信息来源: 人大高瓴人工智能学院 发布时间:2025年12月15日
「硅基温度-牛导力荐」栏目,每周力邀一位AI领域的顶尖导师,从浩如烟海的论文中,亲自为您挑选一篇“必读好文”。它或许预示着一个崭新的方向,或许内藏着一个精妙的巧思。
在这里,让最具慧眼的领路人,带你穿透信息的迷雾,触摸AI未来的脉搏。
推荐人:马彦彪
中国人民大学高瓴人工智能学院 讲师

马彦彪老师主要关注多模态大模型视觉理解,模态统一范式,长尾学习和联邦学习领域的研究。以第一作者在TPAMI、IJCV、CVPR、ICLR等人工智能领域顶级期刊发表论文10余篇,曾获6项由IGARSS、CVPR、ICCV等举办的国际竞赛冠军。长期担任TPAMI、CVPR、NeurIPS、ICLR等期刊和会议的审稿人。
引言:为何我们需要关注“效率”而非仅“规模”?
2022年底,ChatGPT 如一道闪电划破AI夜空,宣告大语言模型(Large Language Models, LLMs)正式进入主流视野。短短三年间,模型参数从百亿(Llama-7B)飙升至四千亿(Llama-3.1-405B),性能屡破纪录,应用场景从文本生成扩展到代码、推理、多模态乃至智能体决策。这一狂飙突进的背后,是一条被广泛信奉的“铁律”——Scaling Law(缩放律):只要持续增加模型参数和训练数据,性能就会不断提升。
然而,Scaling Law 的胜利也带来了沉重代价。训练一个千亿级模型动辄耗费数千万美元,推理一次复杂任务可能需要数秒甚至数十秒,部署在云端的API调用费用曾一度高达每百万token 20美元(GPT-3.5, 2022)。更严峻的是,推理成本已悄然超过训练成本,成为限制LLM落地的最大瓶颈。企业开始意识到:一个“性能顶尖但贵得离谱”的模型,未必比一个“略逊一筹但便宜十倍”的模型更有商业价值。
与此同时,一场“效率革命”正在悄然上演。2024年,OpenAI 推出 GPT-4o-mini,性能接近GPT-4,价格却仅为后者的1/10;Google 发布 Gemini-1.5-Flash,推理速度提升十倍,成本骤降;Apple 更是在iPhone 16中集成 Apple Intelligence,将LLM直接部署到手机端。这些“小巧高效”的模型引发了一个根本性问题:
大模型的发展,是否正从“唯规模论”转向“唯效率论”?
如果答案是肯定的,那么我们该如何量化这种效率进步?是否存在一条像 Scaling Law 那样简洁而普适的规律,来描述大模型在“单位参数智能含量”上的演进趋势?
正是在这样的背景下,清华大学与 OpenBMB 团队于2025年11月在 Nature Machine Intelligence 发表重磅论文《Densing Law of LLMs》(《大语言模型的密度定律》),首次提出 “能力密度”(Capability Density) 这一核心概念,并揭示了一个令人震撼的经验规律:
大语言模型的能力密度,正以平均每3.5个月翻倍的速度呈指数增长。
这一发现不仅为评估和比较不同规模模型提供了一个统一框架,更预示着一个新时代的到来——LLM 的竞争,不再是“谁更大”,而是“谁更密”。下面,我们将层层拆解这篇论文的核心思想:什么是能力密度?密度定律如何被发现?它有哪些深远推论?又将如何重塑大模型研发范式与产业生态?让我们一起揭开这场“效率革命”背后的科学逻辑。
核心概念:什么是“能力密度”(Capability Density)?
在讨论大模型效率时,一个朴素的想法是:用“单位参数带来的性能”来衡量效率——比如,模型A有7B参数,MMLU得分60;模型B有13B参数,得分65;那么A的“性价比”似乎更高。
但这种直觉存在致命缺陷:大语言模型的能力与参数规模之间并非线性关系。Scaling Law 早已指出,模型性能通常随参数的幂律(power law)增长,即 这意味着,单纯用“性能除以参数”会严重低估大模型的潜力,也无法公平比较不同规模模型的真实“智能密度”。
为解决这一问题,《Densing Law of LLMs》提出了一个巧妙而严谨的替代方案——能力密度(Capability Density)。
1. 直观理解:每单位参数里“装了多少智能”?
