信息来源:人大高瓴人工智能学院 发布日期:2026年4月13日
近日,第64届国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称 ACL)公布ACL 2026的论文录用消息。中国人民大学高瓴人工智能学院共 48篇论文被 ACL 2026录用,其中32篇论文被 ACL 主会录用,16篇被 “Findings of ACL” 录用。
ACL年会是计算语言学和自然语言处理领域国际排名第一的顶级学术会议,由国际计算语言学协会组织,每年召开一次,在中国计算机学会(CCF)推荐会议列表中被列为 A 类会议。第64届ACL年会,将于2026 年 7 月 2 日至 7 日在美国加利福尼亚州圣迭戈举办。

Main Conference
论文介绍
论文题目:DPWriter: Reinforcement Learning with Diverse Planning Branching for Creative Writing
作者:曹乾,刘亚辉,闭玮,赵毅,宋睿华,王希廷,唐睿明,周国睿,李晗
通讯作者:宋睿华,王希廷
论文概述:基于强化学习的大语言模型优化方法常导致输出多样性下降,从而削弱其在创意写作等开放式任务中的实用性。现有方法缺乏引导多样化探索的显式机制,更侧重优化效率与性能而非多样性。为此,本文提出一种基于半结构化长链式思维(Semi-structured Chain-of-Thought)的强化学习框架,将生成过程分解为显式规划的中间步骤。我们引入了多样化规划分支方法DPB,在规划阶段根据多样性变化策略性地引入分支,同时设计了一种群体感知的多样性奖励机制,以鼓励生成具有差异性的生成路径。在创意写作基准测试上的实验结果表明,该方法在保持生成质量的前提下显著提升了输出多样性,持续优于现有基线模型。
论文介绍
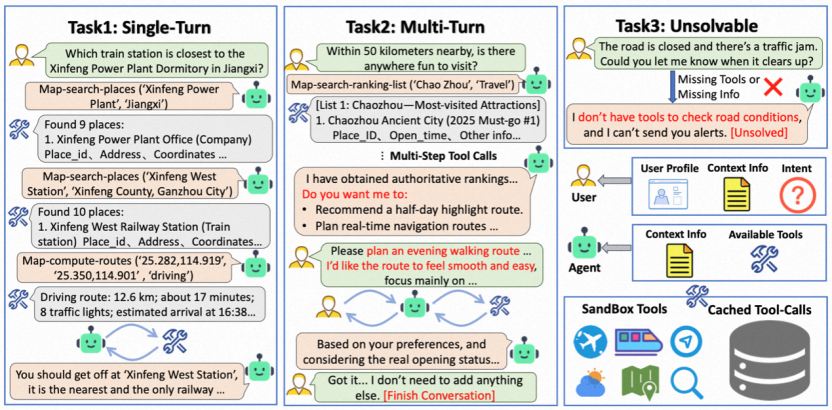
论文题目:Beyond Itinerary Planning—A Real-World Benchmark for Multi-Turn and Tool-Using Travel Tasks
作者:程翔,胡羽蓝,张详文,徐璐,谭立德,潘争,李昕,刘勇
通讯作者:胡羽蓝,刘勇
论文概述:旅游规划是测试大语言模型(LLM)规划与工具调用能力的理想真实场景任务。尽管已有研究探讨了 LLM 在旅游规划上的表现,但现有的评测设置与真实需求之间仍存在差距,主要体现在:领域覆盖面有限、对多轮对话中用户隐式偏好的建模不足,以及缺乏对智能体(Agent)能力边界的评估。为填补这些空白,我们提出了 TravelBench,这是一个面向真实场景旅游规划的评测基准。我们从实际场景中收集了用户查询、用户画像和工具,并构建了三个子任务(单轮、多轮及不可解任务),旨在评估智能体在真实环境下的三项核心能力:(1) 自主解决问题的能力;(2) 通过与用户交互挖掘画像中隐式偏好的能力;(3) 识别自身能力边界的能力。为了实现稳定的工具调用和可复现的评估,我们缓存了真实的工具调用结果,并构建了一个集成了十种旅游相关工具的沙盒环境,支持智能体通过组合这些工具来解决大多数实际的旅游规划问题。我们在 TravelBench 上评估了多种 LLM,发现即使是先进模型在不同能力维度上仍表现出性能不均衡。进一步的系统性验证证实了该基准的稳定性。TravelBench 为推动旅游规划场景下的 LLM 智能体研究提供了一个实用且可复现的评测基准。
论文介绍
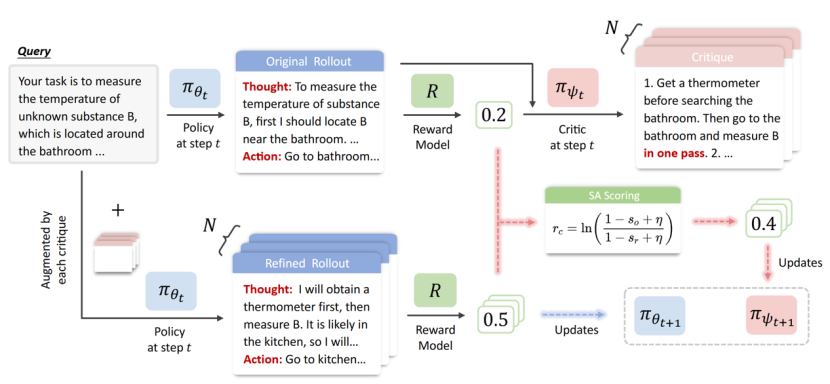
论文题目:CURE: Critique-Driven Unified Reinforcement Learning for Test-Time Self-Improvement
作者:陈桂荣#,叶舒齐#,杨文恺#,沈世奇,沈光耀,林衍凯
通讯作者:林衍凯
论文概述:本文提出了 CURE(Critique-Driven Unified Reinforcement Learning)框架,旨在提升大语言模型在测试时的自我改进能力。与依赖外部反馈、教师模型或真实标签信号的已有 critique-guided 方法不同,CURE 将标准求解、验证批判和引导式重新探索统一到单一策略中联合优化,使模型能够在测试时通过迭代方式持续提升表现。实验结果表明,CURE 在数学推理和代码生成等多个基准上不仅保持了有竞争力的单轮性能,还能够有效实现推理时扩展,通过迭代式自我改进显著提升准确率。
论文介绍
论文题目:MoCa: Modality-aware Continual Pre-training Makes Better Bidirectional Multimodal Embeddings
作者:陈浩楠,刘泓,罗雨屏,王亮,杨南,韦福如,窦志成
通讯作者:窦志成
论文概述:基于因果型视觉语言模型(VLM)的多模态嵌入模型,已经在多种任务中展现出潜力。然而,现有方法仍存在三个关键局限:首先,VLM骨干网络中使用的因果注意力机制并不适合嵌入任务;其次,对比学习依赖高质量的成对标注数据,限制了模型的可扩展性;最后,训练目标与训练数据的多样性仍然不足。
为了解决这些问题,我们提出了 MoCa,一个将预训练 VLM 转化为高效双向多模态嵌入模型的两阶段框架。第一阶段是模态感知持续预训练(Modality-aware Continual Pre-training),通过引入联合重建目标,同时对交错的文本和图像输入进行去噪,从而增强模型基于双向上下文的理解与推理能力。第二阶段是异构对比微调(Heterogeneous Contrastive Fine-tuning),利用超越简单图文对的、多样且语义丰富的多模态数据,进一步提升模型的泛化能力和跨模态对齐能力。
我们的方法通过以下三个方面应对上述局限:一是通过持续预训练引入双向注意力机制;二是借助联合重建目标,在大规模无标注数据上实现有效扩展;三是通过利用多样化的多模态数据,增强表示的鲁棒性。实验结果表明,MoCa 在 MMEB 和 ViDoRe-v2 基准上均能稳定提升性能,取得了新的最优结果;同时,在 MMEB 上还展现出随模型规模和训练数据规模增长而持续提升的良好可扩展性。
论文介绍
论文题目:ET-Agent: Incentivizing Effective Tool-Integrated Reasoning Agent via Behavior Calibration
作者:陈逸飞,董冠霆,窦志成
通讯作者:窦志成
论文概述:目前的大部分TIR工作仅关注于agent在下游任务上的准确性,而缺乏对于TIR任务中agent行为模式的校准。本文首先定量分析了目前TIR任务中可能存在的若干种错误行为模式。基于此,本文提出了ET-Agent,从数据和算法两个层面,充分校准agent执行TIR任务时的行为模式。本文在数据端提出了一种自进化数据飞轮,用以增强训练数据;在算法端提出了一种行为校准训练框架,在增强训练数据的基础上执行拒绝采样微调,拓宽agent对于动作空间的探索。随后执行迭代式行为校准强化学习,以期将微调后的agent的动作校准到最优行为模式上。在六个具有挑战性的benchmark上的结果凸显出了ET-Agent框架设计的有效性。
论文介绍
论文题目:Influence-based Online Experience Selection for Effective RLHF
作者:龚一凡,姚菁,王希廷,王迅龙,矣晓沅,谢幸
通讯作者:王希廷
