信息来源:人大高瓴人工智能学院 发布时间:2025年12月1日
「硅基温度-牛导力荐」栏目,每周力邀一位AI领域的顶尖导师,从浩如烟海的论文中,亲自为您挑选一篇“必读好文”。它或许预示着一个崭新的方向,或许内藏着一个精妙的巧思。
在这里,让最具慧眼的领路人,带你穿透信息的迷雾,触摸AI未来的脉搏。
推荐人:卢志武
中国人民大学高瓴人工智能学院
教授 博士生导师

卢志武教授,研究方向为机器学习与计算机视觉。设计首个公开的中文通用图文预训练模型文澜BriVL,早于OpenAl发布类Sora的视频生成底座VDT,并因此获评南风窗2024年度科学家。指导学生获得CCF优博、百度奖学金、吴玉章奖、中国国际大学生创新大赛金奖。担任CCF生物信息学专委会委员、全国广播电影电视标准化技术委员会委员。担任ICML、ICLR等国际顶会的领域主席。
引言
AI 视觉模型虽擅长图像识别,却常因缺乏人类那样的多层级概念结构 “闹笑话”—— 比如把蜥蜴和植物归为一类。《Nature》新研究给出破局方案:通过 AligNet 框架,让模型学习人类从精细到宏观的认知逻辑,既精准贴合人类相似性判断,又大幅提升泛化能力和抗干扰性。这一突破让 AI 既 “懂人类” 又 “好用”,为更可靠的人工智能铺平了道路。
为什么需要对齐机器与人类视觉?如何构建更具有类人行为的系统?
即使是最先进的人工智能系统,依然会犯下人类绝不会犯的“低级错误”。这种现象迫使我们回归一个基本问题:神经网络到底缺失了人类智能的哪块拼图?