作者将能力密度形象地类比为物理学中的“质量密度”:
如果把模型参数看作“体积”,把模型能力看作“质量”,那么能力密度就是“单位体积内包含的质量”。
但与物理不同,LLM 的“能力”无法直接测量。因此,论文转而采用相对评估法:
能力密度 = 达到相同性能,参考模型所需参数量 / 当前模型实际参数量
换句话说,如果一个 2B 参数的小模型能达到一个 7B 参数大模型的性能,那么它的能力密度就是 ——意味着它的每个参数“效率”是后者的 3.5 倍。
2. 技术定义:如何计算“有效参数量”?
关键在于“参考模型所需参数量”这一概念,论文称之为 有效参数量(Effective Parameter Size, ( ))。
由于我们无法对每个模型都训练一个连续参数规模的参考系,作者设计了一套两阶段拟合方法:
第一阶段:拟合 Scaling Curve(损失-参数关系)
使用一系列精心训练的小规模参考模型(0.005B ~ 0.8B),拟合出语言建模损失(loss)与参数量 (N)、训练数据量 (D) 之间的幂律关系: 这一步建立了“模型规模 → 语言建模能力”的基础映射。
第二阶段:拟合 Loss-Performance 映射
利用大量已开源的中等规模模型(如 MiniCPM 系列),计算它们在下游任务(如 MMLU、HumanEval)上的得分 (S) 和对应 loss ( ),再拟合出两者之间的Sigmoid 关系: 这是因为任务性能存在上限(如 MMLU 满分100),且在 loss 极高或极低时性能趋于饱和。
通过这两个函数,就可以反推:给定任意模型在某个任务上的得分 (S),它相当于一个多大参数的参考模型能达到的水平?这个“等效大小”就是 ( )。
最终,能力密度定义为: 为什么这个定义更科学?
它消除了参数规模对性能的非线性影响,使 1B 模型与 100B 模型可比;
它聚焦于“训练质量”而非绝对性能,反映的是“每参数被利用得有多充分”;
它与部署成本直接相关:高密度模型意味着用更少计算资源达成相同效果。
3. 一个关键澄清:能力密度 ≠ 压缩率
值得注意的是,能力密度不等于模型压缩带来的参数减少。论文特别指出(见图3b):
经过剪枝(pruning)、蒸馏(distillation)或量化(quantization)的模型,多数密度反而下降。例如,从 Llama-3.1-8B 蒸馏出的 Llama-3.1-Minitron-4B,虽然参数减半,但密度更低。
原因在于:压缩过程往往缺乏充分的再训练,导致“有效能力”损失大于参数减少的收益。真正的高密度,源于架构、数据、训练方法的系统性优化,而非简单“瘦身”。