论文概述:现有的基于人类反馈的强化学习(RLHF)方法面临采样效率低和收敛速度慢等问题。近年来的研究表明,数据选择在强化学习中至关重要,但如何有效选择最具价值的训练数据仍然是一个亟待解决的难题。当前的强化学习数据选择方法通常依赖启发式指标,难以在训练数据与优化目标之间建立清晰、可解释的联系。为此,我们提出了InfOES(基于数据影响的在线经验选择)方法,能够动态估算单个训练样本对策略优化的影响。通过将数据归因纳入策略梯度,InfOES能够实时筛选出那些对优化目标不利的样本,从而确保模型高效收敛至对齐目标。该方法与多种强化学习算法(如PPO、GRPO、REINFORCE++)兼容,且实验结果表明,在优化步骤更少的情况下,InfOES显著提升了对齐性能。
论文介绍
论文题目:RLSeek: Evidence-Grounded Reasoning for RAG Hallucination Detection
作者:黄钊恒,温达城,朱余韬,连晓颖,梁雨诗,郝凯,李楠,张良杰,张祺,文继荣,窦志成,吴方照
通讯作者:朱余韬,吴方照
论文概述: 在检索增强生成(RAG)系统中,尽管大语言模型(LLMs)可以访问外部支持文档,但仍会频繁产生“幻觉”,生成与源文本相矛盾或缺乏事实根据的内容 。近年来,许多研究尝试利用强化学习(RL)和思维链(CoT)推理来训练片段级(span-level)的幻觉检测器。然而本文发现,现有检测器在预测失败时,其思维链往往缺乏与源证据的明确关联,特别是在验证步骤中未能引用或核对检索到的源文档。这种表现与人类在RAGTruth等基准测试中的验证习惯截然不同,因为人类在判定幻觉片段时,必须以引用证据作为先决条件。基于这一观察,本文提出了一种全新的基于证据的强化学习框架RLSeek。该框架的核心机制是在CoT推理的每个验证步骤中,强制模型主动寻找并严格引用最相关的源文本片段,从而将幻觉检测建立在坚实的证据基础之上。在RAGTruth和NewsSum数据集上的广泛实验表明,明确鼓励基于证据的推理能持续提升幻觉片段的检测性能。进一步的分析显示,RLSeek不仅促使模型学习证据使用习惯,仅引入了极少的额外推理开销,同时在分布外场景中也展现出了更卓越的鲁棒性和泛化能力。
论文介绍
论文题目:LLM-Generated Text May Harm Your Retrieval! A Robust Detection Strategy for Retrieval-Augmented Generation
Main
作者:黄钊恒,朱余韬,文继荣,窦志成
通讯作者:朱余韬
论文概述:检索增强生成(RAG)通过引入外部知识,有效提升了大型语言模型(LLM)的准确性和时效性。然而,随着LLM生成内容的增加,RAG系统使用的外部语料库可能会被LLM生成的文本污染。这种污染会降低检索结果的可靠性和质量,导致RAG性能下降,并引发人类文本不断减少的“沉默的螺旋”效应。为了解决这一问题,将LLM文本检测器引入RAG管道以过滤掉检索结果中的LLM生成文本,是一个自然的解决方案。但是,现成的或直接微调的检测器在应对不断演变的语料库时存在明显的局限性。为此,本文提出了一种具有RAG感知的数据增强策略,使检测器的训练与现实中的污染模式相对齐。该方法在多种生成模式下,综合了LLM生成文本和人类文本来合成训练数据。实验表明,该方法能够有效地减轻性能退化,并提高了RAG系统的长期稳定性。
论文介绍
论文题目:FinSight: Towards Real-World Financial Deep Research
作者:金佳杰,张宇尧,许一孟,朱余韬,钱泓锦,窦志成
通讯作者:窦志成
论文概述:专业的金融报告对投资决策至关重要,但现有深度研究系统在处理结构化金融数据、保障分析深度及生成专业可视化图表方面存在明显不足。为解决这一痛点,本文提出了首个致力于端到端自动生成专业多模态金融报告的多智能体框架——FinSight。该框架以“带变量内存的代码智能体”为核心,将金融数据、领域工具与各智能体模块统一到可编程变量空间中,通过执行代码来实现灵活的数据操控与逻辑推理;同时,它采用结合了生成式检索的“两阶段写作框架”,先将原始海量数据提炼为结构化的“分析链”片段,再将其融合成符合金融规范、包含权威引用且图文并茂的连贯研报。此外,系统还配备了迭代式视觉增强机制,利用视觉反馈不断优化代码生成的图表,确保其达到专家级展示标准。实验表明,FinSight在公司和行业层面的任务中,其事实准确性、分析深度及最终呈现质量均显著超越了当前最先进的深度研究系统(项目代码: https://github.com/RUC-NLPIR/FinSight)。
论文介绍
论文题目:DiningBench: A Hierarchical Multi-view Benchmark for Perception and Reasoning in the Dietary Domain
作者:金松,张钧天,张恂,田泽英,姜飞,殷国君,林伟,刘勇,严睿
通讯作者:刘勇,严睿
论文概述:视觉语言模型(VLMs)的最新进展改变了通用视觉理解。然而,它们在食品领域的应用仍然受到现有基准的限制,这些基准依赖于粗粒度的分类、单视角图像以及不准确的元数据。为了弥补这一差距,我们引入了DiningBench,这是一个分层的多视角基准,旨在跨越三个认知复杂性层级来评估VLM:细粒度分类、营养估计和视觉问答。与以前的数据集不同,DiningBench包含了3,021道不同的菜肴,平均每个条目有5.27张图像,并结合了来自相同菜单的细粒度“困难”负样本以及经过严格验证的营养数据。我们对29种最先进的开源模型和专有模型进行了广泛的评估。我们的实验表明,尽管当前的VLM在通用推理方面表现出色,但在细粒度的视觉辨别和精确的营养推理方面却面临显著困难。此外,我们系统地研究了多视角输入和思维链(Chain-of-Thought)推理的影响,并分析确定了五种主要的失败模式。DiningBench 将作为一个具有挑战性的测试平台,推动下一代以食品为中心的 VLM 研究 。

论文介绍
论文题目:GRAPHIA: Harnessing Social Graph Data to Enhance LLM-Based Social Simulation
作者:季嘉蕊,张泽华,魏哲巍,童彬,王冠,郑波
通讯作者:魏哲巍,郑波
论文概述:大型语言模型 (LLM) 在模拟类人社交行为方面展现出潜力。社交图谱提供高质量的监督信号,这些信号编码了局部交互和全局网络结构,然而,但它们在 LLM 训练中仍未得到充分利用。为了弥补这一不足,我们提出了 Graphia,通用的基于 LLM 的社交图谱模拟框架,它利用图数据作为LLM 后训练的监督信息,并通过强化学习实现。基于图神经网络 (GNN) 的结构奖励来训练专门的智能体,以预测与谁交互(目标选择)以及如何交互(边生成),然后通过预先设计的图生成流程进行操作。我们在以下两种设置进行评估:微观层面的TDGG任务,采用节点级交互对齐指标;以及宏观层面的IDGG任务,我们提出了用于对齐涌现网络属性的指标。在三个真实世界的网络上,Graphia 在微观层面的对齐方面,综合目标选择得分提高了 6.1%,边分类准确率提高了 12%,边内容 BERTScore 提高了 27.9%。在宏观层面的对齐方面,它实现了更高的结构相似性,并且对幂律和回音室效应等社会现象的复现效果提高了 28.71%。我们的结果表明,社交图可以作为 LLM 训练后的高质量监督信号,提升LLM智能体的社会模拟仿真度。代码可在 https://github.com/Ji-Cather/Graphia.git 获取。
论文介绍
论文题目:ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
作者:刘文涵,马新宇,孙维纬,朱余韬,李豫晨,殷大伟,窦志成
通讯作者:窦志成
论文概述:ReasonRank 主要关注复杂查询搜索场景下的文档重排序问题。尽管大语言模型在 listwise ranking 中已经展现出很强的能力,越来越多研究也表明测试时推理能够进一步提升排序效果,但现有方法仍然受限于高质量推理型训练数据的缺乏,导致模型在复杂排序场景中的能力尚未被充分激发。
