方法。
项目链接:https://github.com/AMAP-ML/MathForge
论文介绍
论文题目:Agentic Reinforced Policy Optimization
作者:董冠霆,毛航宇,马凯,鲍骊澄,陈逸飞,王中元,陈仲夏,杜佳振,汪辉阳,张富峥,周国睿,朱余韬,文继荣,窦志成
通讯作者:窦志成, 周国睿
论文概述:在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,大模型往往需要结合外部工具进行多轮交互,现有强化学习算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。为此,我们提出了全新的智能体强化学习算法ARPO,专为多轮交互型大模型智能体设计。 ARPO 首次发现模型在调用外部工具后会推理不确定性(高熵)显著增加的现象,并基于此引入了熵驱动的自适应 rollout 策略,增强对高熵工具调用步骤的探索。同时,通过引入优势归因估计,模型能够更有效地理解工具交互中各步骤的价值差异。在13个计算推理、知识推理和深度搜索等高难基准上,ARPO算法一致性取得卓越表现。值得注意的是,ARPO显著优于传统RL 算法的情况下,仅需要使用一半工具的调用预算,为多轮推理智能体的高效训练提供了可扩展的新方案。
论文介绍
论文题目:TetraGT: Tetrahedral Geometry-Driven Explicit Token Interactions with Graph Transformer for Molecular Representation Learning
作者:冯晋嘉,魏哲巍,王太峰,邱宗仰
通讯作者:魏哲巍
论文概述:能够完整捕捉键角和扭转角等几何参数的分子表示,对于准确预测酶催化活性、药物生物活性以及分子光谱特性等重要分子性质至关重要,这一点已被大量研究所证实。然而,现有的分子图表示学习方法仅通过原子和化学键的组合来间接表示分子几何参数,忽略了这些高阶几何结构之间的空间关系与相互作用。
本文提出了 TetraGT(Tetrahedral Geometry-Driven Explicit Token Interactions with Graph Transformer,四面体几何驱动的显式标记交互图Transformer),一种直接建模分子几何参数的新型架构。基于面角与二面角不等式的空间立体几何理论,TetraGT 首次将键角和扭转角显式表示为结构化标记,直接反映其在决定分子构象稳定性与性质中的内在作用。通过我们设计的空间四面体注意力机制,TetraGT 实现了结构标记之间高度选择性的直接通信。实验结果表明,TetraGT 在 PCQM4Mv2 和 OC20 IS2RE 基准测试上取得了优异性能。我们还将预训练的 TetraGT 模型应用于 QM9、PDBBind、Peptides 和 LIT-PCBA 等下游任务,证明了 TetraGT 在迁移学习场景中表现出色,并且随着分子规模的增大展现出良好的可扩展性。
论文介绍
论文题目:AnyTouch 2: General Optical Tactile Representation Learning For Dynamic Tactile Perception
作者:冯若轩,周宇轩,梅思宇,周东展,王鹏伟,崔少伟,方斌,姚国才,胡迪
通讯作者:胡迪
论文概述:现实世界中的接触丰富型操纵要求机器人能够感知时序触觉反馈、捕捉细微的表面形变,并推理物体特性与力动力学。尽管光学触觉传感器在提供此类丰富信息方面具有独特优势,但现有的触觉数据集和模型仍然有限。这些资源主要关注物体级别的属性(例如材质),而在很大程度上忽略了细粒度的时序动态。我们认为,推进动态触觉感知需要一个系统性的动态感知能力层次结构,以同时指导数据收集和模型设计。为了解决缺乏富含动态信息的触觉数据的问题,我们提出了ToucHD,一个大规模触觉数据集,涵盖触觉原子动作、真实世界操纵以及触觉-力配对数据。除规模庞大之外,ToucHD还建立了一个全面的动态数据生态系统,从数据角度显式支持层次化的感知能力。在此基础上,我们提出了AnyTouch 2,一个适用于多种光学触觉传感器的通用触觉表征学习框架,将物体级理解与细粒度、力敏感的动态感知相统一。该框架能够跨帧捕捉像素级和动作特定的形变,同时显式建模物理力动力学,从而从模型角度学习多层次的动态感知能力。我们在涵盖静态物体属性和动态物理属性的基准测试上评估了我们的模型,并在跨越多个动态感知能力层级的真实操纵任务上进行了评估——从基础的物体级理解到力敏感的灵巧操作。实验结果表明,该模型在不同传感器和任务上均表现出一致且优异的性能,凸显了其作为通用动态触觉感知模型的有效性。
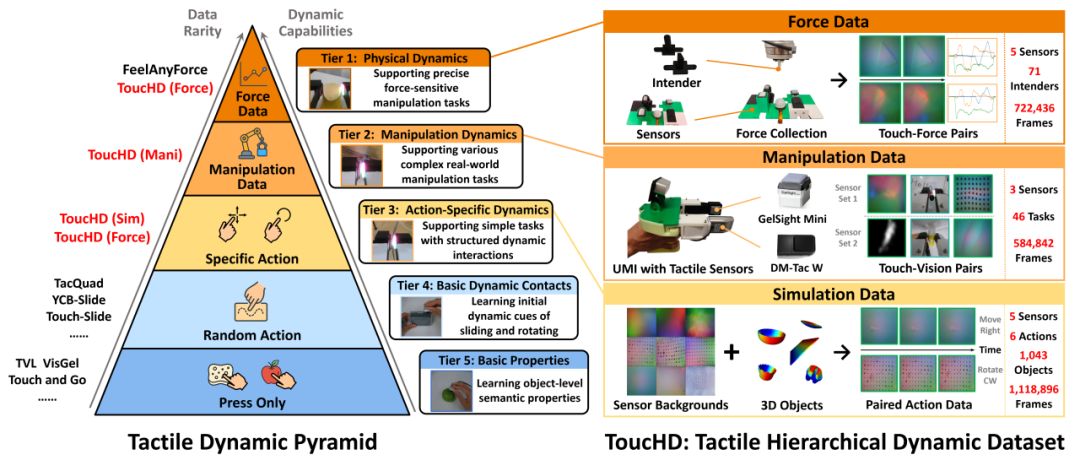
论文介绍
论文题目:Solving the Granularity Mismatch: Hierarchical Preference Learning for Long-Horizon LLM Agents
作者:高赫阳,孙泽旭,闵尔学,蔡恒毅,王帅强,殷大伟,陈旭
通讯作者:陈旭
论文概述:大语言模型作为自主智能体,正越来越多地被用于解决复杂的、长时程问题。通过基于偏好的方法(如直接偏好优化)对这些智能体进行对齐是一条很有前景的方向,但它面临一个关键的粒度不匹配问题:轨迹级 DPO 能提供稳定的学习信号,但在长轨迹中会模糊信用应当分配到哪里;而步级 DPO 虽能提供更细粒度的监督,却可能在蒙特卡罗回放展开受限时呈现统计噪声大、数据效率低等问题,并且难以充分利用那些只有经过多步动作后才显现效果的多步结构化行为。为权衡这一取舍,我们提出分层偏好学习(Hierarchical Preference Learning,HPL),这是一种分层框架,通过在多个相互协同的粒度上利用偏好信号来优化 LLM 智能体。HPL 同时结合轨迹级与步级 DPO,以获得全局与局部策略的稳定性;其核心创新在于:在双层课程学习的引导下进行组级偏好优化。具体而言,我们的方法首先将专家轨迹分解为语义连贯的动作组,然后生成对比性的次优动作组,从而在更细粒度的子任务层面开展偏好学习。随后,HPL 不再将所有偏好对一视同仁,而是引入课程调度器,将学习过程从简单组织到复杂。该课程沿两条轴来构建:动作组长度(表示子任务复杂度)与样本难度(由偏好与非偏好动作组之间的奖励差距定义)。在三个具有挑战性的智能体基准测试上的实验表明,HPL 优于现有的最先进方法。我们的分析进一步证明:分层 DPO 损失能够有效整合跨多种粒度的偏好信号,而双层课程机制对于使智能体覆盖从简单行为到复杂多步序列的广泛任务范围至关重要。