人类对世界的认知天然具备一张“全局抽象”的蓝图。这种认知是分层级的:
宏观层面(粗粒度):我们能轻易区分“动物”与“植物”共享“生物”属性,但互不从属。
微观层面(细粒度):我们能识别“波斯猫”与“暹罗猫”的具体差异。
这种从精细到粗糙、跨越多尺度的概念组织,让人类能够从局部细节自然过渡到全局语义。然而,当前的 AI 模型(尤其是视觉模型)往往存在“认知偏差”:它们是捕捉局部纹理和形状相似性的高手,却是理解层级概念的“矮子”。它们可能分得清猫的不同品种,却难以像人类一样,在脑海中构建出“猫 -> 动物 -> 生物”这样清晰的从属与并列关系。
传统的“堆数据”或“改架构”并不能从根本上解决这个问题。监督学习受限于预定义的死板标签,自监督学习则过度关注低层次的视觉特征。为了跨越这道认知鸿沟,AligNet 应运而生。

如何弥补AI与人类的认知偏差?
传统方法如增加训练数据规模或调整网络架构,虽能在特定任务上提升性能,却难以从根本上解决多层次抽象表示的对齐问题。
当前主流的学习范式存在固有局限。监督学习模型虽然在海量标注数据上表现出色,但其学习目标往往局限于在预定义类别间进行区分,无法自然形成人类那种从细粒度到粗粒度的概念层级。自监督学习方法虽然能学习到强大的特征表示,但这些表示仍然偏向于低层次的视觉相似性,而非语义上的概念关联。
多层次概念注入:AligNet方法