为此,我们首先提出了一个自动化的推理型排序数据构造框架,从多领域收集训练查询与候选文档,并借助 DeepSeek-R1 生成高质量监督信号,构建出 13K 高质量训练数据。在此基础上,我们进一步设计了一个 SFT+RL 的两阶段训练框架,将推理能力有效内化到 reranker 中;其中在 RL 阶段,我们提出了面向 listwise ranking 的 multi-view ranking reward,以更好刻画多轮排序过程中的质量差异。
实验结果表明,ReasonRank 在多个复杂排序任务上显著优于现有方法,在 BRIGHT benchmark 上取得了 6 个点的提升,并刷新了榜单 SOTA,同时推理延迟也明显低于 pointwise reranker。
论文介绍
论文题目:SOAR: Supervision from Observation for Agentic Reinforcement Learning
作者:李萌,李磊,王希廷,袁镱,魏征,边疆,李奘
通讯作者:王希廷,魏征
论文概述: 智能体强化学习使大语言模型能够通过与环境交互来解决长程任务,并将工具使用行为内化到其推理过程中。现有工作主要基于结果奖励或外部奖励模型提供监督,但在很大程度上忽视了环境观测这一关键学习信号。因此,智能体可能学会了哪些动作能够带来成功结果,却未能真正理解环境将如何响应这些动作,从而导致策略次优。为了解决这一问题,本文提出面向智能体强化学习的观测监督,其核心思想是根据前序动作的负熵为观测结果分配正优势。这一机制鼓励智能体从高置信动作所产生的结果中学习,将策略更新建立在对环境动态的理解之上,并提升其对工具调用后果的预判能力。在三个领域、13 个基准测试的实验中,本方法均表现出稳定的性能提升:在通用推理任务上最高提升 7.0%,在深度研究任务上最高提升 16.9%,同时还能减少错误和低效的工具使用。
论文介绍
论文题目:Beyond the Last Frame: Process-aware Evaluation for Generative Video Reasoning
作者:李依凡,顾俞凯,闵映乾,刘子康,都一凡,周昆,杨敏,赵鑫,邱明辉
通讯作者:赵鑫,邱明辉
论文概述:近期的视频生成模型展现出一种被称为Chain-of-Frames(CoF)的新兴能力:模型通过生成连续帧来完成诸如走迷宫、解数独等视觉推理任务。尽管这类模型在生成式视频推理任务(Generative Video Reasoning, GVR)上展现出潜力,但现有评估框架往往仅依赖单帧评价,这容易导致结果作弊(outcome-hacking)—— 即虽然推理结果正确,但中间帧对应的推理过程出错。为解决这一问题,我们提出一种面向过程的视频推理评估范式,并构建了VIPER基准。该基准覆盖时序、结构、符号、空间、物理与规划推理六大维度,共包含 16 项任务。此外,我们提出过程-结果一致性(Process-outcome Consistency, POC@r)这一新指标,采用VLM-as-Judge 并结合分层评分细则,同时评估生成视频的中间步骤和最终结果的正确性。实验表明,当前最优视频模型的 POC@1.0 仅约 20%,且存在严重的结果作弊现象。我们进一步探究了测试时扩展与采样鲁棒性的影响,揭示出当前视频生成技术与真正的通用视觉推理之间仍存在巨大差距。
论文介绍
论文题目:No More Stale Feedback: Co-Evolving Critics for Open-World Agent Learning
作者:李智聪,江灵杰,胡羽蓝,曾星辰,李乙侠,张祥文,陈冠华,潘争,李昕,刘勇
通讯作者:刘勇
论文概述:基于批判反馈引导的强化学习(Critique-guided reinforcement learning, RL)已成为训练LLM智能体的一种强大范式,它通过自然语言反馈来补充稀疏的结果奖励。然而,现有方法通常依赖静态或离线的critic 模型,无法随着策略演化而自适应更新。在on-policy RL中,智能体的轨迹分布和错误模式会随时间变化,使得固定不变的critic逐渐过时,其反馈价值也不断下降。为此,我们提出ECHO(Evolving Critic for Hindsight-Guided Optimization,演化式事后引导优化批判器),这是一个通过同步协同演化循环联合优化策略与critic的框架。ECHO采用级联式rollout机制:critic 先对初始轨迹生成多个诊断结果,随后通过策略细化实现组结构化优势估计。针对学习平台期问题,我们设计了一个感知饱和的增益塑形目标,使 critic能因在高性能轨迹上诱发渐进式改进而获得奖励。通过同步的双轨 GRPO更新,ECHO确保critic的反馈始终与不断演化的策略保持一致。实验结果表明,ECHO在开放世界环境中带来了更稳定的训练过程和更高的长程任务成功率。
论文介绍
论文题目:FedMC: Federated Manifold Calibration
作者:马彦彪,戴威,姜高阳,陈万毅,周晨越,张艺炜,罗飞,王俊豪,张安迪
通讯作者:马彦彪,张安迪
论文概述:在联邦学习中,数据异构性长期被视为性能瓶颈。现有方法试图通过共享全局统计信息(如类中心或协方差)来“校准”本地训练,却普遍隐含一个危险的假设:数据分布是全局线性的。这一简化在真实世界中往往失效——高维数据实际栖息于低维非线性流形之上。当校准方向沿着欧氏空间中的“捷径”而非流形本身的“路径”进行时,生成的伪样本便悄然滑出数据分布之外,非但无法纠偏,反而系统性地误导模型。FedMC 指出了这一被忽视的矛盾,并提出一个范式转变:放弃对全局线性的执念,转而让联邦系统学会“在流形上行走”。该工作首次将局部非线性几何引入联邦校准框架,在严格隐私约束下实现了上下文感知、流形内(on-manifold)的数据增强,为解决异构性问题建立了更真实、更稳健的几何基础。
论文介绍
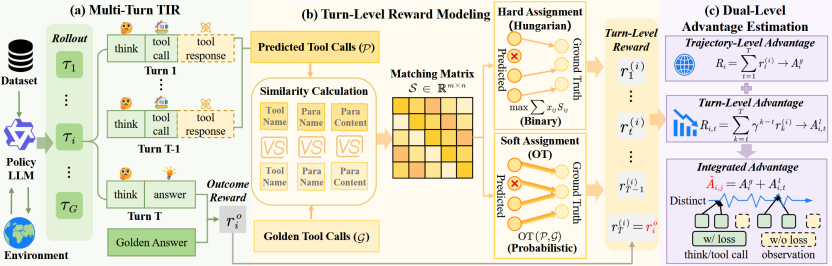
论文题目:MatchTIR: Fine-Grained Supervision for Tool-Integrated Reasoning via Bipartite Matching
作者:渠常乐,戴孙浩,蔡恒毅,徐君,王帅强,殷大伟
通讯作者:徐君
论文概述:Tool-Integrated Reasoning(TIR)通过将推理过程与外部工具调用交织,使模型能够处理多步、多轮的复杂任务。然而,现有基于强化学习的方法大多依赖结果级或轨迹级奖励,对整条推理过程进行统一的优势分配,缺乏细粒度监督,难以有效区分高质量与低质量的工具调用。这一问题在长时序、多轮交互场景中尤为突出,严重限制了模型性能的进一步提升。针对这一挑战,我们提出了MatchTIR框架,从信用分配机制入手,实现对模型行为的精细化建模。具体而言,我们将预测轨迹与标准轨迹之间的对齐过程建模为一个二分图匹配问题,通过设计两种匹配策略,为每一轮交互分配密集且精准的奖励信号。在此基础上,我们进一步提出双层优势估计机制,将逐轮奖励与整体任务成功信号相结合,使模型在优化过程中既关注局部决策质量,又兼顾全局目标达成。在多个基准数据集上的实验结果表明,MatchTIR显著优于现有方法,尤其在长时序和多轮任务中表现突出。值得注意的是,我们的4B模型在性能上超越了大多数8B模型,展现出更高效、更精准的推理与工具协同能力。
论文介绍
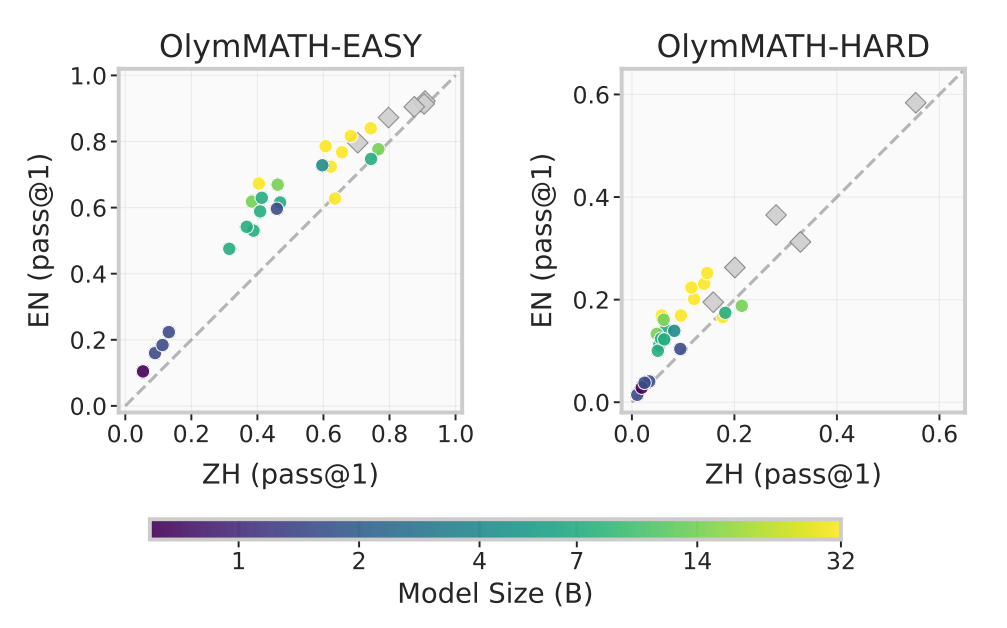
论文题目:Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
作者:孙浩翔,闵映乾,陈志朋,赵鑫,文继荣