Densing Law 的发现:指数增长的实证规律
在提出“能力密度”这一概念框架后,论文作者对 2023 年 2 月 Llama-1 发布以来的 51 个开源预训练 base 模型进行了全面评估。这些模型覆盖了多种主流架构,包括标准稠密 Transformer(如 Llama、Mistral、Gemma)、稀疏混合专家模型(MoE,如 Mixtral、DeepSeek-MoE)以及量化版本(如 GPTQ 压缩模型),确保了分析的广泛代表性。
评估基于五个权威且互补的基准任务:
MMLU:大规模多任务语言理解,测试知识密集型推理;
BBH(Big-Bench Hard):高难度逻辑推理;
MATH:高等数学问题求解;
HumanEval 与 MBPP:代码生成能力。
所有模型均以 few-shot in-context learning 方式评估(具体为 5/3/4/0/3-shot),并采用 Chain-of-Thought(CoT) 提示策略以激发复杂推理能力。特别地,为避免指令微调(instruction tuning)或偏好对齐(preference alignment)引入的性能干扰,作者仅使用预训练 base 模型,确保评估聚焦于模型本身的“原始能力”。
1. 密度随时间呈爆炸式增长

图1 在开源基座模型上估计的能力密度
将每个模型的能力密度与其发布时间绘制在图 1中,一个清晰的模式浮现:最大能力密度(即每个时间点密度最高的模型)随时间呈指数上升。
2023 年 2 月(Llama-1 发布时):密度低于 0.1;
2025 年初(Gemma-2-9B、MiniCPM-3-4B):密度接近 2。
这意味着,短短两年间,单位参数所承载的智能含量提升了近 20 倍。
为量化这一趋势,作者对“最大密度包络线”进行线性回归,拟合以下关系式: 其中:
(t) 为自 Llama-1 发布以来的天数;
( ) 为时间 (t) 时观测到的最大能力密度;
(A) 为增长系数。
基于五项基准的综合评估,拟合得到 (A 0.007),对应 密度每 ( ) 个月翻倍。线性回归的决定系数 ( =0.934),表明指数增长模型具有极强的解释力。
直观理解:
如果今天一个 7B 模型能达到某项性能,那么 3.5 个月后,一个仅 3.5B 参数的模型即可达到同等水平;再过 3.5 个月,仅需 1.75B……这种效率提升的速度,远超多数从业者的直觉。
2. 在contamination-free数据上的稳健验证
为排除“数据污染”(data contamination)——即模型在训练中可能已见过评测数据——对结果的潜在影响,作者进一步在 MMLU-CF(MMLU-Contamination-Free)数据集上重复实验。