针对这一挑战,本文提出了AligNet方法框架,其核心思想是通过知识蒸馏的方式,将人类的多层次概念结构直接注入到预训练模型中。整个过程分为三个主要阶段:教师模型对齐、数据生成和蒸馏优化,该框架的流程如下图所示。
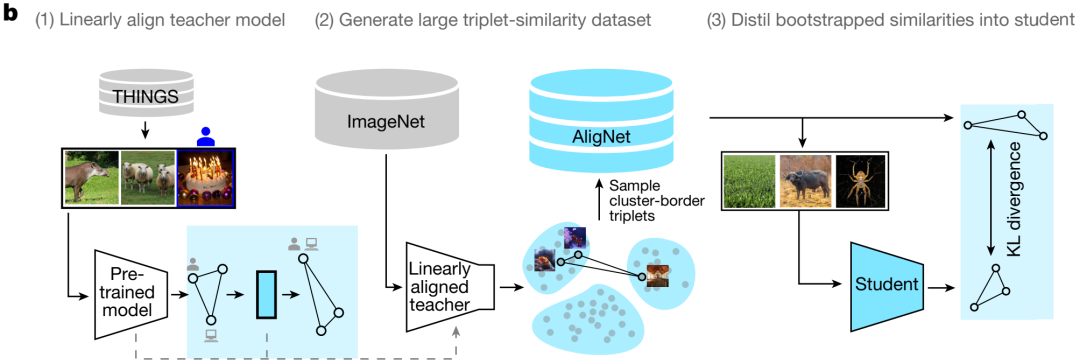
第一步:构建“懂人类”的教师模型
基础数据源:使用THINGS数据集,包含1,854个物体图像。每个三元组包含三个物体图像,人类需要从中选择最不相似的两个物体对,进一步构建全局相似性矩阵。
训练教师模型:通过学习仿射变换 ,将SigLIP-So400m教师模型的表征空间映射到人类相似性空间。两物体的相似性质定义为 。使用KL散度目标函数进行优化 。其中 为人类不确定性分布, 为模型概率分布, 控制局部相似性结构的保留强度。
第二步:基于语义层级的数据生成
使用对齐后的教师模型,从ImageNet中生成三元组数据并赋予软标签,构建AligNet数据集
超类聚类分析:在变换后的表征空间中对ImageNet训练集进行k-means聚类,通过Elbow准则确定最优簇数k。每个簇对应语义相关的超类(如"动物"、"交通工具")
三元组生成:智能三元组生成采用三种采样策略的有机结合,包含离散的odd-one-out选择、基于贝叶斯推理的成对相似性概率分布
聚类采样使得三元组更符合语义层次结构,图像根据语义关系分组
第三步:多架构知识蒸馏
所有学生模型都基于ViT结构,以确保可比性。学生模型包括多种预训练目标和架构