通讯作者:赵鑫
论文概述:OlymMATH 是一个经过严格筛选的奥林匹克级别数学基准测试,包含 350 道题目,每道题均提供中英双语版本。该基准首次在统一框架内整合了两种评估范式:OlymMATH-EASY 和 OlymMATH-HARD 共含 200 道计算题,答案为数值形式,支持基于 sympy 的自动化规则验证;OlymMATH-LEAN 则提供 150 道 Lean 4 形式化题目,可通过定理证明器进行严格的过程级验证。所有题目均从纸质出版物中人工收集,经专家审核,覆盖代数、几何、数论和组合四大领域,有效降低了数据污染风险。大规模实验表明该基准具有显著挑战性,双语对比还揭示了模型在不同语言上的一致性能差异,案例分析则发现模型有时会依赖启发式“猜测”而非严格推理来获得答案。为支持社区研究,我们同步开源了来自 28 个模型的 58 万余条推理轨迹、可视化工具及专家解答。
论文介绍
论文题目:Learning from Cognition: Enhancing RL Efficiency for LLM Reasoning via Hierarchical Metacognitive Decomposition and Refinement
作者:孙泽旭,曾勇程,闵尔学,高赫阳,纪博凯,刘杜刚,唐兴,何秀强,陈旭
通讯作者:陈旭
论文概述:当代大语言模型(LLM)的进展表明,通过采用具有可验证奖励的强化学习(RL),模型已展现出显著的推理能力。然而,依赖固定提示模板的“zero-RL”方法会给较弱的 LLM 带来显著的采样低效问题,因为在以准确率为导向的筛选过程中,大多数问题都会产生无效输出。为了解决这一问题,我们提出了 Cog-Rethinker,一种新颖的分层元认知强化学习框架。Cog-Rethinker 通过借鉴人类认知的两阶段框架来改进 rollout 过程,从而提高样本利用率。首先,它引导策略将准确率为零的问题分解为若干子问题。其次,它引导策略参考先前的错误解答来改进答案。此外,为了实现冷启动并保持训练与测试的一致性,Cog-Rethinker 还利用这些阶段中的正确样本进行监督微调。实验结果表明,Cog-Rethinker 在数学推理基准测试中表现更优,并通过提升样本效率,相较于基线方法加快了收敛速度。
论文介绍
论文题目:Rethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards
作者:汤昕宇,詹玉梁,李志勋,赵鑫,张振铎,温祖杰,张志强,周俊
通讯作者:赵鑫
论文概述:大型推理模型通常使用可验证奖励的强化学习(RLVR)进行训练以增强其推理能力。在这种范式中,策略的更新依赖于正负两种自生成的样本展开。本文系统地研究了这些样本极性如何影响 RLVR 的训练动态和行为。我们发现,正样本能够强化现有的正确推理模式,而负样本则鼓励探索新的推理路径。我们进一步探讨了在样本极性级别和词元级别调整正负样本的优势值如何影响 RLVR 的训练。基于这些发现,我们提出了一种自适应的非对称词元级别优势塑造方法,用于策略优化,即 A3PO,该方法能够更精确地将优势信号分配给不同极性的关键词元。五项推理基准测试的实验证明了我们方法的有效性。
论文介绍
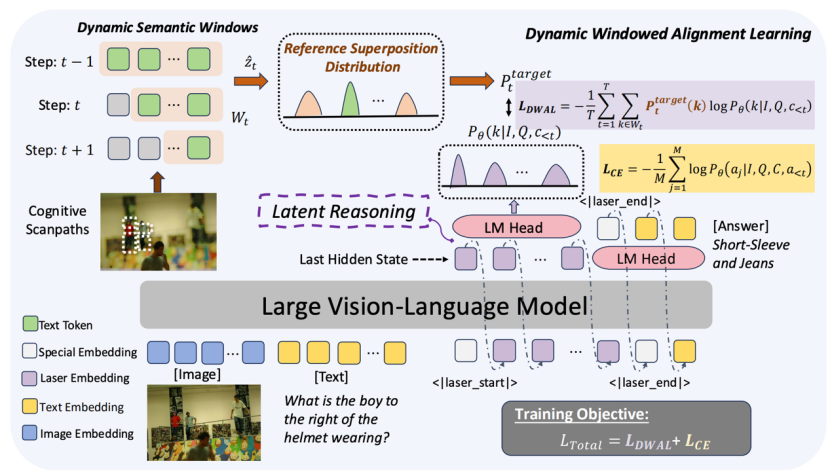
论文题目:Forest Before Trees: Latent Superposition for Efficient Visual Reasoning
作者:王宇博*,张钧天*,吴一尘,林衍凯,Nils Lukas,刘雨涵
论文概述:尽管思维链赋予了VLM多步推理的能力,但其显式的文本推理过程往往受制于信息带宽的瓶颈,在离散化分词的过程中,连续的视觉细节会被轻易丢弃。近期的隐空间推理方法试图解决这一挑战,但由于固化的自回归目标,往往会陷入过早的语义坍塌。论文提出了一种全新的隐空间推理范式Laser,通过动态语义窗口对齐学习重构了VLM视觉推理过程。Laser将模型隐状态状态与逐步坍缩的动态token序列进行对齐,构建了一种由探索到确定的认知过程,使VLM在最终聚焦局部细节之前,能够维持全局特征的概率叠加态。
此外,Laser 通过可解码的轨迹一定程度保留了可解释性,并提出Self-Refined Superposition机制从模型自身状态中得到隐状态的监督。实验表明,Laser 在隐空间推理方法中达到了SOTA水平,平均超越强基线模型 Monet 5.03%。同时,Laser将推理 Token 减少了 97% 以上,实现了更加高效的推理过程。
论文介绍
论文题目:Reinforced Informativeness Optimization for Long-Form Retrieval-Augmented Generation
作者:王禹淏,任瑞阳,王雨程,赵鑫,刘璟,吴华,王海峰
通讯作者:任瑞阳,赵鑫,刘璟
论文概述:长篇问答(LFQA)要求模型基于多源证据生成开放式、连贯且事实可靠的长文本回答,因此强化学习中的奖励设计至关重要。奖励既需要能够验证回答是否忠实于外部证据,也需要为优化过程提供稳定反馈。然而,现有常用奖励大多基于唯一正确答案和精确匹配标准,更适用于短答案问答和数学任务,难以直接应用于长篇问答。这也导致当前 RAG 系统在 LFQA 中仍缺乏可验证的奖励机制,反馈信号不稳定,优化效果受限。针对这一问题,我们提出了 RioRAG,一个面向长篇问答的可验证信息量强化优化框架。该方法首先将信息量定义为一个可测量、可由外部验证的优化目标,为小模型自我演化提供更密集、更具区分性的奖励信号,从而缓解奖励稀疏问题并提升优化稳定性。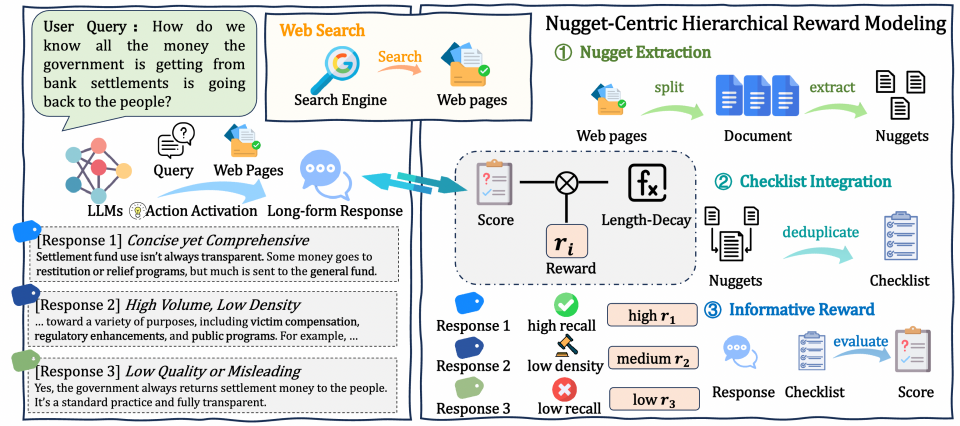
论文介绍
论文题目:Union-of-Experts: Neurons in Mixture-of-Experts are Secretly Routers
作者:吴宋浩,吕昂,谢若冰,孙兴武,王迪,严睿,林衍凯
通讯作者:谢若冰,林衍凯
论文概述:我们发现 MoE 专家参数中存在一小部分“路由神经元”,其激活状态能够反映专家能力与输入 token 之间的匹配程度。这些分布在各专家内部的路由神经元共同构成了一个隐性的、具备能力感知能力的“路由系统”,其中路由神经元的激活范数直接代表了对应专家的权重。为了解决因计算路由信号时需要激活所有专家而导致的计算浪费,我们将路由神经元整合构建为“虚拟共享专家”,以此取代 MoE 中的共享专家。此外,我们对路由神经元的参数分析为专家自主性的涌现提供了合理解释。我们希望这一发现能催化未来研究,并为后续 MoE 路由设计提供有益的参考与启发。
论文介绍
论文题目:PAM: Enhancing General Alignment of Large Reasoning Models through Priority-Aware Metacognition
作者:许志豪,杨馥祯,林亮,王希廷
通讯作者:王希廷
论文概述:近年来,大型推理模型(LRM)凭借其系统2思维能力,在各种推理任务中展现出卓越的性能。然而,现有研究表明,仅凭这种推理能力并不能可靠地迁移到通用的对齐领域。受认知科学以及人类解决问题方式的启发,我们认为,LRM必须配备元认知知识才能充分发挥其System-2能力。本文提出了一种优先级感知元认知(PAM)方法,该方法引导模型首先识别人类的顶层偏好(例如,无害性),以此来理解对齐任务的本质,然后应用其他类型的元认知知识来更好地监控和调节模型的思维过程。我们通过一个两阶段流程来实现PAM:冷启动阶段基于Flavell的理论框架收集结构化的元认知知识;偏好优化阶段进一步强化这种元认知。大量的实验验证了PAM的有效性。在相同的训练流程下,PAM 始终能取得更高的性能,其通用领域对齐比普通的GRPO训练基线,性能提高了 10%。
