信息来源:人大高瓴人工智能学院 发布日期:2026年4月14日
「硅基温度·一周热点 Top7」栏目是一份面向AI研究者与科技从业者的精选周报。
我们以理性与洞察,追踪全球范围内最具影响力的AI事件——从模型架构突破到算力体系演进,从产业生态变迁到政策监管动向,每周甄选七则关键节点,为你呈现大模型时代的真实温度与演化脉络。
01
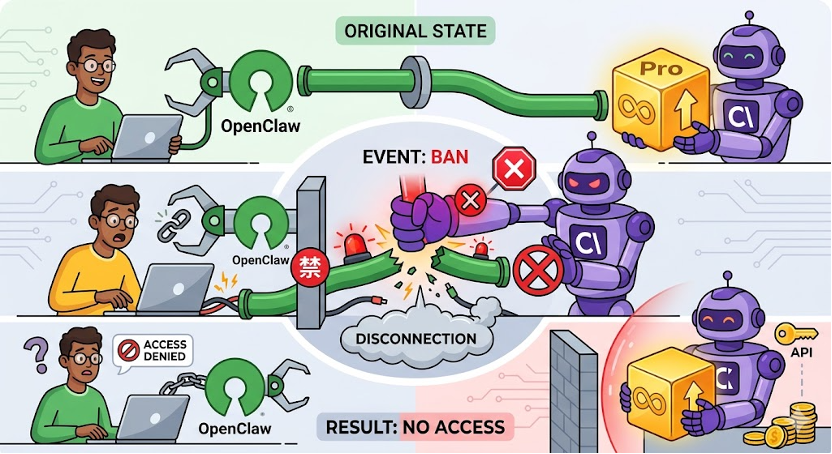
Anthropic 封禁 OpenClaw
第三方生态收紧,AI 工具链从开放走向平台化控制
这件事的核心,其实是在“谁来掌控AI工具入口”。Anthropic 宣布不再让其 Claude 订阅覆盖 OpenClaw 等第三方工具,用户如果还想用,只能额外付费或走 API。这背后表面是安全与竞争问题——OpenClaw 创始人加入了 OpenAI,但本质是平台开始主动“收口生态”。此前 Anthropic 已经通过限制接入、功能替代等方式逐步削弱第三方,如今则是直接切断订阅层的支持。同时,它在力推自家原生工具 Claude Cowork,把用户留在自己的闭环中。对开发者来说,这意味着成本上升、工具链不稳定,甚至需要重构整个工作流;而对行业来说,则释放出一个明显信号:头部模型厂商正在从“开放协作”转向“生态控制”。
一句话总结:AI 工具生态正在从“谁都能接”转向“必须站队”。
(图片由Nano Banana Pro生成)
相关链接 https://x.com/bcherny/status/2040206440556826908
02
Anthropic 收入反超 OpenAI
3.5GW TPU 集群落地,AI 算力与商业化进入正面对决
“钱和算力同时爆炸”,Anthropic 年化收入突破 300 亿美元,首次超过 OpenAI,而且高价值企业客户在短时间内直接翻倍,说明大模型已经真正进入企业核心业务。但问题也很现实:需求越大,算力压力越大。为此,Anthropic 联合 Google 和 Broadcom,计划建设 3.5GW 的下一代 TPU 集群,相当于把“数据中心规模”推到一个全新量级。同时,它还采用 AWS、TPU 和 NVIDIA GPU 的多硬件策略来分摊风险。但另一面是,算力成本正在失控——OpenAI 预计未来几年投入将达到千亿美元级别,盈利能力被严重压制。整体来看,AI 竞争已经从模型能力,升级为“算力+资金+客户”的综合军备竞赛。
一句话总结:AI竞争正在从拼模型,变成拼谁更有钱、更有算力。
相关链接 https://www.anthropic.com/news/google-broadcom-partnership-compute
03
Meta 推出 Muse Spark
多模态原生架构跃升一线,算力效率成最大变量