论文介绍
论文题目:Robustness in Text-Attributed Graph Learning: Insights, Trade-offs, and New Defenses
作者:雷润林,易璐,何明国,邱鹏宇,魏哲巍,刘永超,洪春涛
通讯作者:魏哲巍,刘永超
论文概述:文本属性图(Text-Attributed Graphs, TAGs)广泛存在于社交网络和引文网络等现实场景中,基于此的图神经网络(GNNs)与图大语言模型(GraphLLMs)已展现出强大的应用潜力。然而,针对这两类模型在TAGs上的鲁棒性研究仍显匮乏且呈现碎片化特征:早期GNN研究往往依赖浅层嵌入而忽视文本语义,而近期的GraphLLM研究则缺乏跨模型架构的系统性比较。这种割裂导致领域内对TAG鲁棒学习缺乏全面且深入的理解。
为填补这一空白,我们提出了首个统一的TAG鲁棒性评估框架。该框架涵盖四个领域的十个数据集,系统评估了经典GNN、鲁棒GNN(RGNNs)及GraphLLM在文本攻击、结构攻击及混合攻击下的表现。通过大规模实证分析,我们揭示了若干关键发现:(1) trade-off机制:模型往往难以兼顾文本与结构鲁棒性,防御一种攻击的优势通常伴随着对另一种攻击的脆弱性;(2) 重估经典方法:被低估的GNNGuard在结合先进文本编码器后,表现出令人瞩目的鲁棒性;(3) GraphLLM的短板:此类模型对训练数据污染(毒化攻击)表现出显著的脆弱性。
针对发现的trade-off,我们进一步提出了SFT-auto框架。该框架利用LLM的推理能力,实现了攻击检测与预测的统一。实验表明,SFT-auto是首个在文本和结构攻击下均能保持优越且均衡鲁棒性的模型。本研究不仅为TAG安全奠定了坚实基础,更为对抗环境下的鲁棒TAG学习提供了切实可行的解决方案。
论文介绍
论文题目:ReFusion: A Diffusion Large Language Model with Parallel Autoregressive Decoding
作者:李嘉楠,关健,武威,李崇轩
通讯作者:武威,李崇轩
论文概述:自回归模型受限于其缓慢的序列推理速度。尽管掩码扩散模型提供了一种并行生成的替代方案,但它们面临着严重的缺陷:一是由于无法利用键值缓存(KV Caching)而导致的高昂计算开销;二是因需要在难以处理的Token组合空间中学习依赖关系,导致生成内容缺乏连贯性。为了解决这些局限,我们提出了ReFusion。这是一种新颖的掩码扩散模型,它将序列重组机制融入到了因果注意力框架之中。通过将并行解码从 Token 粒度提升至更高阶的Slot粒度,ReFusion交替执行“Slot间扩散选择”与“Slot内自回归填充”;同时,在每次迭代后,将新生成的Slot重排序至剩余掩码Slot之前。这一设计不仅实现了对 KV 缓存的完全复用,还将学习复杂度从难以处理的 Token 组合空间降低至可控的Slot排列空间。在七个不同基准上的广泛实验表明,ReFusion表现卓越:它不仅以平均 34% 的性能提升和超过 18 倍的推理速度显著超越了现有的掩码扩散模型,更在保持平均 2.33 倍加速比的同时,成功弥合了与高性能自回归模型之间的性能差距。
论文介绍
论文题目:High Probability Bounds for Non-Convex Stochastic Optimization with Momentum
作者:李少杰,唐鹏威,朱博炜,刘勇
通讯作者:刘勇
论文概述:我们针对 SGDM 系统研究了高概率的收敛界与泛化界。首先,在一般非凸情形下,我们给出了梯度范数的高概率收敛界,其结果较现有理论更紧;并且据我们所知,这是首批针对 SGDM 的泛化界。其次,在满足 Polyak–Łojasiewicz(PL)条件时,我们进一步推导了函数值误差(而非梯度范数)的界,对应学习率快于一般非凸情形。最后,在此基础上再假设梯度满足温和的 Bernstein 条件,我们得到更尖锐的泛化界:在低噪声区间,学习率可达到 1/n^2(n 为样本量)。总体而言,我们系统刻画了非凸 SGDM 的高概率学习界。
论文介绍
论文题目:Unleashing Perception-Time Scaling to Multimodal Reasoning Models
作者:李依凡,陈正昊,伍梓衡,周昆,罗瑞璞 ,张粲,何祯涛,詹宇飞,赵鑫,邱明辉
通讯作者:赵鑫
论文概述:近年来,基于强化学习与可验证奖励的 Inference-Time Scaling 技术,显著提升了大型视觉语言模型(LVLMs)的推理能力。受此成功启发,类似策略已被应用于多模态推理,但其对模型视觉感知能力的影响仍未明晰。为探究这一差距,我们推出了以感知为中心的评测基准 DisTANCE,专门针对视觉估计任务。评估结果显示,现有 LVLMs 的估计精度有限,Inference-time Scaling 带来的改善也较为有限。我们将此归因于当前 LVLMs 普遍采用的“快速感知”范式——视觉理解被视为一次性输出,并未对其底层的感知过程进行建模。为解决此问题,我们提出了 Perception-Time Scaling (PTS) 这一全新范式。PTS 鼓励模型进行更丰富的感知表征,将复杂的感知问题分解为一系列可处理的中间子问题,从而使感知过程能够与 Inference-Time Scaling 对齐并从中受益。结合强化学习技术,PTS 显著提高了感知精度,将 DisTANCE 基准上的高精度表现从 8.0% 大幅提升至 64.7%,并在领域外任务中展现出良好的泛化能力。此外,尽管 PTS 的训练数据完全是合成的,将其与数学推理数据结合后,模型不仅在推理任务上获得提升,在真实世界的感知基准测试中也表现出一致的进步。进一步分析表明,PTS 引入了更多感知相关的表征,并增强了模型对图像信息的注意力。
