信息来源:中国人民大学信息学院 发布日期:2026年2月7日
近日,教育部发布公告,公布2024-2025学年度研究生国家奖学金获奖学生名单,我院谢冬晨、许骞、陈晓栋、吕筱玮、马泽尧、赵文昊、胡建勇、范梅浩、陈思蓓、陆齐、王硕、杜盼、官佳薇、李好洋等14位同学荣获研究生国家奖学金!
青春铸魂,榜样领航。为发挥优秀学子的示范引领作用,凝聚奋进力量,学院特推出2024-2025学年国家奖学金获得者系列专访。通过挖掘他们在逐梦路上的坚守与探索、突破与成长,展现信院学子“敢为人先,科技报国”的精神风貌。愿这些滚烫的青春故事,能为每一位追梦人注入前行动力,激励全院同学在青春赛道上书写属于自己的精彩篇章!
杜盼:以数据为本,锚定可信学习
杜盼,中共党员,中国人民大学信息学院博士研究生,大数据科学与工程专业,隶属于数据仓库与商务智能实验室,师从陈红教授和赵素云教授,并于 2024—2025 年在新加坡国立大学(NUS)计算机学院联合培养。她的研究方向聚焦于数据高效与可信机器学习,致力于在类分布不匹配、标注受限等复杂条件下,构建具备可靠泛化能力的学习方法,为大规模智能系统的稳健应用提供理论与方法支撑。
围绕“数据是否值得被使用、如何被高效利用”这一核心问题,杜盼系统开展以数据为中心的相关研究,重点关注开放环境下弱监督与无监督场景中的可信机器学习算法设计。她以第一作者身份在 TPAMI(影响因子 18.6)、ICCV、ICML 等国际顶级期刊与会议发表论文 5 篇。相关研究成果被新加坡国立大学、华为诺亚方舟实验室等研究团队引用,体现了研究工作的持续影响力与学术价值。
在代表性研究中,杜盼从理论与算法两个层面系统刻画了类别分布不匹配条件下模型性能退化的关键机制,提出了一系列高价值样本识别与噪声样本抑制方法,在有限标注预算下有效提升模型的泛化性能。相关工作不仅通过大量实验验证了方法的有效性,还进一步给出了可解释的理论分析与泛化界限,为数据驱动模型在真实复杂环境中的可信部署提供了支撑。
同时,杜盼积极参与学术共同体建设,受邀担任 AAAI、CVPR、TNNLS 等国际顶级会议与期刊的审稿人,在学术服务过程中不断加深对研究前沿与学术质量标准的理解。

在产业实践方面,杜盼曾于 2021 年在京东、2023 年在百度 实习,参与真实业务场景下的数据建模与算法研发工作。这些实践经历加深了她对算法在复杂系统中落地挑战的认识,也进一步强化了其“以数据为中心”的研究视角。
博士阶段以来,她先后获得中国科协青年科技人才培育工程博士生专项计划、国家奖学金(2025)、国家留学基金委国家公派留学资助(2024)等国家级荣誉,并多次获得中国人民大学学业奖学金一等奖、三好学生、优秀学生干部、拔尖创新人才培育资助计划等校级荣誉。
回顾自己的科研之路,杜盼认为,高水平研究不仅需要模型与算法创新,更需要对数据本身的结构与价值进行深入理解。未来,她将持续围绕数据高效与可信学习这一主线,探索多模态与大模型背景下的数据选择、评估与泛化理论问题,努力在基础研究与实际应用之间形成有效衔接。
“以数据为本,让AI更可信”,是她始终坚持的研究信念。在这条道路上,杜盼正稳步前行,持续推进相关研究探索。
许骞:精算数据,智引未来
访向量宇宙,逐相似之踪迹;探系统内核,寻调度之奥秘。今天,让我们一同走近本年度综合类奖学金获得者、信息学院2023级硕博连读博士研究生许骞,一窥他如何在数据系统领域,围绕高效检索、资源调度方向形成连贯的研究脉络。
许骞,共青团员,中国人民大学信息学院2023级计算机应用技术专业博士研究生,师从杜小勇教授与张峰教授。他的研究方向聚焦于数据系统与智能计算,致力于通过系统级优化与高效索引技术,提升受限环境下的查询性能等。凭借卓越的科研成果,他连续两年获得国家奖学金。至今,他已以第一作者身份在VLDB 2024、SIGMOD 2025、SIGMOD 2026等数据库领域顶级学术会议发表一系列研究成果。
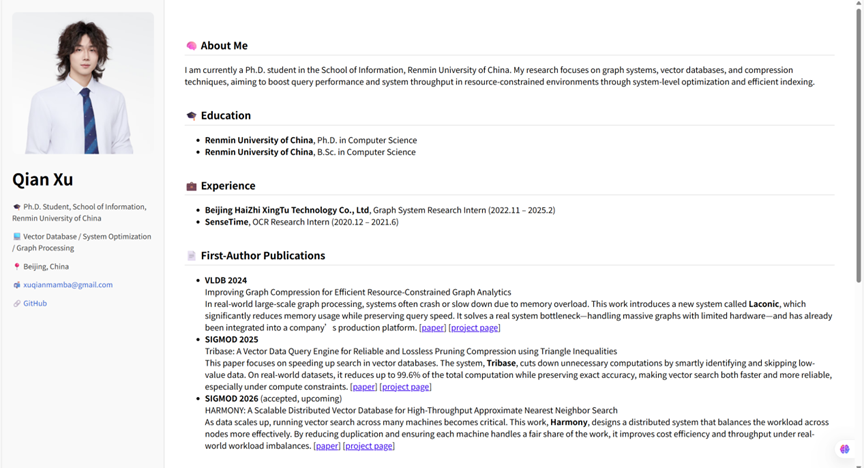
许骞的研究始于对基础数据处理瓶颈的深刻洞察。他的代表性工作Laconic发表于VLDB 2024,直面大规模图分析中普遍存在的“内存墙”与“存储墙”问题。他通过改进图数据压缩技术,在不改变核心算法语义的前提下显著降低了存储与中间态占用,有效解决了有限硬件资源下的图分析瓶颈。
许骞也在向量数据库领域钻研,提出的Tribase系统利用三角不等式进行搜索空间收缩,在保障召回率的同时大幅减少了计算与访存开销,相关成果发表于SIGMOD 2025。更进一步,他将于SIGMOD 2026发表的Harmony工作,则着眼于分布式环境下的可扩展性问题,提出了多粒度数据划分与调度策略,旨在优化不均衡负载下的系统吞吐与查询时延。


许骞不仅在国际顶会上发声,更积极参与业界实践,曾先后在北京海致星图与商汤科技从事图系统及OCR相关的研究实习,积累了深厚的系统实现与调优经验。目前,他的研究视野进一步拓展至大模型与AI基础设施优化及其可信计算。一方面,他关注大语言模型推理与训练过程中的系统级优化,如KV缓存管理、批处理与并行策略等,旨在提升计算资源利用率。另一方面,他积极探索利用TEE等可信执行环境技术,实现对模型参数、梯度等敏感数据的有效保护与可控计算开销。
回望这一路的科研旅途,许骞始终保持着对技术本质的探究欲望。从图数据的压缩到分布式向量检索系统的实现,他每一步都走得扎实而深远。未来,他想继续深耕数据系统底层,探索更高效、更智能的系统架构,参与构建支撑通用人工智能时代的数字基石。
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号