这次 Meta 的新模型,可以理解为“用更少算力,做更强多模态”。Muse Spark 在评测中大幅领先自家 Llama 4,直接进入全球第一梯队。关键不只是分数,而是架构层的变化:它从一开始就是原生多模态,支持工具调用、视觉推理链,以及类似“多智能体协同思考”的机制,在医疗健康和复杂多模态任务上表现尤为突出。更关键的是效率——它的预训练算力只用了 Llama 4 的约十分之一,推理成本也明显更低。这背后是 Alexandr Wang 团队主导、结合 Scale AI 资源重构技术栈的结果。不过,目前在代码能力和长周期 Agent 上仍有短板。整体来看,Meta 正试图用“高性价比模型”重新进入 AGI 竞争核心区。
一句话总结:大模型竞争开始从“更大更强”,转向“更高效更聪明”。

(图片来自Meta官网)
论文链接 https://ai.meta.com/blog/intr oducing-muse-spark-msl/
技术博客 https://ai.meta.com/blog/scaling-how-we-build-test-advanced-ai/
04
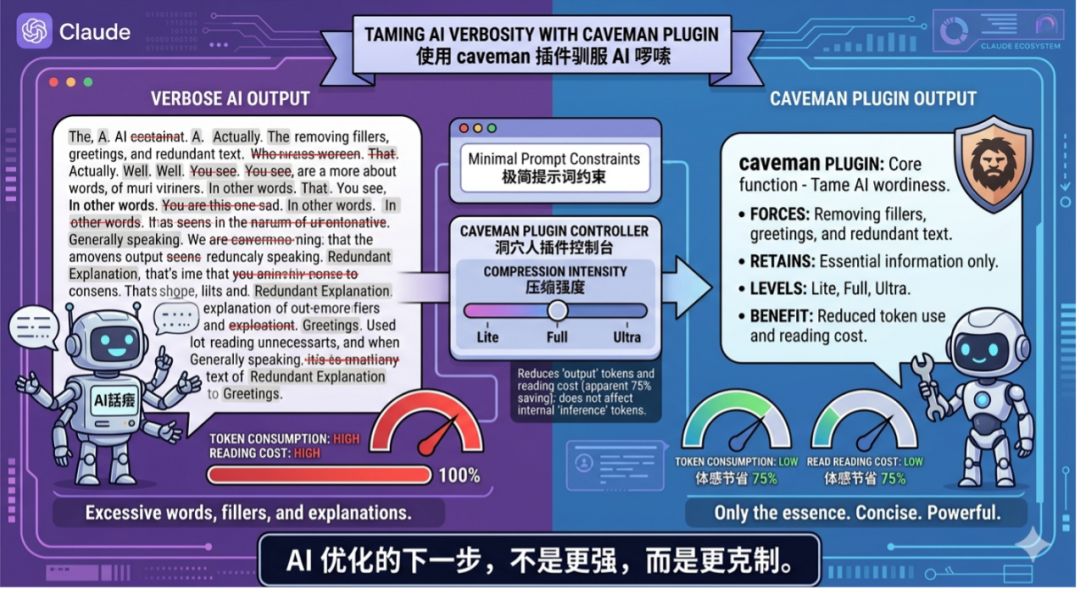
caveman 插件爆火
用“原始人式提示词”压缩输出,直击 AI 冗余与成本痛点
这个爆红的插件,本质是在“驯服AI的啰嗦”。围绕 Claude 生态,caveman 通过极简提示词约束模型输出,比如强制删除冠词、寒暄和冗余解释,只保留信息本体,并提供 lite、full、ultra 三种压缩强度。在开发者社区和 GitHub 上迅速传播,核心原因很直接:它确实减少了无用文本,从而降低 Token 消耗和阅读成本。不过需要明确的是,这种方式只压缩“输出文本”,并不会减少模型内部推理 Token,所谓 75% 节省更多是使用侧的体感收益。更有意思的是,一些研究表明,简洁表达不但不影响效果,反而可能提升模型表现。整体来看,caveman 的走红,本质反映出开发者对“AI话痨”和成本结构的不满,也在推动插件化工具生态加速演进。
一句话总结:AI优化的下一步,不是更强,而是更克制。
(图片由Nano Banana Pro生成)
代码链接 https://github.com/JuliusBrussee/caveman
Claude Skills文档 https://code.claude.com/docs/en/skills
相关论文
https://arxiv.org/pdf/2401.05618
https://arxiv.org/pdf/2604.00025
05
LaSM 让智能体“收回注意力”
无需重训的轻量防御机制,对抗 GUI 弹窗劫持攻击
这项来自 上海交通大学、发表于 CVPR 2026 的工作,解决的是一个很实际的问题:GUI 智能体在操作手机或电脑时,很容易被弹窗等“诱导信息”带偏注意力,进而执行错误操作。作者提出的 LaSM,本质是在模型内部“微调注意力分布”——它先定位注意力开始偏移的关键中间层,然后对该层的注意力权重和 MLP 进行适度放缩,把模型的关注点重新拉回原任务。关键在于,这一过程不需要改模型结构,也不用重新训练,直接作为插件插入即可使用。在实际测试中,它对抗弹窗攻击的成功率大幅提升,与安全提示词结合甚至接近满分,同时对正常任务影响很小。整体来看,这项工作从“模型内部机制”出发,为多模态 GUI 智能体提供了一种高效、可落地的安全加固路径。