论文介绍
论文题目:Reducing Symmetry Increase in Equivariant Neural Networks
作者:林宁,岑嘉诚,李安亿,黄文炳,孙浩
通讯作者:黄文炳,孙浩
论文概述:等变神经网络(Equivariant Neural Networks, ENNs)因其能够显式编码旋转、平移、置换等几何对称性,已在分子建模、物理仿真等科学计算任务中取得广泛成功。然而,本文指出 ENNs 存在一个常被忽视但会显著影响表达能力的现象:当输入本身具有对称性时,等变映射在输出端可能产生“对称性增加(symmetry increase)”——即网络输出的表示会对超过输入对称性的变换仍保持不变,从而造成信息折叠与可区分性下降(表现为表达能力退化)。
论文从数学本质出发,将该现象刻画为:对称输入经过等变映射后,其稳定子群(对称群)会扩大。针对以往工作多停留在个别案例观察、缺乏统一解释与可操作抑制策略的问题,本文给出系统的理论框架与可计算方法,核心贡献包括:1.下确界(infimum)理论刻画:在给定特征空间与输入对称群的条件下,作者证明“对称性增加”存在一个由特征空间结构决定的最小可能水平(下确界),从而回答“对称性增加最坏/最好能控制到什么程度”的基础问题。2.可计算算法与特征设计准则:在上述理论基础上,作者提出一个可计算的算法用于求解该下确界,并进一步给出具体的特征空间设计指南,用于在模型构造阶段避免有害的对称性增加(从源头提升表示可区分性)。3.“大多数等变映射”下的有效性保证:在标准正则性假设下,作者证明对于“几乎所有/大多数”满足条件的等变映射,遵循其特征设计准则能够显著降低对称性增加,具有一般性而非仅对特例成立。
最后,作者通过合成数据的可视化以及在真实分子数据集 QM9 上的实验验证了理论预言:对称性增加确实会导致表达受限,而按指南改造特征空间后能够有效缓解该问题并带来更合理的表示与性能表现。
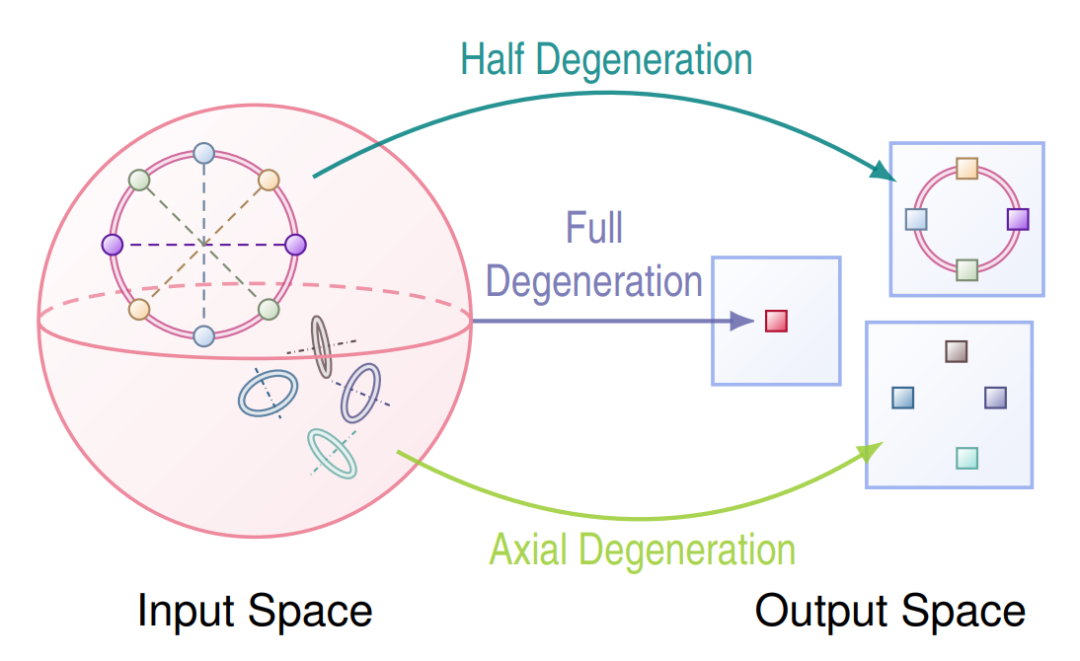
论文介绍
论文题目:An Efficient SE(p)-Invariant Transport Metric Driven by Polar Transport Discrepancy-based Representation
作者:林俊一*,薛敦耀*,虞俊,许洪腾,孟澄
通讯作者:许洪腾,孟澄
论文概述: 针对3D点云、高分子等具有平移/旋转对称性的结构性数据,现有SE(p)不变对齐方法通常需要显式求解几何对齐或引入复杂优化,导致计算开销高;另一部分方法虽高效,但往往缺乏严格的“度量”性质,从而限制其作为通用距离的理论与下游应用。为此,本文提出一种新的SE(p)不变传输度量 SEINT:通过构造无需训练的SE(p)不变表示,将高维结构信息压缩为可用于OT对齐的一维表征,从而在保持严格不变性的同时显著提升效率。理论上,SEINT被证明是定义在范数空间等距类上的严格度量,并天然支持跨空间分布比较;计算上可在 O(n log n) 到 O(n²) 的复杂度内完成对齐。大量实验验证其优势:作为度量,SEINT在等距变换下的分类与跨空间任务中表现稳健、优于现有SE(p)不变度量方法;作为生成模型的正则项,SEINT在分子生成的预训练与微调阶段均带来显著增益,并在多个关键基准上达到SOTA。
论文介绍
论文题目:DrugTrail: Explainable Drug Discovery via Structured Reasoning and Druggability‑Tailored Preference Optimization
作者:刘语柔,黎明洋,朱心远,矫瑞,董益铭,汤昕宇,刘洋,叶杰平,苏冰,王征
通讯作者:苏冰,王征
论文概述:机器学习在药物发现领域展现出极大潜力,然而,由于其“黑箱”特性,仍在一定程度上制约了其被领域专家的采纳程度。尽管大语言模型凭借其广博的知识储备与交互能力为相关问题提供了可行路径,现有方法仍存在数据依赖度高、推理过程缺乏透明性等不足。为应对上述挑战,本文提出 DrugTrail——一种基于 LLM 的可解释药物发现框架,该框架融合了结构化推理轨迹与面向药物可成药性的偏好优化策略。该方法不仅通过引入结构化推理链条明确阐释结论背后的“如何”与“为何”,同时在 LLM 的庞大知识空间中引导任务特定的推理路径,从而提升模型的可解释性与最终输出的可靠性。此外,鉴于单纯优化结合亲和力并不等同于优化药物可成药性,DTPO 策略明确突破单一指标优化的局限,拓展了兼顾亲和力与其他关键因素的更广阔搜索空间。大量实验结果表明,所提出的方法在提升性能的同时具有较强的跨领域泛化能力,可适用于更广谱的生物分子优化任务,有效弥合 LLM 推理能力与可信 AI 辅助药物发现之间的鸿沟。
论文介绍
论文题目:When Would Vision-Proprioception Policies Fail in Robotic Manipulation?
作者:卢镜先*,夏文科*,吴昱璇,卢志武,胡迪
通讯作者:胡迪
