信息来源:人大高瓴人工智能学院 发布日期:2026年1月18日

论文题目
SmartSearch:Process Reward-Guided Query Refinement for Search Agents
作者
文同钰、董冠霆、窦志成*
论文链接
https://arxiv.org/abs/2601.04888
GitHub项目链接
https://github.com/RUC-NLPIR/SmartSearch
摘要
基于大语言模型(LLM)的搜索智能体通过整合信息检索能力,在解决知识密集型问题方面已展现出良好前景。现有研究主要侧重于优化搜索智能体的推理模式,却忽略了推理过程中中间查询的质量。因此,生成的查询往往不够准确,导致检索结果不符合预期,最终限制了搜索智能体的整体效能。为缓解这一问题,我们提出了SmartSearch框架,该框架基于两个关键机制构建:(1)过程奖励,通过双重评估为每个中间查询的质量提供细粒度监督;(2)查询优化,通过选择性地优化低质量查询,并基于这些优化后的查询重新生成后续搜索轮次,促进查询生成的优化。为了使搜索智能体在过程奖励的指导下逐步内化提升查询质量的能力,我们设计了一个三阶段课程学习框架。该框架引导智能体从模仿到对齐,最终实现泛化。实验结果表明,SmartSearch持续超越现有基线,额外的定量分析进一步证实了其在搜索效率和查询质量方面的显著提升。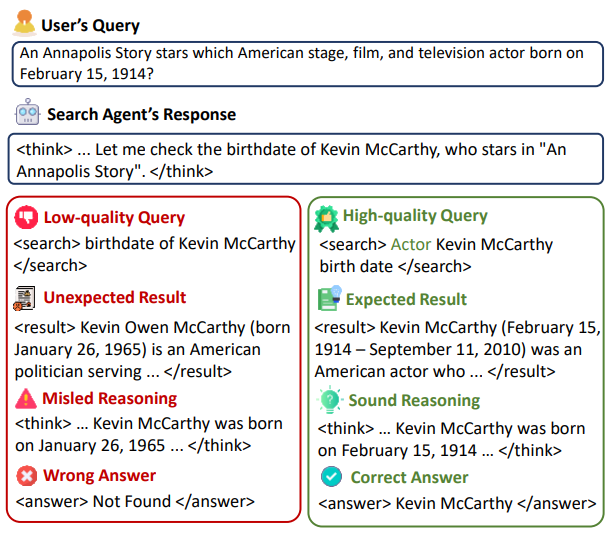
图1:低质量的中间查询会导致不包含期望答案的检索结果并扰乱整个搜索轨迹。
引言
基于大语言模型(LLM)的搜索智能体通过整合信息检索能力,在解决知识密集型问题方面已展现出良好前景。当前关于搜索智能体的研究通过提示工程和微调等方法,在优化搜索智能体的推理模式方面取得了显著进展。然而,它们往往忽视了推理过程中中间查询的质量,而低质量的查询可能会导致不包含期望答案的检索结果,甚至使整个流程偏离正轨,这凸显了查询质量在深度信息查找过程中的重要性。一些研究也尝试将过程奖励融入搜索智能体的训练中。然而,这些研究往往更侧重于塑造更好的推理行为,而非提升中间查询的质量。此外,有研究表明,现有的训练范式常常优先考虑优化对信息的利用能力,却一直忽视对检索模式的优化。这无疑会阻碍搜索智能体实现深度且可靠的信息检索的能力,进而影响其整体性能。这些问题表明,我们需要专门致力于在训练过程中优化查询质量的方法。