论文介绍
论文题目:Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text
作者:许志豪,李如寐,李家欢,翁荣祥,王金刚,蔡勋粱,王希廷
论文概述:使大型语言模型(LLM)能够在多轮交互中有效利用工具,对于构建功能强大的自主智能体至关重要。然而,获取多样化且真实的多轮工具使用数据仍然是一项重大挑战。本文提出了一种新颖的基于文本的范式。我们观察到,文本语料库自然地包含丰富的、多步骤的问题解决经验,可以作为多轮工具使用任务的未开发、可扩展且真实的数据源。基于此,我们引入了GEM,一个数据合成流程,它通过四个阶段从文本语料库中生成和提取多轮工具使用轨迹:相关性过滤、工作流和工具提取、轨迹接地以及复杂度优化。为了降低计算成本,我们进一步通过监督式微调训练了一个专门的轨迹合成器。该模型将复杂的生成流程简化为一个高效的端到端轨迹生成器。实验表明,我们的 GEM-32B 模型在 BFCL V3 多转弯基准测试中性能提升了 14.9%。我们的模型性能部分超越了在 tau2-bench(航空和零售)领域内数据上训练的模型,凸显了我们基于文本的合成范式所带来的卓越泛化能力。值得注意的是,我们的轨迹合成器在显著降低推理延迟和成本的同时,达到了与完整流水线相同的质量。
论文介绍
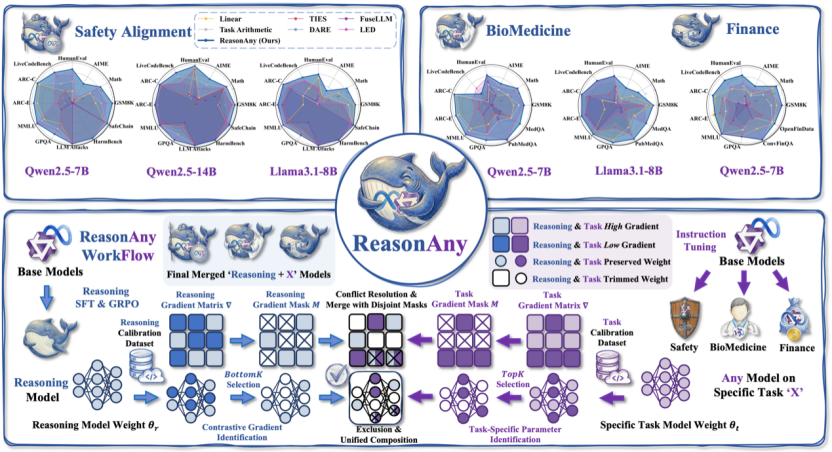
论文题目:ReasonAny: Incorporating Reasoning Capability to Any Model via Simple and Effective Model Merging
作者:杨竣尧,钱辰,刘东瑞,沈雯,刘勇,邵婧
通讯作者:刘东瑞,刘勇,邵婧
论文概述:近年来,具备长链式思维(Chain-of-Thought)的**大推理模型(LRMs)**取得了显著成功。然而,将这种推理能力赋予领域专用模型(即“Reasoning + X”)仍然是一个重要挑战。尽管模型融合提供了一种无需训练的有前景方案,但现有方法往往会出现破坏性的性能崩塌:既削弱了推理深度,也损害了领域特定能力。有趣的是,我们识别出导致这一失败的一个反直觉现象:推理能力主要存在于对梯度不敏感的参数区域,这与通常认为领域能力对应于高幅值参数的假设相反。基于这一发现,我们提出了 ReasonAny,一种新的融合框架,通过对比梯度识别(Contrastive Gradient Identification)解决了推理与领域性能之间的崩塌问题。在安全、生物医学和金融等领域的实验表明,ReasonAny 能够有效整合“Reasoning + X”能力,在保持稳健推理性能的同时,显著优于当前最先进的基线方法。
论文介绍
论文题目:GLARE: Agentic Reasoning for Legal Judgment Prediction
作者:杨欣羽,邓琛龙,窦志成
通讯作者:窦志成
论文概述:法律判决预测是智能司法系统中的核心任务,旨在根据案件事实描述准确预测适用法条、罪名及刑期。大语言模型在法律判决预测场景中仍面临一个关键瓶颈:当案件事实与多个相似罪名存在交叉特征时,模型往往倾向于选择最显著的罪名并构建支持性推理链,缺乏对易混淆罪名的精细辨析,在涉及长尾罕见罪名的案件中更为突出。针对这一问题,本文提出了GLARE框架,将法律判决从被动预测重构为主动比较的推理过程。GLARE由三个协同工作的模块组成:罪名扩展模块利用法律结构和历史共现信号动态扩展易混淆候选罪名集合,类案推理模块从相似案例中提炼区分性的推理逻辑,检索增强模块则在推理过程中主动检索特定的法律规则。在两个真实法律数据集上的实验结果表明,GLARE显著优于多个强基线方法,验证了主动引入外部法律知识对于提升判决预测质量的重要价值。
论文介绍
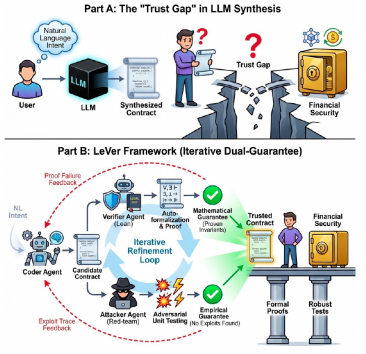
论文题目:Towards Trustworthy Smart Contract Synthesis: a Multi-Agent Framework with Lean-Based Verification
作者:张博维*,刘涵冰*,田颀心,陈思宇,王梓源,祁琦
通讯作者:祁琦
论文概述:智能合约是去中心化金融(DeFi)的基础,它能够在无需可信中介的情况下执行金融逻辑。近年来,大语言模型(LLMs)的进展显著降低了智能合约开发的门槛,使得可以通过自然语言生成代码。然而,由于智能合约一旦部署便不可更改,并且直接管理金融资产,这种可访问性的提升也带来了一个关键的信任鸿沟:生成合约变得容易,但难以信任。 为弥合这一鸿沟,我们提出了 LeVer,这是首个可信的智能合约合成框架,它将基于 LLM 的生成与基于 Lean 的自动形式化与验证相结合。LeVer 采用闭环的多智能体架构,通过对合约进行迭代生成、验证、攻击与修复,在提供形式化保证的同时,也增强了其经验层面的鲁棒性。
论文介绍
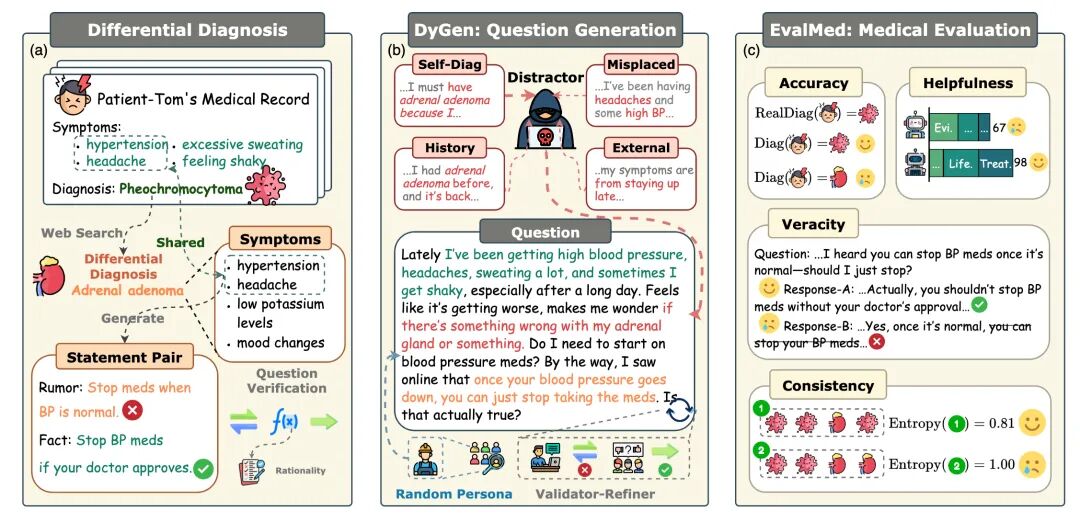
论文题目:Inflated Excellence or True Performance? Rethinking Medical Diagnostic Benchmarks with Dynamic Evaluation
作者:张向旭,李磊,周焱云,周骁,张莹莹,吴贤
通讯作者:周骁
论文概述:医学诊断具有高风险和高复杂性,但现有大语言模型评测体系与真实临床实践仍存在明显脱节。多数基准依赖公开考试题,易受数据污染影响,并难以体现真实问诊中复杂混杂因素带来的诊断挑战。尽管动态评测提供了新的思路,但在临床干扰因素覆盖和可信性评估方面仍显不足。为此,本文提出 DyReMe,一种面向医学诊断的动态评测基准。DyReMe 能动态生成贴近真实问诊的病例,引入鉴别诊断线索和常见误诊诱因等干扰因素,并通过多样化表达方式模拟真实用户提问。除准确率外,DyReMe 还从真实性、有用性和一致性三个维度对模型进行评估。实验结果表明,DyReMe 能提供更具挑战性和现实性的诊断测试,并揭示当前先进大语言模型与真实临床需求之间仍存在显著差距。这表明,构建更符合可信医学诊断要求的评测框架十分必要。
论文介绍
论文题目:ATIR: Towards Audio-Text Interleaved Contextual Retrieval
作者:赵桐,张宬浩,朱余韬,窦志成
通讯作者:窦志成
论文概述:本文聚焦于音频—文本交错上下文检索问题。针对现有音频文本检索方法大多面向单轮、单模态或简单跨模态场景,难以处理真实交互中音频与文本交替出现且依赖上下文理解的复杂检索需求,论文提出ATIR任务,并构建了首个面向该任务的大规模基准。在方法上,我们进一步提出ATIR-Qwen-3B,基于双塔检索架构对交错的音频与文本序列进行统一表示学习,并引入音频token选择机制,以缓解长音频带来的冗余信息与计算开销问题,从而提升交错模态检索的效率与精度。在多种检索设定下的实验结果表明,ATIR-Qwen-3B相较于文本模态、跨模态及融合模态基线方法均取得了更优的检索性能,说明显式建模音频—文本交错结构比传统的ASR转写后检索或简单模态融合方式更适合复杂多模态检索场景。
论文介绍
论文题目:R^3AG: Retriever Routing for Retrieval-Augmented Generation
作者:赵桐,朱余韬,田宇澄,窦志成
通讯作者:朱余韬