论文概述:本体感觉信息能够提供机器人状态的实时反馈,对精确的伺服控制至关重要。其与视觉信息的协同被普遍认为有助于提升机器人在复杂操纵任务中的策略性能。然而,近期研究在视觉–本体感觉策略的泛化能力方面报告了不一致的观察结果。本文通过时间上受控的实验对这一问题进行了系统研究。本文发现,在任务中的运动过渡子阶段(即需要进行目标定位的阶段),视觉–本体感觉策略中的视觉模态所发挥的作用是有限的。进一步分析表明,在训练过程中,策略会自然地倾向于依赖能够带来更快损失下降的、更加简洁的本体感觉信号,从而在优化过程中占据主导地位,并在运动过渡阶段抑制了视觉模态的学习。为缓解这一问题,本文提出了基于阶段引导的梯度调整算法(Gradient Adjustment with Phase-guidance,GAP),该方法通过自适应地调节本体感觉模态的优化过程,使视觉与本体感觉在策略中实现动态协同,从而促进更稳健且具有更强泛化能力的视觉–本体感觉策略学习。大量实验表明,GAP 不仅适用于仿真与真实世界环境,在单臂与双臂操纵任务中均表现稳定,而且能够兼容传统策略模型以及视觉–语言–动作模型。本文为机器人操纵中视觉–本体感觉策略的设计与发展提供了有价值的见解。
论文介绍
论文题目:FedMC: Federated Manifold Calibration
作者:马彦彪,戴威,姜高阳,陈万毅,周晨越,张艺炜,罗飞,王俊豪,张安迪
通讯作者:马彦彪,张安迪
论文概述:在联邦学习中,数据异构性长期被视为性能瓶颈。现有方法试图通过共享全局统计信息(如类中心或协方差)来“校准”本地训练,却普遍隐含一个危险的假设:数据分布是全局线性的。这一简化在真实世界中往往失效——高维数据实际栖息于低维非线性流形之上。当校准方向沿着欧氏空间中的“捷径”而非流形本身的“路径”进行时,生成的伪样本便悄然滑出数据分布之外,非但无法纠偏,反而系统性地误导模型。ICLR 2026 接收论文 FedMC 指出了这一被忽视的矛盾,并提出一个范式转变:放弃对全局线性的执念,转而让联邦系统学会“在流形上行走”。该工作首次将局部非线性几何引入联邦校准框架,在严格隐私约束下实现了上下文感知、流形内(on-manifold)的数据增强,为解决异构性问题建立了更真实、更稳健的几何基础。
论文介绍
论文题目:Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective
作者:欧竞阳,韩家琦,徐民凯,徐少轩,Jianwen Xie, Stefano Ermon,吴翼,李崇轩
通讯作者:吴翼,李崇轩
论文概述:强化学习在自回归语言模型中已被证明极为有效,但将这些方法直接迁移到扩散语言模型(dLLMs)中仍面临根本性挑战。其核心困难在于似然的计算方式:自回归模型天然提供逐 token 的条件概率分解,这是 token-level 强化学习目标(如 GRPO)所依赖的关键;而 dLLMs 通过迭代的非自回归去噪步骤生成文本,缺乏这种概率分解特性。为解决这一根本性不匹配问题,我们提出了ESPO(基于 ELBO 的序列级策略优化)。该方法将整个序列生成过程视为一次整体动作,并使用 ELBO 作为可计算的序列级似然近似,从而构建出一个原则性的强化学习框架。我们的方法结合了逐Token的权重比值归一化以及鲁棒的KL散度估计方法,以保证在大规模训练过程中的稳定性。在数学推理、代码生成与规划等多项任务上的大量实验表明,ESPO 相较于 token-level 方法具有显著优势:在 Countdown 任务上实现了 20–40 分的巨大性能提升,并在数学与编程基准上取得稳定增益。整体而言,我们的工作表明,序列级优化是一种在 dLLMs 强化学习中既具理论原则性、又具实证有效性的全新范式。
论文介绍
论文题目:GDGB: A Benchmark for Generative Dynamic Text-Attributed Graph Learning
作者:彭杰,季嘉蕊,雷润林,魏哲巍,刘永超,洪春涛
通讯作者:魏哲巍,刘永超
论文概述:近年来,生成式图学习正迅速成为人工智能领域的研究热点,尤其在推荐系统、社交网络建模、药物发现等场景中展现出巨大潜力。然而,当前主流动态图基准数据集普遍缺乏高质量文本信息,难以支撑生成式任务对结构动态演化与语义生成的联合建模需求。为应对这一挑战,我们提出 GDGB(Generative DyTAG Benchmark)——首个面向生成式文本动态图(DyTAG)的综合性基准。GDGB包含八个覆盖电商推荐、社交网络、电影合作网络、学术引文网络、人物生平等场景的高质量DyTAG数据集,其中源节点、目标节点和交互边均具备丰富且有语义信息的文本特征。在此基础上,我们定义了两类核心任务:直推式动态图生成(TDGG)与归纳式动态图生成(IDGG),分别面向固定节点集与更具挑战性的包含新节点生成的动态图生成场景,并配套设计融合结构、时序与文本质量的评估指标及基于LLM多智能体搭建的通用生成框架GAG-General。实验表明,GDGB 的提出为生成式动态图任务、生成式推荐系统等相关研究方向提供了统一、全面且具有挑战性的评测平台,有望推动图学习在生成式范式下的进一步研究与应用。
论文介绍
论文题目:ProtoTS: Learning Hierarchical Prototypes for Explainable Time Series Forecasting
作者:彭子恒,任世杰,顾心悦,杨林晓,王希廷,孙亮
通讯作者:王希廷,孙亮
论文概述:深度学习在时间序列预测任务中取得了亮眼的性能表现,而在高风险场景下,要建立对模型的信任,理解其决策过程就变得愈发关键。现有可解释性模型往往仅能提供局部、片面的解释,无法揭示异质且相互作用的输入变量如何共同塑造预测曲线中的整体时间模式。本文提出一种新型可解释性预测框架 ProtoTS,该框架通过对原型时间模式进行建模,同时实现了高预测精度与决策过程的透明化。ProtoTS 基于保留了丰富异质信息的去噪表征,计算样本与原型之间的相似度;并对原型进行层级化组织,通过粗粒度原型捕捉全局时间模式,同时借助细粒度原型刻画细粒度的局部变化特征,由此实现了专家可调控的多层次可解释性。在多个真实场景基准数据集(包括最新发布的 LOF 数据集)上的实验结果表明,ProtoTS 不仅在预测精度上优于现有方法,还能输出专家可调控的解释结果,助力研究人员更深入地理解模型,为实际决策提供支撑。
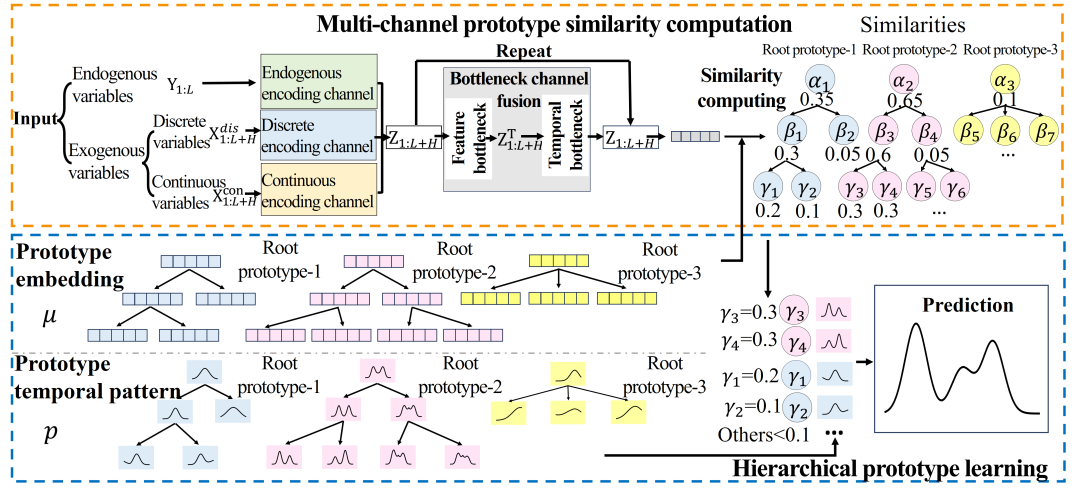