MMLU-CF 于 2024 年 12 月构建,通过精心设计的重写操作确保所有问题从未出现在任何公开语料中,是当前最可靠的“干净”评测集。
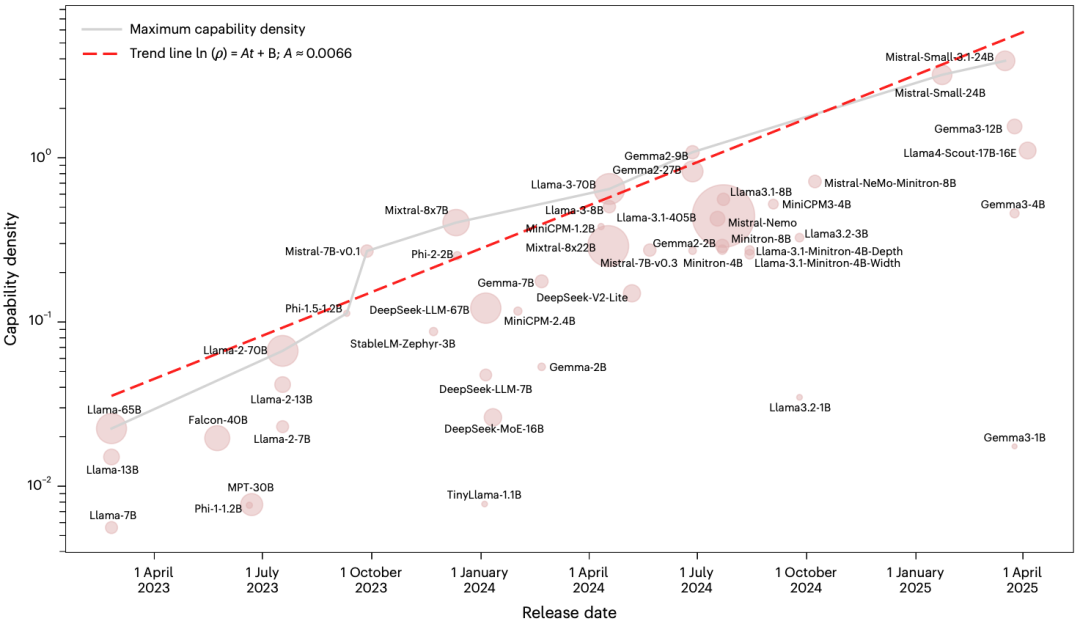
图2 无污染数据集MMLU-CF上的估计能力密度。每个圆的面积与参数大小成正比。最大容量密度随时间呈指数级增长。
图2结果显示:
密度依然呈现显著的指数增长趋势;
拟合系数 (A = 0.0065),与主实验((A = 0.0066))仅相差 1.5%;( = 0.953),甚至更高。
这一验证至关重要:它证明密度定律并非因“过拟合公开数据”而产生,而是反映了 LLM 真实的、泛化的效率进步。
3. 谁在推动密度增长? 关键驱动因素
论文深入分析了密度提升的来源,指出两大核心驱动力:
训练数据规模与质量的飞跃
Llama-1 使用 1.4 万亿 token;
Llama-3 使用 15 万亿 token,并辅以严格的数据清洗;
更多高质量、课程式(curriculum)数据显著提升了参数利用效率。
系统性工程优化
尽管架构(仍以 vanilla Transformer 为主)和训练目标(next-token prediction)基本稳定,但细节优化——如 Grouped-Query Attention、SwiGLU 激活、更优学习率调度——共同提升了训练稳定性与收敛速度。
一个反直觉发现:
当前最强开源模型 Llama-3.1-405B 虽性能顶尖,但并非密度最高。这说明“盲目扩参”已不再是效率最优路径——密度才是未来竞争的主战场。
密度定律的三大推论(Corollaries)
“密度每 3.5 个月翻倍”这一经验规律看似抽象,但其蕴含的推论却具有极强的现实指导意义。论文明确提炼出三项关键推论,分别指向参数需求、推理成本和边缘智能,共同描绘出 LLM 发展的效率未来。
1. 推论一:同等性能所需参数量指数下降
根据密度定义 ( ),若要求模型在固定任务上性能不变,则其有效参数量 ( ) 为常数。因此,密度指数增长 ( ) 直接意味着实际参数量 ( ) 必须指数衰减: 换句话说:要达到相同能力,未来所需的模型参数将越来越小。
论文给出一个极具说服力的实例:
Mistral-7B(发布于 2023 年 9 月)在多项基准上表现优异;
仅 4 个月后发布的 MiniCPM-2.4B(2024 年 2 月),参数仅为前者的 34%(2.4B / 7B),却能实现相当甚至更优的性能。