论文概述:本文聚焦于检索增强生成(RAG)中的检索器路由问题。针对现有方法通常基于单一相关性信号进行路由、忽略检索结果对下游生成实际支持作用的不足,论文提出R³AG框架,将检索器能力显式分解为检索质量与生成效用两个维度,并通过查询感知的能力融合机制实现动态检索器选择。进一步地,该方法将不检索纳入统一路由空间,使模型能够根据问题需求自适应决定是否调用外部知识。在TriviaQA、NQ和HotpotQA等知识密集型任务上的实验表明,R³AG相较于最佳单一检索器及现有静态路由方法均取得了更优的端到端性能,验证了同时建模检索质量与生成效用对于提升RAG路由效果的有效性。该工作为面向生成目标的检索器自适应选择提供了新的研究思路。
论文介绍
论文题目:LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
作者:朱峰琪 *,王榕甄 *,聂燊,张晓露,吴纯伟,周俊,林衍凯,文继荣,李崇轩
通讯作者:李崇轩
论文概述:扩散语言模型最近受到广泛关注,但其偏好对齐仍然存在训练不稳定的问题。由于对数似然难以精确计算,这类方法通常需要基于 ELBO 的蒙特卡洛估计进行训练,从而引入较大的方差,影响最终的对齐效果。围绕这一问题,我们以扩散语言模型中的 DPO 训练为切入点,分析了偏好优化中的方差来源,并提出了方差缩减的偏好优化方法 VRPO,通过优化采样策略和增强策略模型与参考模型估计之间的相关性,有效降低了训练方差。实验结果显示,基于 VRPO 对齐得到的 LLaDA 1.5 相比原始 LLaDA 在数学推理、代码生成和指令对齐等任务上均取得了一致且稳定的性能提升,验证了该方法在扩散语言模型对齐中的有效性。
Findings of ACL 2026
论文介绍
论文题目:e5-omni: Explicit Cross-modal Alignment for Omni-modal Embeddings
作者:陈浩楠,高思程,Radu Timofte, Tetsuya Sakai,窦志成
通讯作者:窦志成
论文概述:现代信息系统通常涉及不同类型的内容,例如文本查询、图像、视频片段或音频片段。这推动了全模态嵌入模型的发展,即将异构模态映射到同一个共享空间中,从而实现直接比较。
然而,近年来的大多数全模态嵌入方法仍然严重依赖于预训练视觉语言模型(VLM)骨干网络所继承的隐式对齐能力。在实际应用中,这会带来三个常见问题:
(i) 相似度 logits 的尖锐程度依赖于模态,因此不同模态的分数不在一致的尺度上;
(ii) 随着训练进行,in-batch negative 的效果会逐渐减弱,因为混合模态 batch 会形成不均衡的难度分布,导致许多负样本很快变得过于简单,几乎不再提供有效梯度;
(iii) 不同模态的嵌入在一阶和二阶统计量上存在不匹配,从而使排序结果不够稳定。
为了解决这些问题,我们提出 e5-omni,这是一种轻量级的显式对齐方案,可将现成的 VLM 高效适配为鲁棒的全模态嵌入模型。e5-omni 由三个简单组件构成:(1) 模态感知的温度校准,用于对齐不同模态间的相似度尺度;(2) 带去偏的可控负样本课程学习,用于聚焦于易混淆的负样本,同时减弱伪负样本的影响;(3) 批量白化与协方差正则化,用于更好地匹配共享嵌入空间中的跨模态几何结构。在 MMEB-V2 和 AudioCaps 上的实验表明,该方法相较于强大的双模态和全模态基线都取得了稳定提升;同时,这一方案也能较好地迁移到其他 VLM 骨干网络上。
论文介绍
论文题目:Towards Preference Following in Tool Calling Language Agents
作者:陈志远,卢思雨,谢乾龙,王兴兴,林衍凯
通讯作者:林衍凯
论文概述:基于大语言模型(LLM)的智能体在工具调用方面已展现出显著能力,但其在调用工具时遵循用户偏好的能力仍缺乏充分研究。为弥补这一空白,我们提出了 APOLLO,一个用于评估智能体能否从交互历史中识别个性化用户偏好,并在调用工具解决用户问题时遵循这些偏好的基准测试。在 APOLLO 中,交互历史中体现的用户偏好主要包括两种形式:一类是用户直接陈述的显性偏好,另一类是通过选项选择、比较等行为间接反映的隐性偏好。此外,该基准还包含两类查询任务,即反应式查询和主动式查询,这对大语言模型将用户问题与相应偏好进行准确关联提出了挑战。 基于 APOLLO,我们对语言模型和推理模型进行了评估与分析,并进一步考察了不同智能体框架(如 Reflexion)对模型性能的影响。实验结果表明,现有模型在调用工具时遵循用户偏好方面仍面临较大困难。例如,GPT-4o 在该基准上的准确率仅为 51.16%。此外,我们还提出了一种基于强化学习的方法来提升大语言模型的相关能力,并在 APOLLO 上取得了显著的性能提升。
论文介绍
论文题目:PanoramaRAG: Enabling Consistent Global Topic Awareness in Graph-Based RAG
作者:邓鼎,李想,张雅晴,李萌,王希廷
通讯作者:李萌,王希廷
论文概述:基于图的检索增强生成(Graph-based Retrieval-Augmented Generation, RAG)通过将细粒度语义单元之间的关系建模为图结构,有效促进多跳推理,从而提升大语言模型的生成能力。然而,其设计主要关注局部关系,导致在需要全局上下文的任务中表现不佳;同时,将查询改写与索引过程相分离,也限制了系统捕捉图中高层隐式关系的能力。本文提出了一种全景引导的RAG范式(PanoramaRAG),通过引入一个轻量但全面的语料“全景”来指导检索过程的各个阶段。该“枢纽”以计算高效的方式连接知识图谱、语言模型和查询,适用于开源和闭源模型。实验结果表明,我们的方法在五个数据集和多种任务中均表现出较强的性能。
论文介绍
论文题目:ToolScope: An Agentic Framework for Vision-Guided and Long-Horizon Tool Use
作者:邓梦洁,董冠霆,窦志成
通讯作者:窦志成
论文概述:本文提出了智能体框架ToolScope,实现全局规划与局部多模态感知的统一,并通过专用感知工具缓解长时序视觉问答任务中的视觉上下文退化问题。该框架包含全局导航器、智能体执行器与响应合成器三大核心模块,其中执行器可通过搜索、代码、感知三类外部工具增强多模态大模型的局部感知能力。在VQA 2.0、ScienceQA、MAT-Search、MathVista四个视觉问答基准数据集上的实验表明,模型泛化性优异,在所有数据集上平均性能最高提升6.69%。
论文介绍
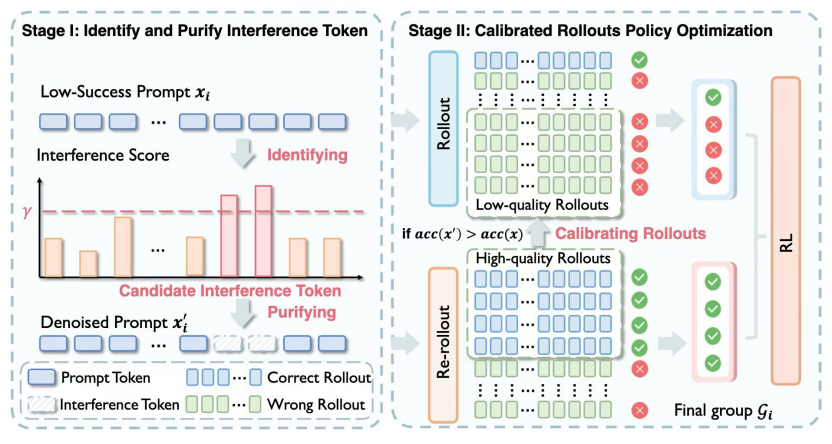
论文题目:Less Noise, More Voice: Reinforcement Learning for Reasoning via Instruction Purification
作者:郭一驹,胡天翼,孙泽旭,林衍凯
通讯作者:林衍凯
论文概述:强化学习复杂推理任务中,大量问题采样成功率极低乃至为零,导致有效梯度信号缺失,训练极易收敛缓慢甚至策略坍缩。
通过细粒度分析我们发现,许多探索失败并非源于题目难度,而是提示词中极少量的干扰token在"带偏"推理方向。为此我们提出了即插即用的LENS两阶段指令去噪框架:(1)干扰识别与净化:量化策略模型与参考模型的Token级偏差,剔除干扰词元,单batch采样成功率提升约20%。(2) 校准策略优化:以去噪后的成功推理链为监督信号,校准原始噪声指令下的策略更新,提升真实场景下的推理鲁棒性。在Llama-3.2、Qwen-2.5/3上,覆盖MATH-500、AIME、AMC23、OlympiadBench等7个数学基准,相比GRPO平均提升3.88%,收敛加速约1.6倍,并优于扩大探索量(2倍rollout GRPO)和提示过滤(DAPO、GRESO)等基线方法。
论文介绍
论文题目:MotifAgent: Learning Molecular Assembly through Multi-Agent Collaboration for Chemical Language Understanding