论文介绍
论文题目:Revisiting Matrix Sketching in Linear Bandits: Achieving Sublinear Regret via Dyadic Block Sketching
作者:文东勰,尹涵燕,张骁,赵鹏,张利军,魏哲巍
通讯作者:魏哲巍
论文概述:线性Bandit已经成为在线学习和顺序决策中的基石,为探索与利用的平衡提供了坚实的理论基础。在这一领域,矩阵略图技术是实现计算效率的关键,尤其是在处理高维问题时。通过略图近似方法,单轮计算复杂度从 $\Omega(d^2)$ 降到 $O(dl)$,其中 $d$ 是维度,$l < d$ 是略图大小。然而,这种计算效率带来了一个根本性问题:当数据流矩阵具有重谱尾时,现有算法可能会出现空洞的线性后悔。在本文中,我们重新审视了一系列基于矩阵略图的高效线性Bandit的后悔界限和算法设计,分析表明,不合适的略图大小可能会导致显著的谱误差,从而严重破坏后悔保证。
为了解决这一问题,我们提出了Dyadic Block Sketching,这是一种全新的多尺度矩阵略图方法,能够在学习过程中动态调整略图大小。我们将这一技术应用于线性Bandit,并证明该算法能够在不需要事先了解数据流矩阵特性的情况下,获得次线性后悔界限。该方法为高效的略图线性Bandit建立了一个通用框架,可以与任何提供协方差保证的矩阵略图方法结合使用。通过全面的实验评估,我们展示了该方法在效用与效率的平衡方面的卓越表现,证明了其在实际应用中的巨大潜力。
论文介绍
论文题目:StyliTruth: Unlocking Stylized yet Truthful LLM Generation via Disentangled Steering
作者:沈承磊, 孙忠祥, 石腾, 张骁, 徐君
通讯作者:张骁
论文概述:本论文关注面向LLM可控生成的表示编辑(representation editing)方法,聚焦风格化生成时的“真实性崩溃”(truthfulness collapse)问题。具体来说,当通过表示编辑来实现对LLM输出的风格化控制时,虽然可以有效地改变文本的风格,但往往会损害模型输出的真实性。例如,在将模型的输出风格改为莎士比亚风格时,模型可能会生成一些虽然符合莎士比亚风格但与事实不符的回答。这种现象被称为“风格化诱导的真实性崩溃”,即在追求风格化的同时,模型的核心真实性表示受到了干扰,导致回答的正确性降低。论文指出,这种现象的根本原因是风格和真实性在某些关键注意力头(attention heads)中的潜在耦合。在这些注意力头中,风格相关的激活差异和真实性相关的激活差异强烈纠缠在一起,使得在编辑风格时不可避免地会干扰到真实性的表示,从而导致真实性下降。为此,作者提出无需训练的推理期方法 StyliTruth:通过正交消隐(orthogonal deflation)将表示空间分解为风格相关子空间与真实性相关子空间,从而在各自子空间内进行独立、互不干扰的控制;并设计自适应的token级引导向量,动态精细地平衡风格一致性与真实性。实验覆盖多种风格与语言,结果表明 StyliTruth 能显著缓解真实性崩塌,并在“风格遵循—真实性”权衡上优于现有推理期干预方法。
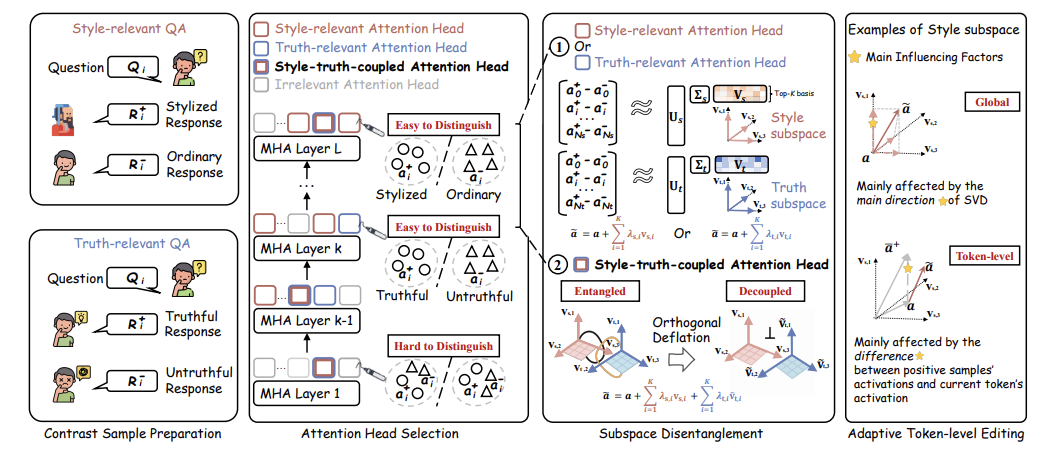
论文介绍
论文题目:Detection and Mitigation of Hallucination in Large
Reasoning Models: A Mechanistic Perspective
作者:孙忠祥,王启鹏,王浩喻,张骁,徐君
通讯作者:徐君
论文概述:大型推理模型(Large Reasoning Models,LRMs)在多步推理任务中展现出了令人瞩目的能力。然而,在这些成功背后,一种更具迷惑性的模型错误也逐渐显现——推理幻觉(Reasoning Hallucination)。这类错误表现为:模型生成的推理过程在逻辑结构上看似严密,却在事实层面存在错误,从而得出具有说服力但实则错误的结论。与传统幻觉不同,推理幻觉深度嵌入于结构化的推理链条之中,使其更难被识别,也可能带来更严重的风险。针对这一问题,本文从机制层面对推理幻觉展开系统研究。我们提出了推理得分(Reasoning Score),通过度量将大型推理模型后层投影到词表空间后所得到的 logits 之间的差异,来量化模型的推理深度,从而有效区分浅层的模式匹配行为与真正的深度推理过程。基于该推理得分,我们在 ReTruthQA 数据集上开展了深入分析,识别出两类关键的推理幻觉模式:一是推理早期阶段推理深度的剧烈波动,二是模型在推理过程中错误地回溯至存在缺陷的先前步骤。这些发现直接启发了我们提出的推理幻觉检测框架(Reasoning Hallucination Detection,RHD),该框架在多个领域的评测中均取得了当前最优的性能。在此基础上,为进一步缓解推理幻觉问题,我们提出了 GRPO-R,一种增强型强化学习算法。该方法通过基于势函数的奖励塑形(potential-based shaping),在训练过程中引入逐步级别的深度推理奖励。理论分析表明,GRPO-R 具备更强的泛化保证,实验结果也验证了其能够显著提升推理质量,并有效降低推理幻觉的发生率。
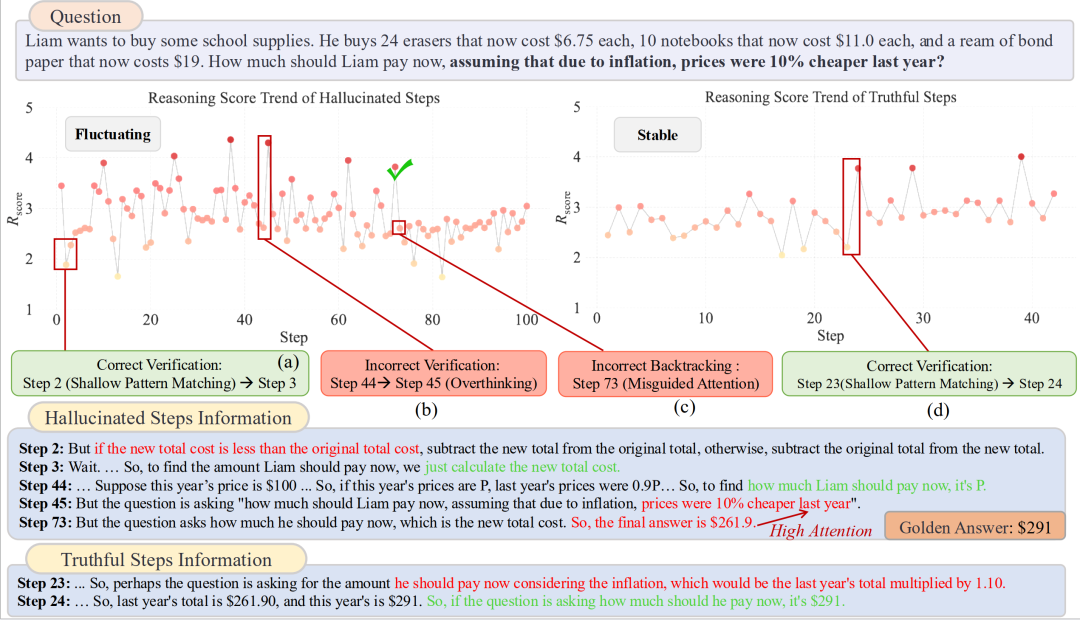
论文介绍
论文题目:Towards High Data Efficiency in Reinforcement Learning with Verifiable Reward
作者:汤昕宇,张振铎,刘语柔,赵鑫,温祖杰,张志强,周俊
通讯作者:赵鑫