■监督学习模型:VIT-S/B/L(基于ImageNet)
■ 自监督学习模型:DINOv1、DINOv2.
■ 多模态模型:SigLLIP(图像-文本对比学习)、CapPa(图像描述生成)
蒸馏目标函数基于KL散度优化,比较教师模型生成的软标签与学生模型预测的相似性分布 其中softmax函数定义为 温度参数经过网格搜索优化( , ),这种非对称温度设计确保了知识的有效迁移。
上述流程构建的AligNet数据集核心优势在于其层次化语义注入机制,通过聚类驱动的采样和不确定性蒸馏,该方法成功将人类的多尺度概念结构嵌入到模型表示空间中。
AI真的更像人类了吗?
1. 与人类认知对齐
二维潜在空间投影上的表征变化
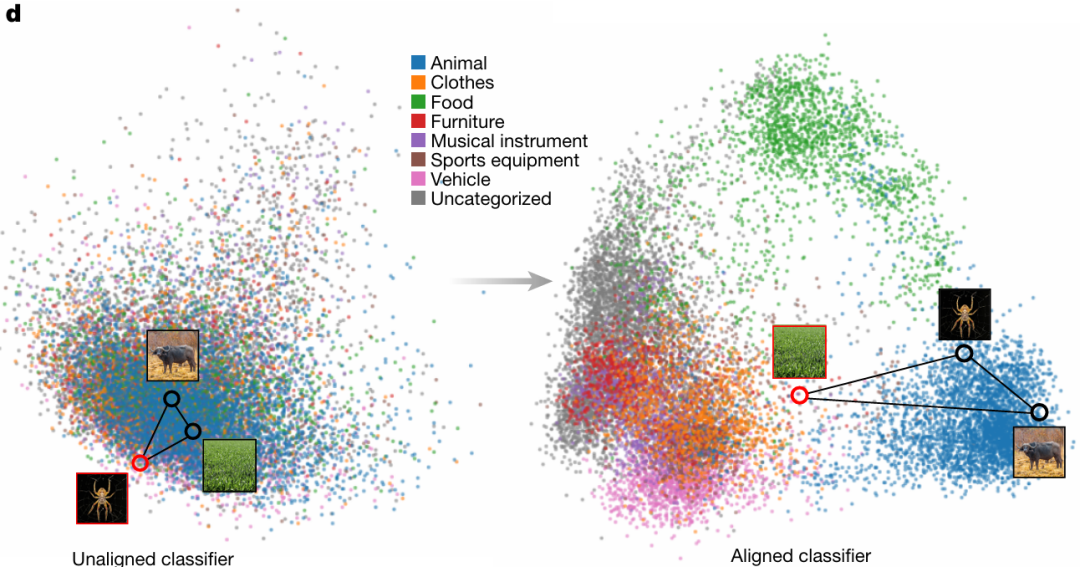
对齐前,标准 ViT-B 分类器的表征无结构化、类别重叠;对齐后,表征被重新组织为动物、衣物等有意义类别,边界更清晰。
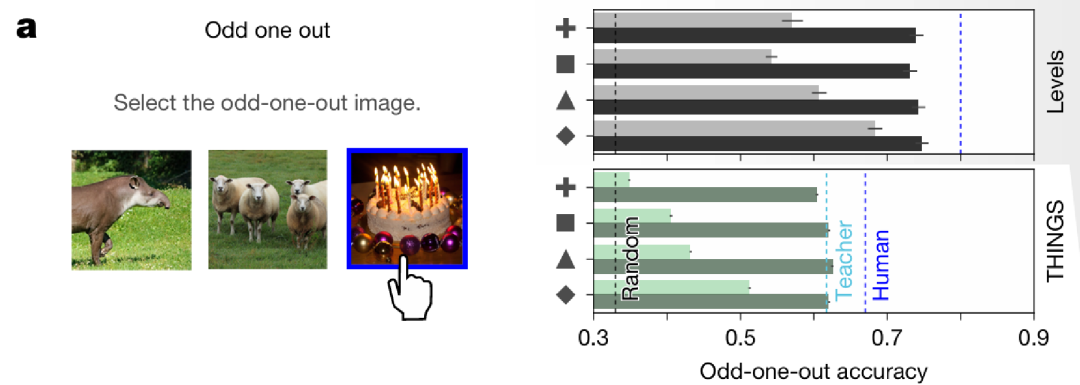
Triplet odd-one-out 任务
模型在 “三图选异常值” 任务中的表现(如从水牛、蜘蛛、草中选 “草” 为异常值),覆盖 THINGS 和 Levels 数据集。结果显示,AligNet 微调后模型的异常值识别准确率显著提升(相对提升最高 73.35%),证明其能泛化到人类基于语义相似性的基础认知判断。