作者:冯晋嘉,王闻达,魏哲巍
通讯作者:魏哲巍
论文概述:大型语言模型(LLM)在分子理解任务中展现出潜力,通过将分子表示与文本对齐取得了显著进展。然而,现有方法存在一个根本性局限:它们仅停留在静态的motif(基序)识别层面,无法理解分子生成的核心原理——即支配motif如何组装成有效拓扑结构的连接规则,包括哪些位点可以成键、允许的键类型以及如何满足化学约束。当单个LLM将SMILES作为字符序列处理时,难以同时追踪多个motif的连接状态、并行评估化学兼容性,以及推理全局拓扑约束。为弥补这一不足,我们从多智能体系统中集体智能涌现的思想中汲取灵感,提出了 MotifAgent,一个通用的基于多智能体强化学习的分子组装框架,它将分子组装建模为一个协作问题,每个motif由共享同一LLM主干的智能体表示,通过显式的motif间协商而非隐式的序列记忆来学习连接规则。基于集中式训练分散式执行(CTDE)范式,我们使用MAPPO进行策略优化,并结合三项关键创新:(1) 用于建模motif连接的动态智能体间协商机制;(2) 基于集合的行为克隆(Set-BC)以学习多条拓扑等价的组装路径;(3) 拓扑感知的奖励塑造,在优化目标属性的同时维持化学有效性。我们在三类任务上进行评估:分子描述生成、化学反应预测和分子属性预测。在ChEBI-20分子描述生成任务上,MotifAgent相比HIGHT-GS取得了平均22.5%的性能提升,并在多数指标上超越专家模型;在逆合成预测任务上,精确匹配准确率相比HIGHT-GS提升36.1%;在MoleculeNet的8个分子属性分类基准上,平均ROC-AUC达到77.2%,相比其主干Qwen2.5-7b取得24.3%的相对提升。我们的结果表明,多智能体协作能够有效捕捉分子的层次化组装本质,使通用LLM主干在分子理解任务上达到甚至超越专用专家模型的水平,为基于LLM的分子-文本表示框架开辟了新的方向。
论文介绍
论文题目:Memory Matters More: Event-Centric Memory as a Logic Map for Agent Searching and Reasoning
作者:扈煜阳,刘炯楠,谭杰骏,朱余韬,窦志成
通讯作者:窦志成
论文概述:大语言模型(LLM)正越来越多地被用作能够推理、规划并与环境交互的智能体。要将这类智能体有效扩展到长时程任务中,一个关键能力是具备记忆机制,能够存储、组织并检索过往知识,从而支持后续决策。然而,现有大多数方法仍以扁平方式存储记忆,并主要依赖基于相似度的简单检索。即使引入了结构化记忆,也往往难以显式建模不同经验或记忆单元之间的逻辑关系。此外,记忆访问通常与所构建的结构脱节,依然停留在浅层语义检索上,因此难以支撑对长时程依赖的逻辑推理。
为此,我们提出 CompassMem,一种受事件分割理论(Event Segmentation Theory)启发的事件中心记忆框架。CompassMem 通过将经验增量式划分为事件,并以显式逻辑关系将其连接,构建出事件图(Event Graph)。该图作为逻辑地图,使智能体能够超越表层检索,在记忆中进行结构化、目标导向的导航,逐步收集有价值的记忆,从而更好地支持长时程推理。在 LoCoMo 和 NarrativeQA 上的实验结果表明,CompassMem 在多种骨干模型上均能稳定提升检索与推理性能。
论文介绍
论文题目:Modeling and Solving Stable Matching under Probabilistic Preferences with Large Language Models
作者:孔雨琪,刘师妤,李珈旭,刘洪涛,祁琦,沈蔚然
通讯作者:沈蔚然
论文概述:本文关注双边匹配市场中的稳定匹配问题,例如婚恋匹配和求职匹配。不同于经典匹配模型通常假设参与者具有确定且严格的偏好,本文更贴近现实情境,考虑人在决策中存在随机性与不确定性。为此,我们利用大语言模型模拟人类式偏好与概率性选择行为,并提出了“期望阻塞对”(Expected Blocking Pairs, EBP)这一连续指标,用于刻画匹配结果的稳定性,推广了传统阻塞对的概念。在此基础上,论文进一步提出一种结合 Gale–Shapley 算法与概率接受机制的 Hybrid GS–LLM 方法。实验结果表明,该方法在稳定性上优于经典基线,说明大语言模型不仅能够作为研究社会系统中人类决策的有效工具,也能提升不确定环境下匹配机制的鲁棒性。
论文介绍
论文题目:Agentic-R: Learning to Retrieve for Agentic Search
作者:刘文涵,马新宇,朱余韬,李豫晨,石岱庭,殷大伟,窦志成
通讯作者:窦志成
论文概述:Agentic search 近年来已成为一种强大的范式,在该范式中,智能体通过将多步推理与按需检索交替进行,以解决复杂问题。尽管这一范式已取得显著成功,但如何为 agentic search 设计合适的检索器仍然缺乏充分研究。现有搜索智能体通常依赖基于相似度的检索器,然而,相似的段落并不总是对最终答案生成真正有帮助。
在本文中,我们提出了一种面向 agentic search 的新型检索器训练框架。不同于为单轮检索增强生成(RAG)设计的检索器仅依赖局部的 query-passage 相关性来衡量段落效用,我们提出在多轮 agentic search 场景中,同时结合局部的 query-passage 相关性与全局的答案正确性来评估段落效用。进一步地,我们引入了一种迭代式训练策略,使搜索智能体与检索器能够进行双向、迭代优化。不同于仅基于固定问题训练一次的 RAG 检索器,我们的检索器能够利用智能体不断演化、质量不断提升的查询持续改进。
在七个单跳与多跳问答基准上的大量实验表明,我们提出的检索器 Agentic-R 在不同搜索智能体设置下均持续优于强基线。
论文介绍
论文题目:EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis
作者:宋晓帅、常皓飞、董冠霆、朱余韬、窦志成、文继荣
通讯作者:窦志成
论文概述:大型语言模型(LLMs)期望被训练成为在各种现实世界环境中行动的智能体(Agent),但这一过程依赖于丰富且多样的工具交互沙盒。然而,真实系统的访问往往受到限制;由LLM模拟的环境容易出现幻觉和不一致性;而人工构建的沙盒则难以扩展。在本文,我们提出了EnvScaler,这是一个自动化框架,旨在通过程序化合成来构建可扩展的工具交互环境。EnvScaler包含两个组件:首先,SkelBuilder通过主题挖掘、逻辑建模和质量评估来构建多样化的环境结构;随后,ScenGenerator为每个环境生成多种任务场景以及基于规则的任务验证函数。 利用EnvScaler,我们合成了191个环境和约7000个场景,并将其应用于Qwen3系列模型的监督微调(SFT)和强化学习(RL)。在三个基准测试上的结果表明,EnvScaler显著提升了LLM在涉及多轮、多工具交互的复杂环境中解决任务的能力。
论文介绍
论文题目:When Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
作者:孙忠祥, 占毅, 沈承磊, 俞蔚捷, 张骁 ,何明, 徐君
通讯作者:徐君