论文概述:大语言模型通过采用可验证奖励的强化学习来提升推理能力。然而,扩展这类方法通常需要海量数据和大量计算开销,导致训练成本高昂且数据效率低下。为缓解这一问题,我们提出了 DEPO这种数据高效的策略优化方法,该方法结合了离线与在线数据选择的优化策略。在离线阶段,我们依据多样性、影响力和难度等多重目标,筛选出高质量的训练数据子集。在在线训练过程中,我们提出一种样本级可探索性度量指标,动态过滤掉探索潜力低的样本,从而降低计算成本。此外,我们针对未充分探索的样本采用重放机制来确保充分训练,以提升最终收敛性能。在五个推理基准测试上的实验表明,DEPO 在离线和在线数据选择场景下均一致优于现有方法。尤为突出的是,仅使用 20% 的训练数据,与基于完整数据集训练的 GRPO 相比,我们的方法在 AIME24 上实现了 1.85 倍的加速,在 AIME25 上实现了 1.66 倍的加速。
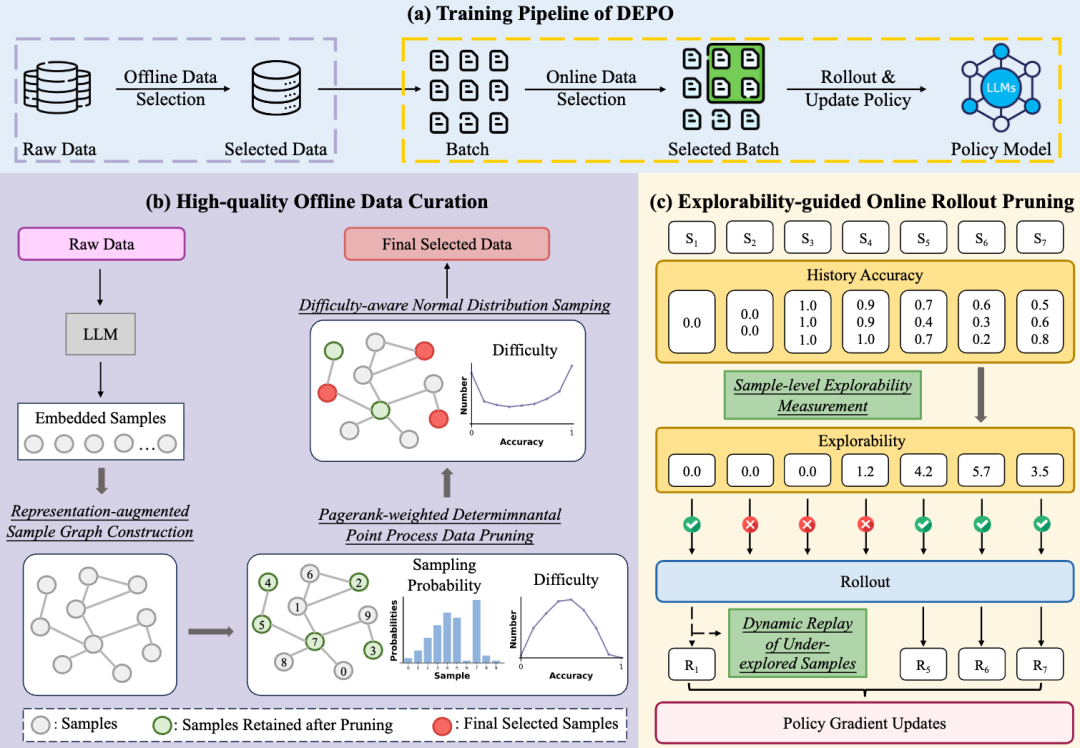
论文介绍
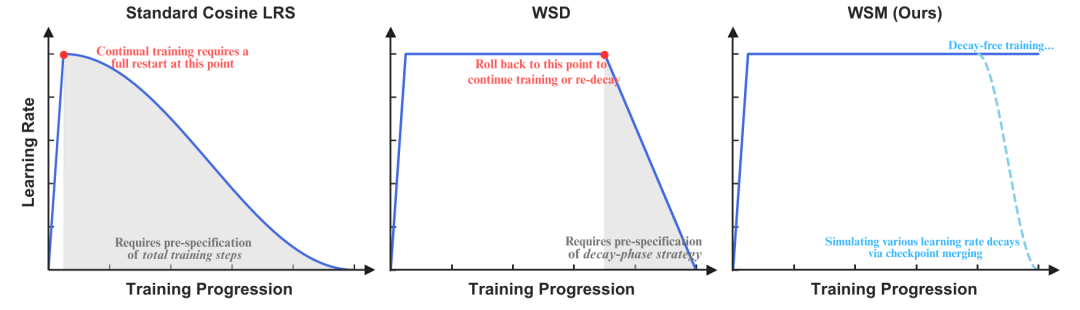
论文题目:WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training
作者:田长鑫*,王家鹏*,赵前,陈昆龙,刘佳,毛佳昕,赵鑫,张志强,周俊
通讯作者:赵鑫,张志强
论文概述:在大语言模型预训练中,学习率衰减(LR Decay)长期以来被视为提升性能的“必选项”,但其刚性的调度策略严重限制了训练的灵活性,并带来了高昂的超参数调优成本。本文提出了一种名为 WSM(Warmup-Stable and Merge) 的新型无衰减学习率调度框架,该方法彻底摒弃了传统训练中显式的学习率衰减阶段,转而通过在训练后对稳定阶段的多个检查点进行离线合并来达到同等甚至更优的效果。WSM 的核心在于建立了学习率衰减与模型合并之间的形式化联系,能够将余弦衰减、线性衰减等多种经典衰减策略统一解释为特定的模型平均方案。研究发现,决定性能的关键因素是合并所覆盖的训练持续时间,而非检查点的数量或间隔。实验表明,WSM 在多个关键基准上显著超越了主流的 WSD(Warmup-Stable-Decay)方法,并在监督微调场景中同样有效,为 LLM 的高效、稳定训练提供了一种新范式。
论文介绍
论文题目:VeriRole: Verifiable Role-Awareness through Hint-Guided Reinforcement Learning
作者:王宗晟,孙凯丽,武博文,于群,李影,陈旭,王宝勋
通讯作者:陈旭,王宝勋
论文概述:在角色扮演对话智能体(RPCAs)中维持角色意识是一项重大挑战,主要归因于角色扮演的创造性本质使得难以设计用于强化学习的可验证奖励信号。为此,我们提出了VeriRole框架,旨在通过结构化、可验证的推理过程增强智能体的角色意识。该框架的核心在于一种“提示(hint)”机制,即在生成主要回复前先从上下文中提取确定性线索,并据此引入“可验证角色意识奖励(VRAR)”以提供明确的反馈信号。实验结果显示,经VeriRole优化的Qwen2.5-32B模型在RAIDEN和CharacterEval基准测试中的平均得分分别提升了18.9%和4.55%,证实了该方法能有效量化并提升角色意识,从而实现更优的人设一致性。
论文介绍
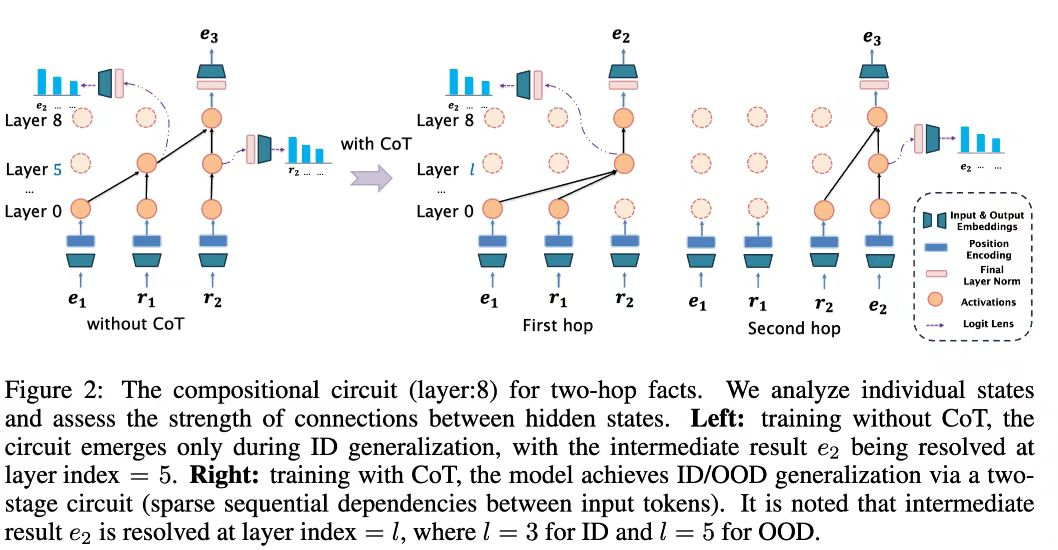
论文题目:Compositional Generalization from Learned Skills via CoT Training: A Theoretical and Structural Analysis for Reasoning
作者:姚鑫浩,任芮锋,廖芸,丁立中,刘勇
通讯作者:刘勇
论文概述:思维链(CoT)训练显著提升了大型语言模型(LLMs)的推理能力,但其增强泛化能力的内在机制尚未得到充分理解。本研究论证了组合泛化在此过程中的核心作用:模型通过CoT训练系统性地组合已掌握的简单技能,以解决新颖且更复杂的问题。通过理论与结构分析,我们形式化了这一过程:1)理论上,基于分布差异的信息论泛化误差可分解为分布内(ID)与分布外(OOD)两个组成部分。具体而言,非CoT训练的模型在面对OOD任务时因遇到未见过的组合模式而失效,而经过CoT训练的模型则能通过组合已学技能实现强大的泛化能力。此外,合成数据与真实数据场景验证均表明,CoT训练能加速模型收敛,并增强从ID场景到ID/OOD场景的泛化性能,即使在一定的噪声环境下仍能保持稳健表现。2)结构上,CoT训练将推理过程内化为两阶段组合式结构回路,其中阶段数量与训练时显性的推理步骤相对应。值得注意的是,相较于非CoT模型,CoT训练模型的中间结果在更浅的网络层中即已得到解析,这使得深层网络能更专注于后续推理步骤。关键洞见在于:CoT训练通过培养组合推理能力,教会模型"如何思考"——而非仅通过提供正确答案来灌输"思考什么"。本研究为设计提升LLMs推理稳健性的CoT策略提供了重要启示。
论文介绍
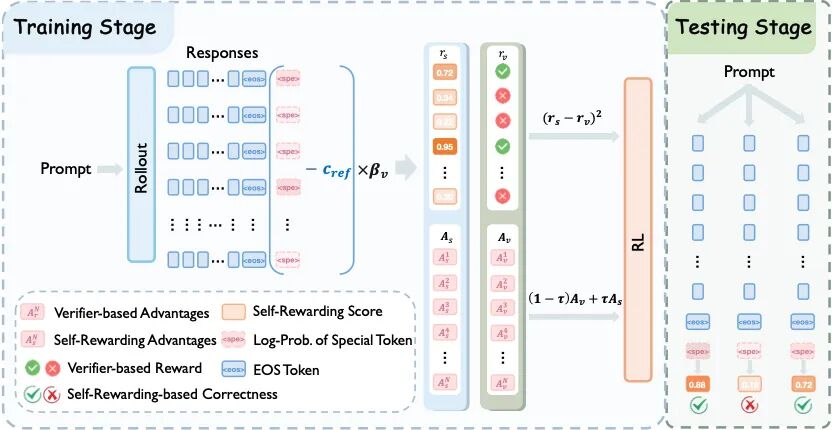
论文题目:LaSeR: Reinforcement Learning with Last-Token Self-Rewarding
作者:杨文恺,刘伟杰,谢若冰,郭一驹,吴璐璐,杨赛勇,林衍凯
通讯作者:林衍凯
论文概述:近年来,基于可验证奖励的强化学习 (RLVR) 已成为提升大语言模型(LLMs)推理能力的核心范式之一。针对在模型测试阶段往往缺乏外部验证信号的问题,已有工作将自验证(self-verification)能力的训练纳入标准RLVR流程,从而在同一个模型中统一推理与验证两种能力。然而,现有做法通常需要模型使用两套不同的prompt模板,先生成解答、再生成自验证,导致每个样本的推理开销几乎翻倍,效率显著下降。在本工作中,我们从理论上揭示,自验证训练的强化学习目标存在一个近似的闭式简化形式:一个解答的真实推理奖励,等价于其基于最后一个token的自奖励分数(last-token self-rewarding score)。该分数可被计算为:在最后一个token处,策略模型对某个预先指定token的预测对数概率,与一个预先计算的常数之差,并经过KL系数进行缩放。基于这一关键洞察,我们提出LaSeR算法(Reinforcement Learning with Last-Token Self-Rewarding):只需在原始RLVR损失上额外加入一个简单MSE损失项,将基于最后一个token的自奖励分数与基于rule-based verifier的推理奖励对齐,便可联合优化模型的推理能力与自奖励能力。优化后的自奖励分数不仅可在训练阶段提供辅助奖励信号,也可在测试阶段用于增强模型推理时扩展(inference-time scaling)表现。更重要的是,LaSeR 的自奖励分数直接来源于模型在生成完解答后、在最后一个token处的next-token概率分布预测,因此最多仅需一个额外token的推理成本,额外开销极低。