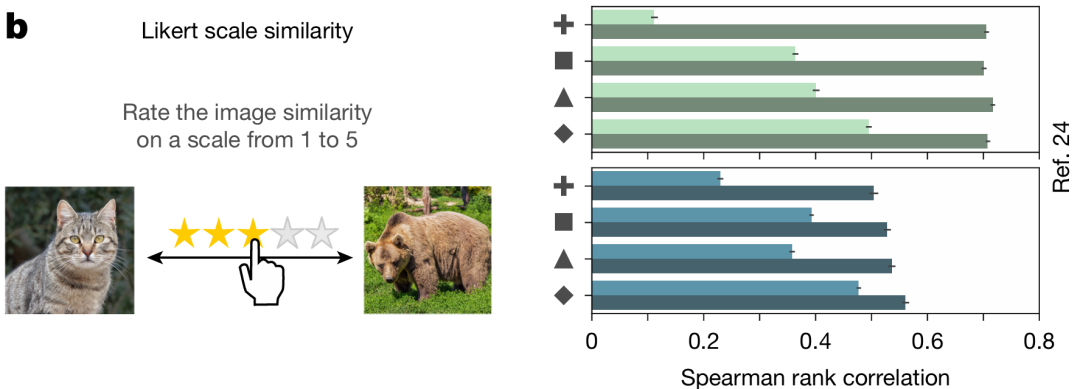
Likert 量表相似性评分
模型与人类 “1-5 分量表评分物体相似性” 的一致性,用斯皮尔曼相关系数衡量。AligNet 模型的相关系数最高提升 6.3 倍,说明其能泛化到人类主观、连续的相似性评估任务,而非仅离散判断。
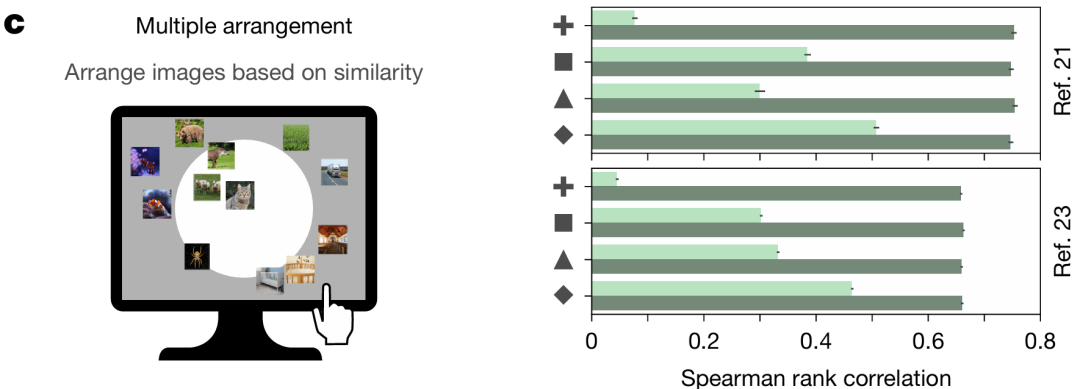
Multiple-arrangement 任务
模型与人类 “自由排列图像成语义聚类” 的一致性(人类会将 “狗、猫” 排近,“狗、桌子” 排远)。AligNet 模型的相关系数最高提升 14.47 倍,证明其能泛化到更复杂的 “全局语义结构组织” 认知任务,而非仅局部相似性判断。
突破性的全局语义理解(Levels 数据集多抽象层级任务)
为了验证 AligNet 的有效性,研究团队不仅使用了经典的 THINGS 数据集,更首创了 Levels 数据集,专门用于测试不同抽象层级的认知对齐。
研究团队共招募N=508名参与者来构建多层级相似性判断数据,每人接受不同的三元组选择,确保每个三元组在整个样本中呈现5次,总体包含三重抽象层次设计的三元组:
■ 粗粒度语义(Coarse-grained semantic):三个图像来自不同类别,要求在不同语义范畴间做出区分,评估模型对广泛语义范畴的区分能力(如"动物"与"交通工具")。