这意味着,开发者无需再盲目追求千亿参数——一个精心训练的 2B 模型,就可能在 6 个月内取代当前 8B 模型的主流地位。这一趋势将彻底改变模型选型逻辑:“小而精”正成为新范式。
2. 推论二:推理成本指数下降
参数量减少直接带来计算与内存开销降低,进而驱动推理成本快速下降。但有趣的是,实际成本下降速度比密度增长更快。
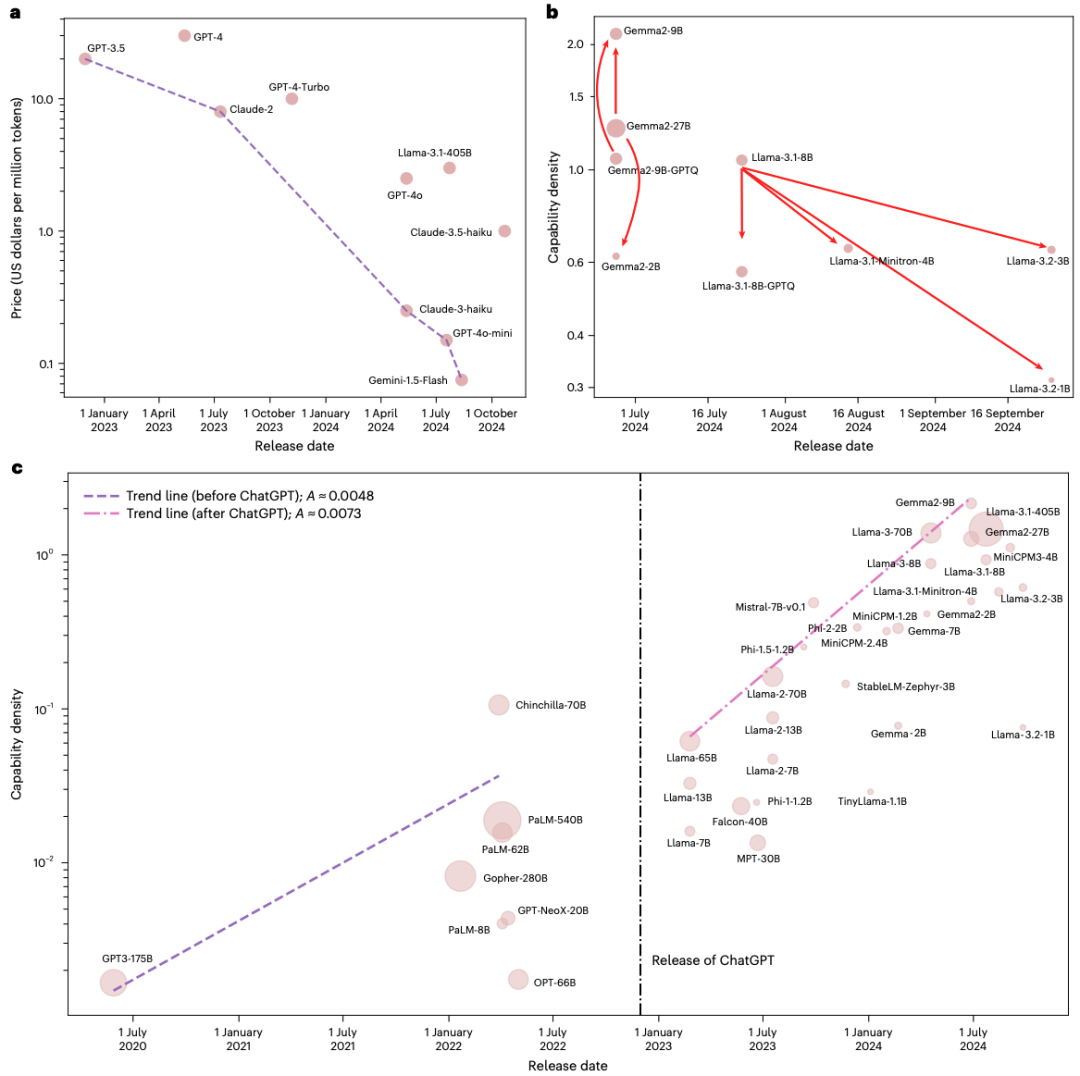
图3 对密度定律推论的观察。a,性能优于 GPT-3.5 的 LLM 的 API 价格。图中直线连接了价格最低的模型。价格最低的 LLM 的 API 价格呈指数级下降。b,压缩模型与其较大版本模型的比较。这表明,有效的压缩并不总是能提高模型密度。c,使用 MMLU 评估模型密度。两条趋势线分别代表 ChatGPT 发布前后 LLM 模型密度的增长情况。ChatGPT 发布后,模型密度的增长速度显著加快。b 和 c 中每个圆的面积与参数大小成正比。
论文图 3a 展示了自 GPT-3.5(2022 年 12 月)以来,性能优于它的最便宜模型 API 价格变化:
2022 年 12 月:GPT-3.5 价格为 $20 / 百万 token;
2024 年 8 月:Gemini-1.5-Flash 价格降至 $0.075 / 百万 token;
成本下降 266 倍,相当于每 2.6 个月减半(快于密度翻倍周期 3.5 个月)。
为何成本下降更快?作者指出推理成本不仅取决于模型大小,还受益于系统级优化:
算法层:FlashAttention、PagedAttention 等技术优化显存访问;
系统层:vLLM、TGI 等推理引擎提升吞吐;
硬件协同:TensorRT-LLM、MLC-LLM 实现端侧高效部署。
启示:企业可基于“2.6 个月成本减半”的趋势,动态调整 AI 项目预算。一个当前月耗 $10,000 的推理服务,6 个月后可能仅需 $1,400。
3. 推论三:“Densing Law × Moore’s Law” = 边缘智能爆发
如果说密度定律描述了算法效率的指数进步,那么摩尔定律(Moore’s Law)则刻画了硬件算力的指数增长。二者的乘积,将引爆边缘 AI 的黄金时代。
论文指出:
密度定律:有效参数/实际参数 每 3.5 个月 ×2;
硬件趋势:同等价格芯片算力每 2.1 年 ×2(≈ 每 25.2 个月 ×2)。
综合两者,在固定硬件预算下,可部署模型的有效能力增长速率为: 总增长速率月月有效能力每天翻倍这意味着:
一个今天只能运行 1B 模型的手机,3 个月后即可本地运行等效 2B 模型,6 个月后等效 4B——而用户无需更换设备!