一句话总结:不改模型也能防攻击,关键在于把注意力拉回正轨。
论文链接 https://arxiv.org/pdf/2507.10610
代码链接 https://github.com/YANGTUOMAO/LaSM
06
腾讯发布具身智能基座模型
2B 小模型性能反超,大模型与端侧部署双线突破
这次 腾讯 推出的 HY-Embodied-0.5,可以看作是专门为“机器人和现实世界交互”打造的一套基础模型体系。它包含两条路线:一是主打端侧部署的轻量模型 MoT-2B,二是追求极致性能的 MoE-32B,对标 Gemini 3.0 Pro 等顶级模型。核心创新在于全新的 MoT 架构,把任务建模和多模态信息更紧密结合,同时配合原生分辨率视觉编码器和视觉潜在 Token,让模型更好理解真实环境。再加上超过1亿条高质量具身数据训练,小模型也能跑出高性能——MoT-2B 在22项测试中拿下16项第一,甚至超过更大模型。这说明具身智能正在从“堆参数”转向“架构+数据驱动”。目前代码已经在 GitHub 开源,进一步降低了落地门槛。
一句话总结:具身智能开始进入“小模型也能打”的新阶段。
代码链接 https://github.com/Tencent-Hunyuan/HY-Embodied
Hugging Face https://huggingface.co/tencent/HY-Embodied-0.5
07
MemPalace 引爆 AI 记忆赛道
低成本开源方案拿下满分,社区纠错推动技术回归理性
这个项目的特别之处,在于把“长期记忆”做到了极致性价比。由 Milla Jovovich 与工程师 Ben Sigman 借助 Claude 共同打造的 MemPalace,在 LongMemEval 测试中拿下首个满分,并迅速在 GitHub 走红。其核心思路借鉴“记忆宫殿”,把信息结构化为“房间+路径”的存储方式,并结合 ChromaDB 实现本地化低成本记忆管理,年成本甚至压到 1 美元以内。同时还设计了 AAAK 压缩格式来优化存储效率。不过项目发布后,社区指出部分性能宣传存在夸大,例如压缩效果和检索增益并非独特贡献,团队也迅速修正并公开数据。整体来看,这一项目一方面显著降低了大模型长期记忆的使用门槛,另一方面也体现出开源社区在技术纠偏中的关键作用。
一句话总结:AI 记忆系统开始走向低成本普及,但真实能力仍需社区共同校准。
(图片来自MemPalace官网)
代码链接 https://github.com/milla-jovovich/mempalace
项目主页 https://www.mempalace.tech
关于「硅基温度」系列文章
我们希望在当前信息爆炸、浅阅读盛行的环境中将大模型相关的知识冷凝萃取,输出专业、深度、高质量的硬核文章。我们期待与你一起在浮躁的时代静下心来,共品一杯“思想冷萃”。
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号