论文介绍
论文题目:Extending Sequence Length is Not All You Need: Effective Integration of Multimodal Signals for Gene Expression Prediction
作者:杨钊*,段毅*,朱基炜,巴瀛,曹川,苏冰
通讯作者:苏冰
论文概述:基因表达预测旨在从DNA序列预测mRNA表达水平,这带来了重大挑战。先前的工作通常专注于扩展输入序列长度以定位远端增强子,这些增强子可能从数百千碱基之外影响目标基因。我们的工作首次揭示,对于当前模型而言,长序列建模可能降低性能。即使是精心设计的算法也只能缓解长序列造成的性能下降。相反,我们发现目标基因附近的近端多模态表观基因组信号更为关键。因此我们专注于如何更好地整合这些信号,这一点此前被忽视了。我们发现不同的信号类型发挥着不同的生物学作用,一些直接标记活跃的调控元件,而另一些则反映可能引入混淆效应的背景染色质模式。简单的拼接可能导致模型与这些背景模式产生虚假关联。为解决这一挑战,我们提出了Prism(用于mRNA表达水平预测的近端调控信号整合),该框架学习高维表观基因组特征的多种组合来表示不同的背景染色质状态,并使用后门调整来减轻混淆效应。实验结果表明,对多模态表观基因组信号的恰当建模仅使用短序列就实现了基因表达预测的最先进性能。
论文介绍
论文题目:Learn More with Less: Uncertainty Consistency Guided Query Selection for RLVR
作者:易浩,胡羽蓝,李昕,欧阳晟,丁立中,刘勇
通讯作者:刘勇
论文概述:大语言模型(LLMs)近期通过基于可验证奖励的强化学习(RLVR)显著提升了数学推理能力。然而,现有RLVR算法需要大量查询预算,导致标注成本高昂。本研究探讨是否可通过减少查询次数但提高信息质量来达到同等或更优性能,为此将主动学习(AL)引入RLVR框架。我们发现经典AL采样策略在此场景下未能超越随机选择,其根本原因在于仅依赖主观不确定性进行样本选择时,忽视了客观不确定性的影响。本文提出不确定性一致性指标,用于评估主观不确定性与客观不确定性的匹配程度。在离线场景中,我们采用PBC量化这种一致性;而在在线训练过程中,由于采样有限且输出分布动态变化,PBC难以准确估计。为此,我们提出一种新型在线评估变体,通过标准化优势函数与主观不确定性进行计算。理论上,我们证明该在线变体与离线PBC存在严格负相关,并能支持更有效的样本选择。实验表明,我们的方法在仅使用30%数据训练时,不仅能持续超越随机选择和经典AL基线,还能达到全数据集性能水平,从而显著降低推理任务中RLVR的应用成本。
论文介绍
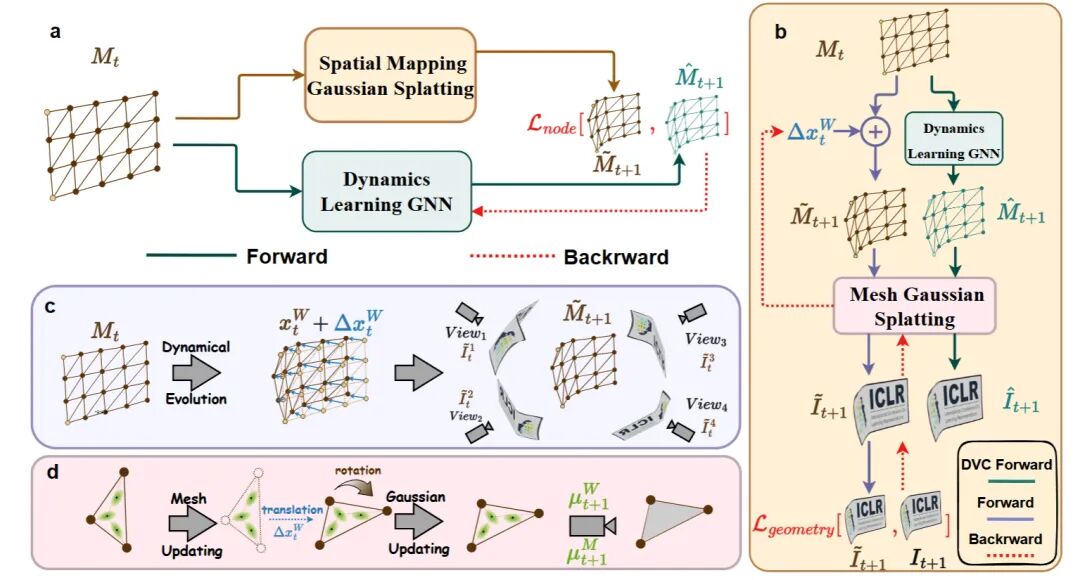
论文题目:CloDS: Visual-Only Unsupervised Cloth Dynamics Learning in Unknown Conditions
作者:詹玉梁,李健,黄文炳,刘扬,孙浩
通讯作者:孙浩
论文概述:深度学习在模拟复杂动力系统方面展现出卓越能力。然而,现有方法通常需要已知的物理属性作为监督信号或输入,从而限制了其在物理条件未知场景下的适用性。为探索这一挑战,我们提出 Cloth Dynamics Grounding(CDG),一种从多视角视觉观测中无监督学习布料动力学的新场景。我们提出 Cloth Dynamics Splatting(CloDS),一个面向 CDG 的无监督动态学习框架。CloDS 采用三阶段流程,首先进行“视频到几何表示”的对齐/落地(video-to-geometry grounding),随后在对齐得到的网格上训练动力学模型。为应对 grounding 过程中大幅非线性形变与严重自遮挡带来的挑战,我们引入一种双位置不透明度调制(dual-position opacity modulation)机制:通过基于网格的高斯溅射(mesh-based Gaussian splatting),实现 2D 观测与 3D 几何之间的双向映射。该机制联合考虑高斯分量的绝对位置与相对位置。大量实验评估表明,CloDS 能够从视觉数据中有效学习布料动力学,并在未见过的配置下仍保持较强的泛化能力。
论文介绍
论文题目:ViPER: Empowering the Self-Evolution of Visual Perception Abilities in Vision-Language Models
作者:张钧天,金松,程传奇,刘雨涵,张恂,张宇飞,姜飞,殷国君,林伟,林衍凯,严睿
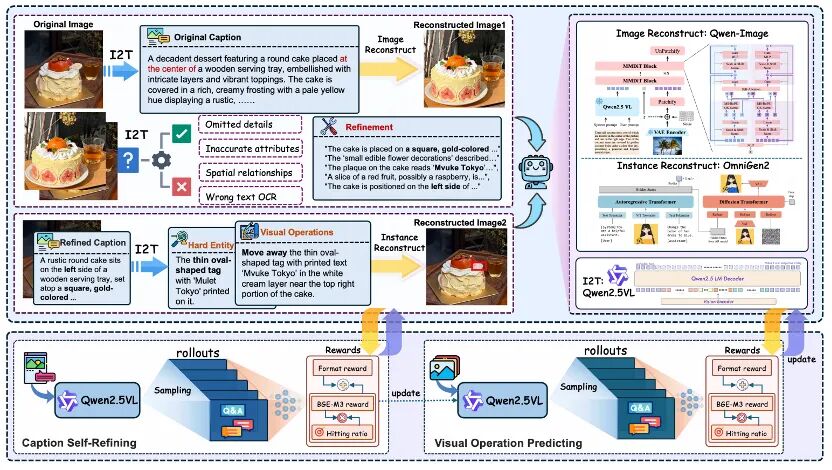
论文概述:细粒度视觉感知能力的局限性是视觉语言模型在实际应用中的关键瓶颈。由于高质量数据的匮乏以及现有方法的局限性,解决这一问题极具挑战性:监督式微调通常会牺牲模型的通用能力,而强化微调则优先考虑文本推理而非视觉感知。针对这一瓶颈,本文提出了ViPER,这是一个基于由粗到精两阶段视觉语言训练的自进化范式。具体而言,ViPER将图像级和实例级重建与分阶段强化学习策略相结合,形成了一个由自我批判和自我预测驱动的闭环训练过程,其中内部合成的数据直接用于提升模型感知能力。我们对Qwen2.5-VL系列模型进行强化得到Qwen-Viper系列模型,在涵盖多种任务的七项综合基准测试中平均提升 1.7%,在精细感知方面提升高达 6.0%,在不同的视觉语言场景中始终展现出卓越的性能,同时保持了良好的泛化能力。ViPER 不仅能够提升感知能力的自我改进,还为生成和理解之间的相互关系提供了确凿的证据,这对于开发更自主、更强大的视觉语言模型而言是一项突破。