Apple Intelligence、Gemini Nano、MiniCPM-4 等端侧 LLM 的涌现,正是这一趋势的先行信号。未来,高端 LLM 将像操作系统一样,成为智能设备的标配,且运行成本趋近于零。
关键洞见与反思
密度定律不仅是一条经验规律,更是一面镜子,映照出大模型研发范式的深层演变。论文通过细致的横向与纵向对比,揭示了若干反直觉但极具启发性的洞见。
1. ChatGPT 是效率加速的分水岭
一个令人惊讶的发现是:模型密度的增长并非匀速,而是在 ChatGPT 发布后显著提速。
作者以 MMLU 基准为例(论文图 3c),将 2020 年 GPT-3 发布至 2025 年的模型划分为两个阶段:
2020.06 – 2022.11(ChatGPT 前):密度增长斜率 (A 0.0048);
2022.12 – 2025.04(ChatGPT 后):斜率跃升至 (A 0.0073),增速提升 52%。
思考:为什么 ChatGPT 成为转折点?
资本与人才涌入:ChatGPT 的商业成功证明了 LLM 的巨大价值,引发全球性投资热潮;
开源生态爆发:Mistral、Phi、MiniCPM 等高质量小模型开源,极大降低了研究门槛;
工程范式成熟:数据清洗、课程学习、高效注意力等技术工具箱趋于完备。
这一发现强烈暗示:技术突破不仅依赖算法本身,更依赖生态系统的协同演化。正如作者所建议:“我们鼓励社区开源前沿算法与模型”——因为开放是加速密度提升的催化剂。
2. “压缩 ≠ 高密度”:一个普遍误解
许多团队试图通过剪枝(pruning)、蒸馏(distillation)或量化(quantization) 来“压缩”大模型,以为这样能获得“小而强”的高效模型。但论文图 3b 的数据揭示了一个残酷现实:
绝大多数压缩模型的密度反而低于其原始版本。
具体案例如下:
Llama-3.1-Minitron-4B(由 Llama-3.1-8B 蒸馏而来):密度下降;
Gemma-2-9B-GPTQ(4-bit 量化版):密度下降;
Llama-3.2-1B/3B(剪枝版):密度下降。
唯一例外是 Gemma-2-9B(由 Gemma-2-27B 蒸馏),其密度略高于原始模型——但这恰恰是因为其经过充分的再训练与数据增强。
根本原因在于压缩过程若缺乏针对性的再训练,会导致模型“知识稀释”。参数虽少,但每个参数承载的有效信息并未提升,甚至因训练不足而损失。真正的高密度,源于从训练第一行代码开始就以效率为目标的系统设计,而非事后的“瘦身手术”。
3. “密度最优训练”:可持续 Scaling 的新范式
传统 Scaling Law 指引下的研发逻辑是:“只要算得更多,就能变得更强”。这导致了 Llama-3.1-405B、PaLM-540B 等巨无霸模型的出现。但密度定律揭示了一个悖论:
每一个千亿模型的“成本效益峰值”窗口极其短暂——可能只有 3–6 个月。
6 个月后,一个 100B 甚至 50B 的模型就能达到同等能力,而推理成本可能仅为前者的 1/4。这意味着,盲目追求参数规模不仅浪费资源,还可能导致投资回报周期无法覆盖模型生命周期。
为此,论文提出 “密度最优训练”(Density-Optimal Training) 的新范式:
目标转变:从“最大化性能”转向“最大化单位参数性能”;
技术协同:在架构(如 MoE、多头潜在注意力)、算法(如 RL 驱动的预训练)、数据(高质量、课程式、去污染)三个维度同步优化;
大小模型协同:大模型用于合成训练数据、指导小模型蒸馏;小模型用于快速验证架构、反哺大模型设计。
终极愿景不再是“用 405B 参数解决一个问题”,而是“用 4B 参数解决 100 个问题”。这不仅是工程效率的胜利,更是可持续 AI 发展的必由之路——减少碳排放、降低算力垄断、推动普惠智能。