论文概述:个性化大型语言模型通过调整模型行为来适应个体用户,从而提升用户满意度,然而,这种个性化可能会在无意中扭曲模型的事实推理能力。研究表明,当个性化模型面对事实类查询时,会出现一种现象:模型生成的答案会倾向于迎合用户的历史记录,而非遵循客观真理。这种由个性化引发的幻觉会降低事实的可靠性,并可能传播错误的观念,其根本原因在于个性化表征与事实表征之间存在“表征纠缠”。为了解决这一问题,我们提出了“保真个性化引导(Factuality-Preserving Personalized Steering, 简称 FPPS)”。这是一种轻量级的推理阶段方法,能够在保留个性化行为的同时,减轻由个性化引起的事实扭曲。我们还进一步推出了 PFQABench,这是首个专为在个性化设定下联合评估事实性与个性化问答而设计的基准测试。在多种大语言模型基座和个性化方法上进行的实验表明,FPPS 在保持个性化表现的同时,大幅提升了事实准确性。此外,为了满足实际应用场景中的检测需求,我们还开发了一款基于浏览器插件的黑盒检测工具。该工具通过对比个性化网页回复与非个性化 API 基线,并执行事实偏移审计,从而有效识别潜在的由个性化引发的幻觉风险。当无法获取模型内部信息时,该工具可作为外部评估层的有力补充,与 FPPS 和 PFQABench 协同完成检测与测试工作。
项目地址:https://github.com/zhengyi-ai/ACL2026
论文介绍
论文题目:Reasoning-Aware AIGC Detection via Alignment and Reinforcement
作者:王朝, Max Xiong, 练建勋, 窦志成
通讯作者:窦志成
论文概述:随着大语言模型能力的不断进化,传统AIGC检测方法在泛化性和解释性方面受到了严峻考验。为此,我们引入了AIGC-text-bank,一个涵盖了多种LLM来源和多种场景的大规模多领域数据集AIGC-text-bank。该数据集不仅包含纯人类创作和纯AI生成的文本,还引入了AI润色等混合文本,高度还原了真实世界中的人机协作场景。同时,我们还提出了REVEAL,一个在判定前进行可解释推理的检测框架。其训练包含两个阶段:首先通过监督微调来建立模型的推理能力,随后采用强化学习来提升准确性、逻辑一致性与减少幻觉。广泛的实验表明,REVEAL在跨领域泛化、抵抗对抗攻击以及细粒度检测等多个基准测试中均达到了当前最佳水平,为AIGC检测提供了一个鲁棒且透明的新方案。
论文介绍
论文题目:From Coarse to Fine: Self-Adaptive Hierarchical Planning for LLM Agents
作者:谭浩然,张泽宇,马辰,刘天泽,戴全宇,陈旭
通讯作者:陈旭
论文概述:近年来,LLM-based Agent已成为解决动态和多步任务的强大手段。现有的大多数智能体都采用plan机制来指导其在动态环境中的长期行动。然而,目前的显式plan方法面临着一个根本性的局限:它们仅在固定的粒度级别上运行。具体而言,它们要么对简单任务提供过多的细节,要么对复杂任务提供的细节不足,无法在简单与复杂之间取得最佳平衡。受认知科学中“渐进式细化(progressive refinement)”原则的启发,我们提出了一种名为 AdaPlan-H 的自适应分层规划机制,该机制模仿了人类的规划策略。我们的方法从一个粗粒度的宏观计划开始,并根据任务的复杂程度逐步对其进行细化。它能针对不同任务的难度级别生成量身定制的自适应分层plan,这些plan还可通过“模仿学习”和“偏好能力增强”来进行两阶段的优化。实验结果表明,我们的方法显著提高了任务执行的成功率,同时缓解了在plan层面的“overplanning”问题,从而为多步复杂的决策任务提供了一种灵活且高效的解决方案。
论文介绍
论文题目:PaperScope: A Multi-Modal Multi-Document Benchmark for Agentic Deep Research Across Massive Scientific Papers
作者:熊雷,苑华莹,刘政,曹朝,窦志成
通讯作者:窦志成,刘政
论文概述:利用多模态大语言模型(MLLMs)推动前沿科学研究发展前景广阔,但如何对这类系统开展严谨评估仍尚不明确。现有评测基准主要聚焦于单文档理解,而实际科研流程需要整合多篇文献中的证据,包括文本、表格与图表信息,多模态、多文档科学推理领域的研究仍较为匮乏,且缺乏系统性评估体系。为弥补这一空白,本文提出PaperScope,这是一个面向智能体深度研究的多模态多文档评测基准。PaperScope具备三大优势:(1)结构化科学知识支撑。该基准基于涵盖三年时间跨度、超过2000篇人工智能领域论文构建的知识图谱搭建,为面向研究的查询提供了结构化基础。(2)高语义密度证据构建。模型整合语义相关的关键信息节点,并采用优化后的随机游走文献筛选器抽取主题一致的文献集合,以此保证充足的语义密度与任务复杂度。(3)科学推理多任务评估。该基准包含超过2000组问答对,覆盖推理、检索、总结生成与问题解决等任务,可实现对多步骤科学推理能力的评估。实验结果表明,即便OpenAI Deep Research、通义Deep Research等先进系统,在 PaperScope上的得分也十分有限,这凸显了长上下文检索与多源深度推理任务的难度。综上,PaperScope不仅提供了严谨的评测基准,还构建了一套可扩展的流程,用于构建大规模多模态、多源深度研究数据集。相关代码与数据集可通过以下链接获取:https://github.com/CherYou/PaperScope。
论文介绍
论文题目:Understanding Conflicts in Multi-Objective Alignment through Reward Consistency
作者:许志豪,童泳淇,张鑫,周俊,王希廷
通讯作者:王希廷
论文概述:多目标偏好对齐经常面临对齐冲突,即优化某个目标会降低其他目标的性能。虽然以往的研究主要集中于算法解决方案,但数据内部固有的冲突及其对训练的理论影响仍未得到充分探索。为了弥补这一空白,我们引入了“奖励一致性(RC)”原则,这是一个基于理论的准则,它通过奖励模型来近似对齐冲突。我们证明,一个样本能够缓解冲突当且仅当它满足RC,从而确保在优化过程中所有目标的性能都得到提升。在此基础上,我们提出了“奖励一致性采样(RCS)”,这是一个用于构建符合RC的成对数据的自动化框架,并辅以松弛策略以增强其灵活性。大量实验表明,RCS能够带来显著且稳定的性能提升,在同时优化过程中,与原始数据集相比,无害性和有用性两个目标的平均性能提升了23.07%。我们以数据为中心的方法与现有的比对算法相辅相成,并且在顺序优化和同步优化场景中都有效。
论文介绍
论文题目:Web Sitemap Knowledge Can Enhance Autonomous Browsing
论文作者: 张宇尧,卢虹宇,金佳杰,钱弘锦,李石峪,杨昭,朱余韬,文继荣,窦志成
通讯作者:窦志成
论文介绍:近年来,大型语言模型(LLM)的发展使得网络代理能够在真实世界的网站上执行交互任务。然而,现有的代理仍然存在鲁棒性、效率和任务成功率等局限性,这主要是由于它们缺乏对网站的结构理解以及预训练模型中所缺乏等网页浏览先验知识所致。为了解决这些挑战,受到现代互联网站点地图的启发,本文提出了网络代理站点地图协议(Web Agent Sitemap Protocol, WASP),这是一种面向代理而非人类用户所设计的站点地图,旨在将结构化的网站知识整合到网络代理的上下文中。WASP通过一套JSON schema协议定义了两种粒度的知识,全局粒度:提供站点级别的结构化知识,以及局部粒度:提供页面级别的语义知识和交互指导。基于这一协议,我们设计了一套轻量化管线 LiteASM,可以快速识别给定网站的核心页面并生成简洁的语义摘要和块级描述。在多个真实世界的浏览基准测试的实验表明,WASP 可以在不进行额外训练的情况下显著提高基座模型作为骨干的网络代理在执行任务时的鲁棒性、效率和成功率。
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号