在本研究中,我们提出了SmartSearch框架,该框架通过过程奖励的引导来优化搜索查询质量,从而增强搜索智能体的深度信息获取能力。具体而言,SmartSearch包含两个关键机制:(1)过程奖励,通过双重评估为每个中间查询的质量提供细粒度监督;(2)查询优化,通过选择性地优化低质量查询,并基于这些优化后的查询重新生成后续搜索轮次,促进查询生成的优化。在这两种机制的基础上,我们引入了一个三阶段的课程学习框架。该框架引导搜索智能体通过模仿、对齐、泛化三个阶段,在过程奖励的指导下逐步内化提升查询质量的能力。
为了全面评估SmartSearch的能力,我们在四项具有挑战性的知识密集型任务和两项网络探索任务上进行了实验。实验结果表明,SmartSearch在整体性能上始终优于所有基线模型,并且在开放网络环境中表现出强大的泛化能力。此外,我们还进行了一系列消融研究和定量分析,凸显了我们的两个关键机制和三个课程学习阶段的重要作用,以及SmartSearch在搜索效率、查询质量和其他维度上的优势。
本文的主要贡献:
1
开创性地通过过程奖励引导来优化中间查询的质量,从而提高搜索智能体的信息获取能力。
2
设计了一个三阶段、面向查询的课程学习框架,该框架引导智能体从模仿、对齐到泛化,逐步内化提升查询质量的能力。
3
在六个具有挑战性的基准测试中进行实验,SmartSearch始终优于现有基线,进一步的定量分析证实其在搜索效率和查询质量等方面均有显著提升。
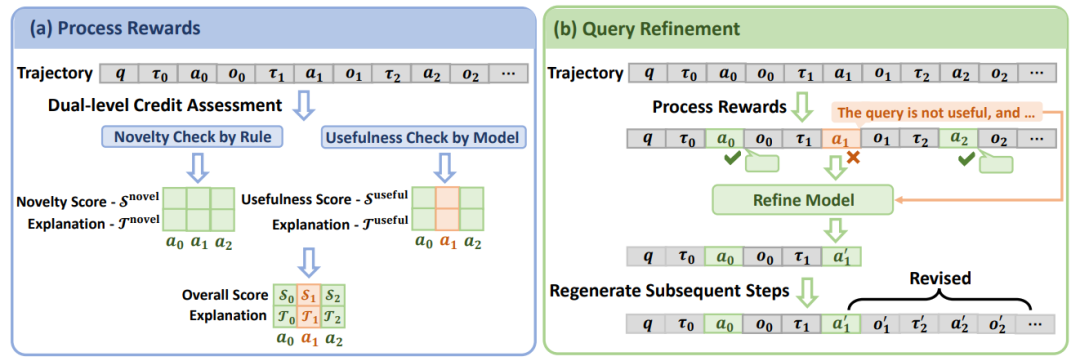
图2: SmartSearch中两个关键机制的概述:过程奖励(a)和查询优化(b)。
SmartSearch的两个关键机制:过程奖励&查询优化
如上图所示,SmartSearch包括两个关键机制:(1)过程奖励,它为查询的质量提供细粒度的监督,通过双重评估处理每个查询;(2)查询优化,该机制通过有选择地优化低质量查询,并基于这些优化后的查询重新生成后续搜索轮次,来促进查询生成的优化。
1
过程奖励机制
过程奖励机制用于评估每个查询的质量,并提供数值分数和文本反馈。这些输出会指导后续的查询优化,并在三阶段课程学习框架中发挥关键作用。
我们面对查询质量的双重评估包含两个互补的组成部分。
● 基于规则的评估:通过衡量当前搜索轮次与之前搜索轮次之间的文档重叠度来识别冗余查询。
● 基于模型的评估:评估查询意图的必要性,并检查检索到的结果是否提供了预期的答案。为提高效率,我们采用了一个由教师模型蒸馏得到的轻量级学生模型来执行评分和后续的查询优化任务。