论文介绍
论文题目:CurES: From Gradient Analysis to Efficient Curriculum Learning for Reasoning LLMs
作者:曾勇程,孙泽旭,纪博凯,闵尔学,蔡恒毅,王帅强,殷大伟,张海峰,陈旭,汪军
通讯作者:张海峰,陈旭,汪军
论文概述:课程学习在提升大型语言模型推理任务的训练效率方面发挥着至关重要的作用。然而,现有方法往往未能充分考虑提示难度的变化,或者依赖于简单的过滤机制在狭窄的标准范围内选择提示数据集,导致大量的计算资源浪费。本文从强化学习梯度优化的角度出发,对如何提高LLM的训练效率进行了系统的理论研究。我们发现影响训练效率的两个关键因素是:训练提示的选择以及在不同提示之间分配展开量。我们的理论分析表明,提示的采样分布决定了梯度下降的收敛速度,而展开量的分配则影响整体梯度更新的一致性和稳定性。基于这些见解,我们提出了 CurES,一种高效的训练方法,它加速了收敛,并采用贝叶斯后验估计来最小化计算开销。实验表明,我们的 CurES在 Math 500 等 8 个基准上,1.5B 和 7B 模型性能均显著超越现有方法 。同等算力下,相比 GRPO 加速 5.5倍,相比 Reinforce++加速 1.75倍。
论文介绍
论文题目:Unified Biomolecular Trajectory Generation via Pretrained Variational Bridge
作者:虞子扬,黄文炳,刘洋
通讯作者:黄文炳,刘洋
论文概述:分子动力学模拟是以全原子分辨率刻画分子行为的基础性工具,但其应用受到高昂计算成本的严重限制。为应对这一问题,近年来大量深度生成模型被提出,用以在粗化时间步上学习分子动力学,从而实现高效的轨迹生成;然而,这些方法要么在不同体系之间的泛化能力不足,要么由于轨迹数据中分子多样性有限,未能充分利用结构信息来提升生成保真度。本文提出一种以编码器–解码器(encoder–decoder)形式构建的预训练变分桥(Pretrained Variational Bridge, PVB)模型:该模型将初始结构映射到加噪的潜在空间,并通过增强桥匹配(augmented bridge matching)将其输运至阶段特定的目标分布。该框架统一了对单结构数据与成对轨迹数据的训练,使得跨领域的结构知识能够在不同训练阶段中被一致地利用。此外,针对蛋白–配体复合物,我们进一步引入基于强化学习的伴随匹配(adjoint matching)优化策略,加速体系向结合态的演化,从而支持对对接构象的高效后优化。在蛋白质及蛋白–配体复合物上的实验结果表明,PVB 在保持生成动力学稳定且高效的同时,能够忠实再现 MD 模拟中的重要观测量。
论文介绍
论文题目:UltraLLaDA: Scaling the Context Length to 128K for Diffusion Large Language Models
作者:何广心, 聂燊, 朱峰琪, 赵员康, 白天祎, 闫然, 付杰, 李崇轩, 袁彬航
论文概述:扩散语言模型正受到越来越多的关注,近期大量研究都强调了其在各种下游任务中的巨大潜力;然而,这类模型在长文本方面的表现仍有待探索。针对这一现状,我们进行了一项案例研究,旨在通过微调技术扩展扩散模型(以 LLaDA 为例)的上下文窗口,而无需从头开始重新训练。研究表明,仅需对标准的RoPE扩展方式进行简单修改,就能有效适配扩散过程中固有的概率建模特性,从而实现向更长上下文范围的稳定扩展。此外,我们对比了微调阶段使用的不同掩码策略,并分析了它们对优化稳定性及长程召回能力的影响。基于这些发现,我们推出了 UltraLLaDA——这是一款具备 128K上下文窗口的扩散语言模型。实验评估显示,在长文本任务中,UltraLLaDA 的表现显著优于无需训练的基准模型。我们的实验结果强调,特殊的位置编码扩展是扩散模型迈向长文本的关键手段,并为追求通过高效微调实现 128K 规模上下文的从业者提供了实用指南。
论文介绍
论文题目:UltraViCo: Breaking Extrapolation Limits in Video Diffusion Transformers
作者:赵敏,朱泓舟,王英泽,闫博凯,张金涛,何冠德,杨灵,李崇轩,朱军
论文概述:视频扩散 Transformer 尽管近年来取得了不少进展,但难以在训练长度之外实现有效泛化,这一挑战即为视频长度外推。为解决这一问题,我们首先分析出长度外推的两类失效模式:其一是模型特有的周期性内容重复,其二是普遍存在的画质退化。以往工作多通过改进位置编码来缓解重复问题,却忽略了画质退化问题,因此外推能力提升有限。本文从更基础的视角重新审视该问题:注意力图,它直接决定上下文如何影响输出。基于对注意力图的分析,我们发现两类失效模式具有统一根因:注意力弥散,即训练窗口之外的 token 会稀释模型已学到的注意力模式,从而导致画质退化;当这种弥散在位置编码的谐波性质作用下被结构化为周期性的注意力模式时,内容重复便成为一种特殊情形。基于这一洞见,我们提出 UltraViCo,一种无需训练、即插即用的方法,通过一个常数衰减因子抑制训练窗口之外 token 的注意力。通过同时解决两类失效模式,我们在不同模型与外推倍率上整体优于大量基线方法,将外推极限从 2× 推进到 4×。此外,该方法还能无缝泛化到可控视频生成与视频编辑等下游任务。
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号