■ 细粒度语义(Fine-grained semantic):三个图像来自同一类别,需要识别细微的类别内差异,测试模型对类别内细微差异的敏感度(如不同犬种间的区别)。
■ 类别边界(Class boundary):两个图像来自同一类别,一个来自不同类别,测试模型准确识别类别边界的能力。
为确保数据质量,排除了
■在捕捉试验中正确率低于90%的参与者(N=19)
■ 在超过10个试验中未在限定时间内响应的参与者(N=9)
■ 因技术问题未完成实验的参与者(N=6)
■ 最终保留N=473名参与者的数据用于分析
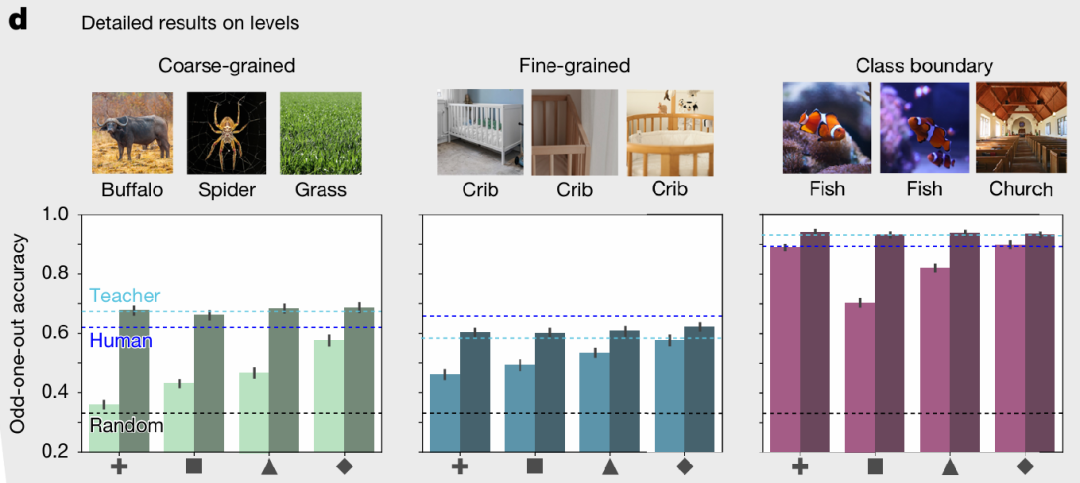
Levels数据集的三重抽象层次设计揭示了模型在不同语义粒度上的表现差异。在最具挑战性的粗粒度语义任务中,AligNet微调后的模型展现出突破性改进,其中ViT-L模型的准确率从37.89%提升至73.35%,相对改进达93.51%。更为重要的是,所有经过微调的模型在该层次上的表现(65.70%-68.56%)甚至超过了人类参与者之间的一致性水平(61.92%),证明AligNet成功赋予了模型理解全局语义关系的能力。在细粒度层次上,模型对类别内细微差异的敏感度也获得稳定提升,准确率提高7.84%-46.03%,而类别边界任务中的表现进一步优化,达到接近人类天花板的水平。
对齐前后模型表征的一致性变化
■ 对齐前:不同训练目标(如监督分类、自监督)的模型,表征结构差异显著,难以形成统一的语义组织逻辑。