对研究者与从业者的启示
“密度定律”不仅是对过去两年大模型演进路径的总结,更是一张面向未来的路线图。它为不同角色提供了清晰的行动指南,帮助他们在效率时代做出更明智的决策。
1. 对模型开发者:以密度为目标,而非规模
传统“越大越好”的开发逻辑已难以为继。论文明确指出,每一个千亿模型的“成本效益峰值”窗口可能只有 3–6 个月。在此之后,一个更小、更高效的模型就能以更低的成本提供同等能力。
因此,开发者应:
将“能力密度”纳入核心评估指标,在模型设计早期就监控密度变化;
避免盲目堆参数,转而投入资源优化数据质量(如构建高质量课程式语料)、训练策略(如使用 RL 预训练)和架构效率(如 MoE、稀疏注意力);
建立密度预测模型,基于“每 3.5 个月翻倍”的趋势,科学规划技术路线图。例如,若当前 7B 模型密度为 1.2,可预测 6 个月后新模型密度将达 4.0,从而设定合理的性能-效率目标。
案例参考:DeepSeek-V3 摒弃了 Llama 系列的参数扩展路径,转而采用模块化高效架构,在 7B 规模下实现 40B 级别性能,正是“密度优先”思维的典范。
2. 对企业用户:动态规划 AI 项目成本
企业常因高推理成本而对 LLM 部署望而却步。但密度定律揭示:成本下降速度比性能提升更快——API 价格每 2.6 个月减半。
这意味着企业可:
采用“滚动部署”策略:当前部署 GPT-4o-mini,6 个月后无缝切换至密度更高的开源小模型(如 MiniCPM-4),持续降低 TCO(总拥有成本);
重新评估 ROI(投资回报率):一个当前月耗 $10,000 的客服机器人项目,若延迟 6 个月启动,可能仅需 $2,500/月即可实现相同效果;
优先选择支持端侧部署的模型:随着边缘密度提升,将 LLM 直接部署在用户设备上不仅能降本,还可增强隐私保护与响应速度。
3. 对硬件厂商:为“高密度小模型”设计芯片
过去 GPU 设计聚焦于支持千亿参数大模型的训练与推理。但未来主流负载将变为数十亿参数的高密度模型,其计算特性截然不同:
内存带宽需求相对降低(参数少);
计算密度要求更高(单位参数性能更强);
能效比成为关键指标(用于手机、IoT 设备)。
因此,芯片厂商应:
优化中小模型推理架构,如增加 INT4/FP8 精度支持、设计专用稀疏计算单元;
提供“密度-算力”联合评估工具,帮助开发者在特定硬件上最大化密度;
与模型社区深度协同,例如为 MoE、量化等高效架构提供底层加速。
趋势预判:未来 2–3 年,高端手机 SoC 将普遍集成 10–20 TOPS NPU,足以实时运行 4B–8B 高密度模型——这正是“密度定律 × 摩尔定律”的交汇点。
结语
2017年,Transformer 架构横空出世;2020年,Scaling Law 为大模型指明了“越大越强”的扩张路径;而今天,Densing Law 的提出,标志着大模型发展正式迈入“精耕时代”。如果说 Scaling Law 关注的是能力的上限(即给定算力下模型性能的理论天花板),那么 Densing Law 关注的则是效率的地板(即达成特定性能所需的最低资源门槛)。前者回答“我们能走多远”,后者回答“我们能走多快、多省、多普惠”。
当然,密度增长不会无限持续。论文指出,从信息论角度看,单个参数能承载的信息量存在理论上限,未来密度增速终将放缓,甚至饱和。届时,行业或需借助量子计算、类脑架构等新范式突破瓶颈。但在那一天到来之前,我们正站在一个黄金窗口期——每3.5个月,就有机会用一半的参数,做两倍的事。
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号