最后,整体的评估分数及其相应的文字说明是通过汇总各项评估得出的。总分由各组成部分得分的逻辑合取决定,最终的文字说明通过拼接两个组成部分的文本反馈得到。
2
查询优化机制
查询优化机制旨在促进查询生成的优化,在三阶段课程学习框架中发挥着关键作用。它通过系统地识别和改进低质量查询,然后从这些优化后的查询重新生成后续的搜索步骤来实现。
具体来说,搜索智能体首先生成一条完整的轨迹。然后,该轨迹中的每个查询都通过过程奖励机制进行评估,得到一系列分数和相应的文本解释。对于每个低质量查询,会触发一个优化步骤。优化后的查询由语言模型根据用户的原始查询、截至当前步骤的轨迹以及低质量查询对应的文本反馈生成。搜索智能体随后根据这个优化后的查询重新生成后续的搜索过程,得到新的轨迹。初始轨迹和修正后轨迹的主要区别源于优化后的查询,从而在课程学习框架内促进查询生成的优化。
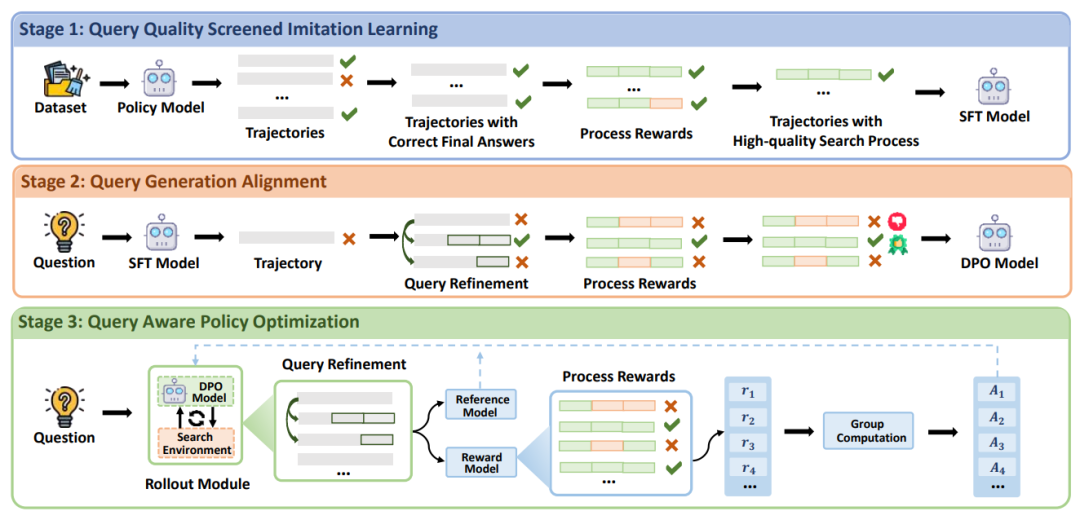
图3:面向查询的三阶段课程学习整体框架。
面向查询的训练框架
为了进一步内化提升查询质量的能力,我们提出了一个基于这些机制的三阶段课程学习框架。如图3所示,该框架包括查询质量筛选模仿学习、查询生成对齐和查询感知策略优化三个阶段。
1
查询质量筛选模仿学习
初始阶段通过监督微调在搜索智能体早期学习信息检索和利用时进行引导。训练数据会根据最终答案的正确性以及通过过程奖励衡量的查询质量进行筛选。这确保模型从不仅能得出正确答案、而且能保持高质量搜索过程的轨迹中学习。
2
查询生成对齐
在这一阶段,搜索智能体通过直接偏好优化培养高级查询生成能力。一方面,我们采用查询优化机制生成对比数据,对比数据的主要区别源于查询,从而促进查询生成的优化。另一方面,哪些轨迹质量更高由过程奖励和结果奖励共同定义,提供了更细粒度的监督。
3
查询感知策略优化
最后阶段利用强化学习进一步增强其信息检索和利用的综合能力。在Rollout阶段,我们采用查询优化机制,让一个组里的部分轨迹共享相同的前缀,促进查询生成优化的同时增强智能体的整体性能。在奖励设计方面,我们将过程监督整合到奖励函数中,让智能体尽量减少成功轨迹中的低质量查询;即使无法提供最终的正确答案,也尽可能生成高质量查询,逐步接近解决方案。
实验
表1展示了主要结果,表明SmartSearch在四个数据集上始终优于现有方法,并得出了一些重要见解:(1)基于提示词的方法表现有限;(2)有效地纳入过程奖励能显著提升强化学习训练的效果;(3)优化中间查询的质量能显著提升整体性能。