■ 对齐后:所有模型的表征结构趋于相似,均向人类语义层级靠拢,体现了 AligNet 方法的通用性。
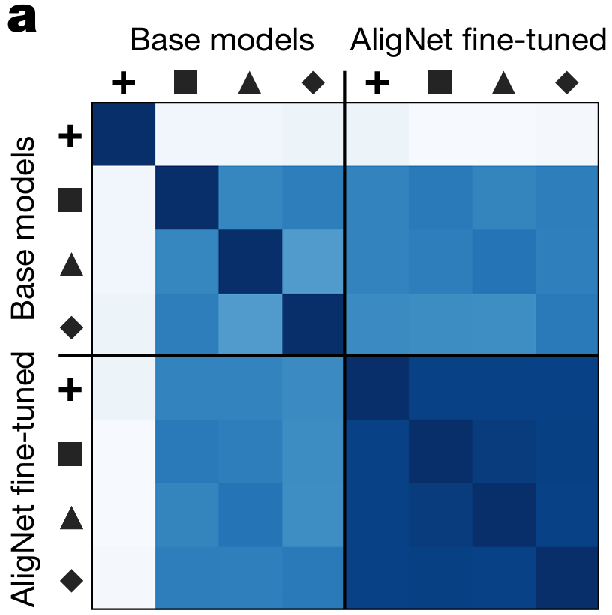
语义层级主导的表征距离调整
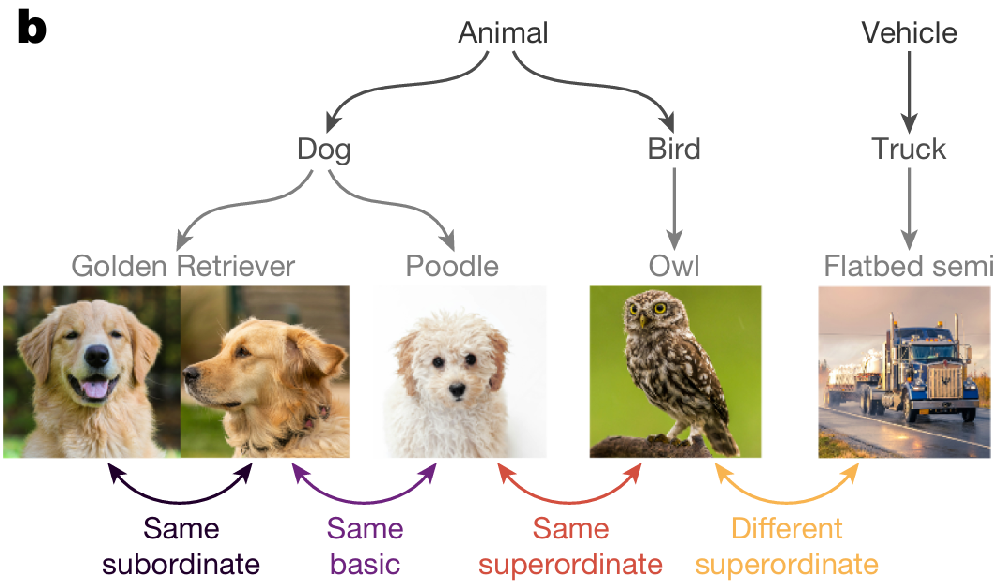
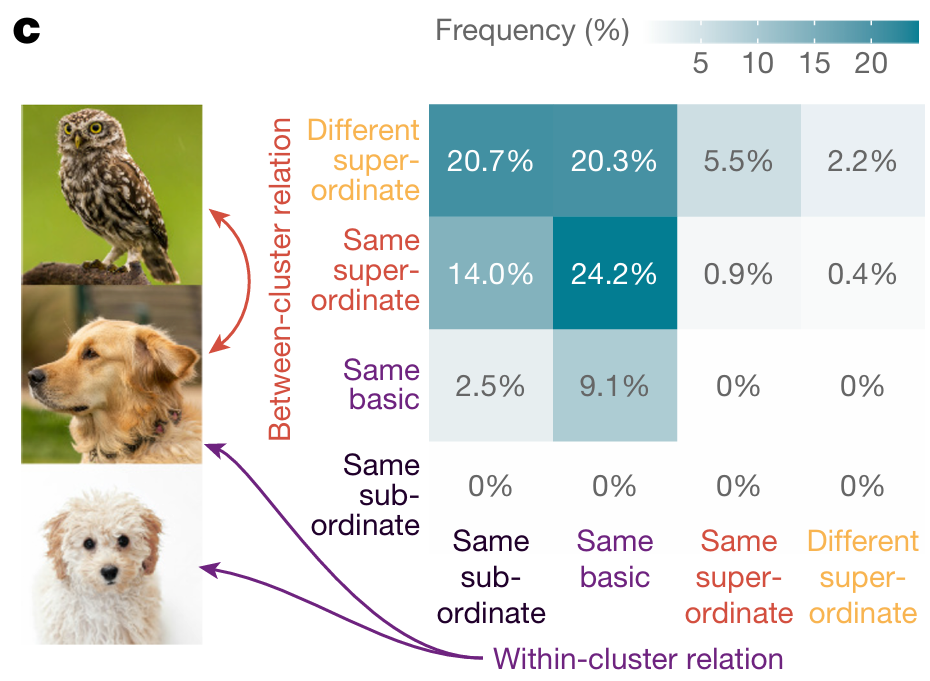
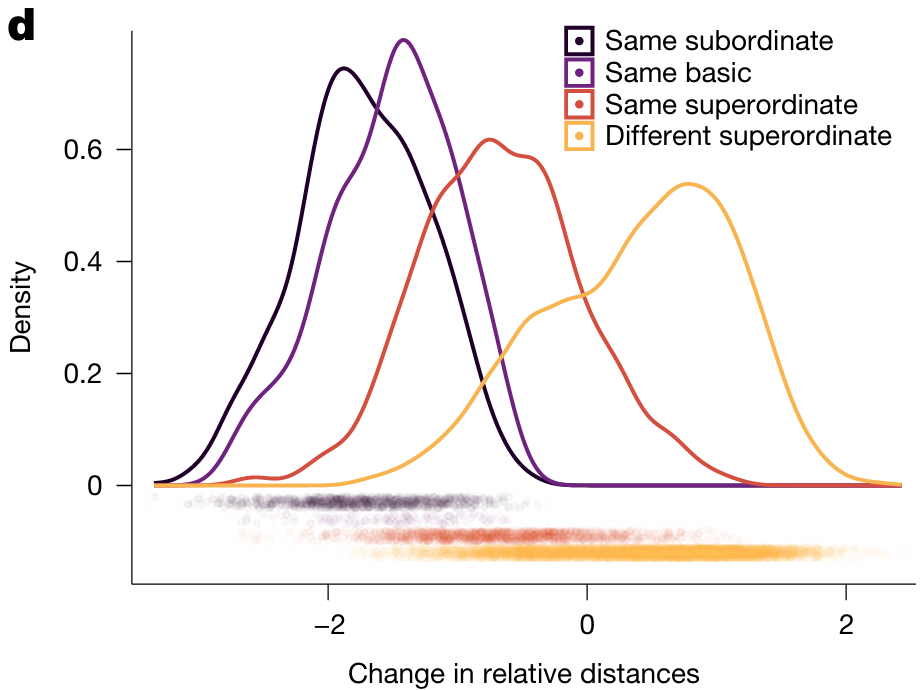
对齐后,图像表征的距离变化严格遵循语义关系——同子类、同基类、同超类的图像表征逐渐靠近,不同超类的图像表征逐渐远离(所有效果统计显著, , )。
2. 像人类一样“犹豫”
Levels数据集的一个关键创新是能够量化人类判断的不确定性:
■ 响应时间记录:收集人类响应时间作为参与者不确定性的代理指标
■ 熵值计算:使用离散香农熵计算每个三元组的响应分布熵值
■ 重复设计:每个三元组都由5名不同参与者完成,这允许基于群体水平计算可靠性指标
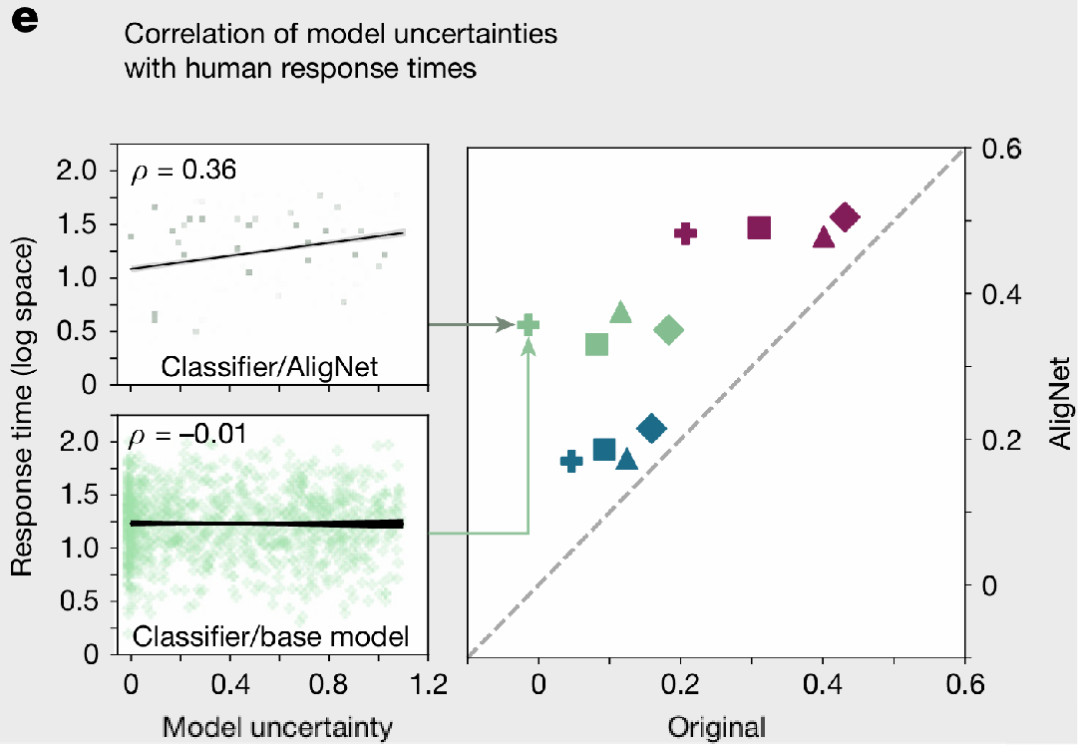
实验结果显示,AligNet不仅提升了任务性能,更使模型的内部决策过程趋近人类。模型不确定性估计与人类响应时间的相关性在粗粒度层次从微弱相关( )提升至显著相关( ),表明模型在面临困难判断时表现出与人类相似的“犹豫”模式。这种深层次的对齐证明AligNet能够模拟人类认知的不确定性特性,而不仅仅是表面行为上的模仿。