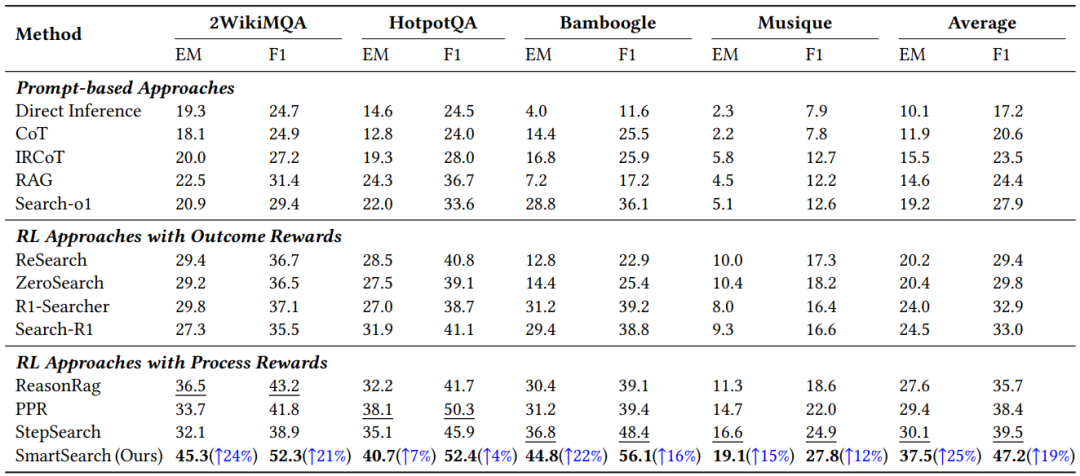
表1:模型在知识密集型基准上的表现。
如前所述,SmartSearch仅在基于维基百科的本地搜索上进行训练。为了评估其在网络搜索中的泛化能力,我们在两个高难度的网络探索任务(GAIA和WebWalker)上,将其与多个基线模型进行了测试。如表2所示,SmartSearch在两个数据集上均优于现有方法,平均F1分数提升了近5%。
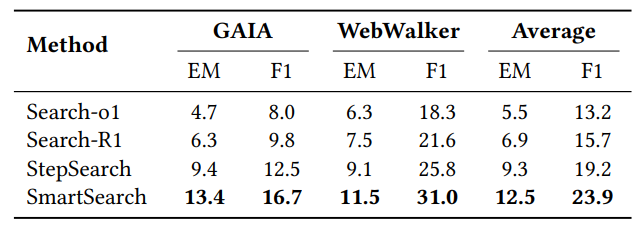
表2:模型在网络探索任务上的表现。
为了进一步研究SmartSearch的两个关键机制——过程奖励和查询优化的影响,我们在所有三个训练阶段进行了大量的消融研究。结果总结在表3中,体现了我们的两个关键机制和三个课程学习阶段的重要作用。
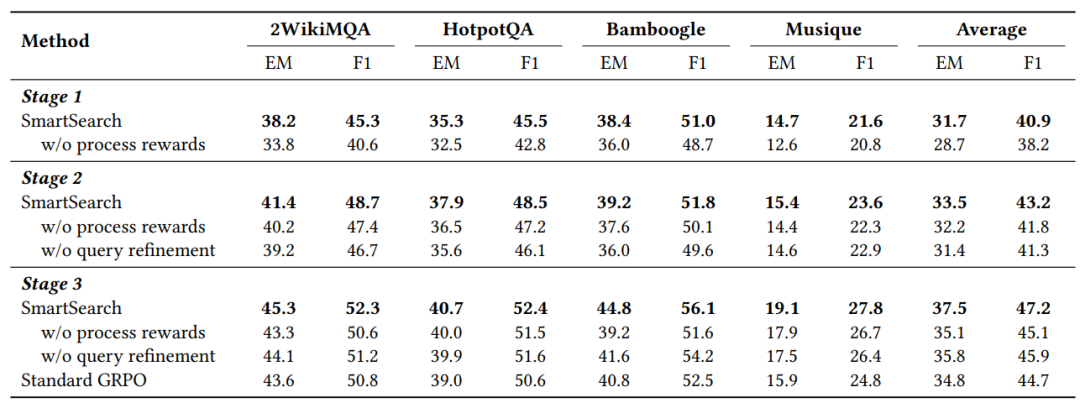
表3:在课程学习训练框架的所有三个阶段中,对SmartSearch中两种核心机制的
消融研究结果。
为了全面评估SmartSearch框架的有效性,我们进行了多项定量实验。图4和图5展示了其在四个关键方面的优越性:中间查询质量、搜索效率、过程奖励模型的有效性以及有效性与效率的权衡。
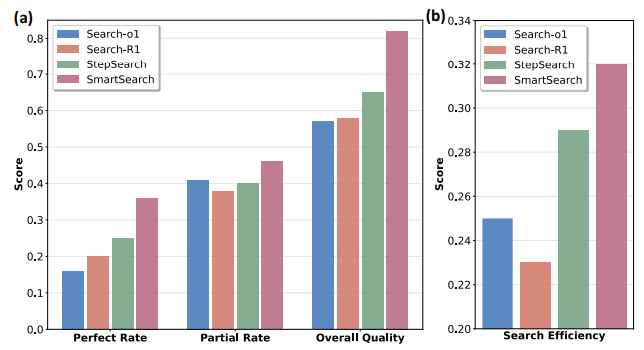
图4:(a)搜索查询质量对比。(b)搜索效率对比。
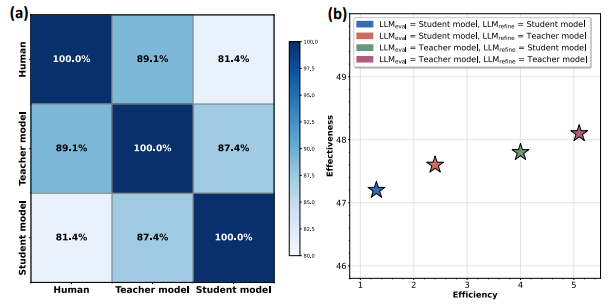
图5:(a)学生模型、教师模型和人工标注对查询所分配分数的重叠情况。
(b)SmartSearch中有效性与效率的权衡。
总结
本文提出了SmartSearch,这是一个旨在通过两种关键机制优化中间查询质量的框架:(1)过程奖励,通过双重评估为每个查询的质量提供细粒度监督;(2)查询优化,通过选择性地优化低质量查询并重新生成后续搜索轮次,促进查询生成的优化。在这两种机制的基础上,我们设计了一个三阶段课程学习框架,引导智能体从模仿、对齐到泛化逐步进阶,使其能够逐步内化提升查询质量的能力。在六个具有挑战性的基准测试上的实验表明,SmartSearch持续优于现有的基线模型,进一步的定量分析证实其在搜索效率和查询质量方面均有显著提升。
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号