更像人类的AI是否更有用
除了人类对齐,研究团队还通过下游机器学习任务验证AligNet方法的实用价值,证明对齐后的模型在泛化和鲁棒性方面更具优势。
单样本分类表现
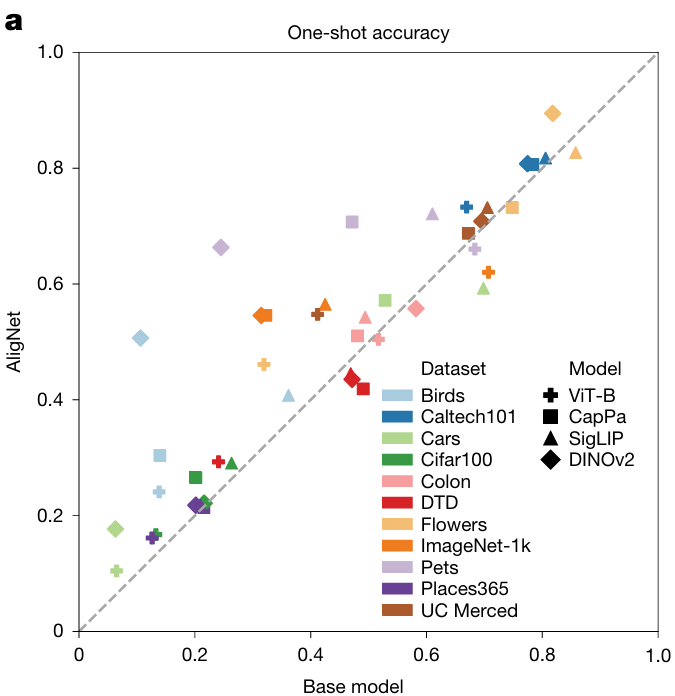
■ 任务设置:在极低数据设置下(每类仅1个标注样本),评估模型在10个多样化数据集上的性能,如ImageNet、Flowers、UC Merced等。
■ 结果:AligNet微调后,多数案例(32/40)显示性能提升(如下图所示)。例如,DINOv2模型在Pets数据集上准确率提升2.7倍。改进具有统计显著性( ),表明人类对齐表示支持小数据泛化。
分布偏移鲁棒性
■ 评估基准:使用BREEDS基准测试,专门测试训练集和测试集分布偏移下的泛化能力。
■ 结果:AligNet微调一致显著提升所有模型在BREEDS数据集上的性能(如下图所示),尤其对监督分类模型(如ViT-B)改进最大。这表明注入的全局语义结构有助于缓解分布偏移问题。
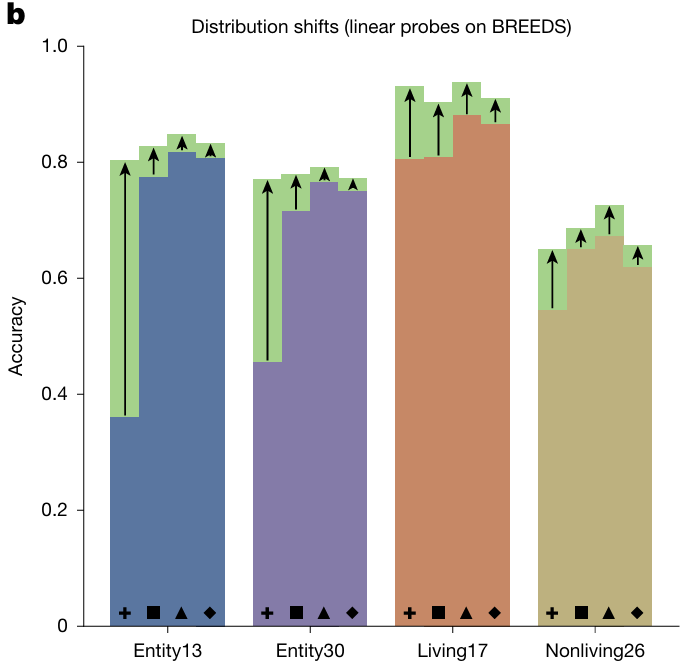
模型鲁棒性
■ 评估数据集:使用ImageNet-A(包含自然对抗样本),测试模型在挑战性条件下的鲁棒性。
■ 结果:AligNet模型在所有模型上显示准确率提升,最高达9.5个百分点。尽管方法非专门针对鲁棒性设计,但其改进与最先进鲁棒性方法相当。
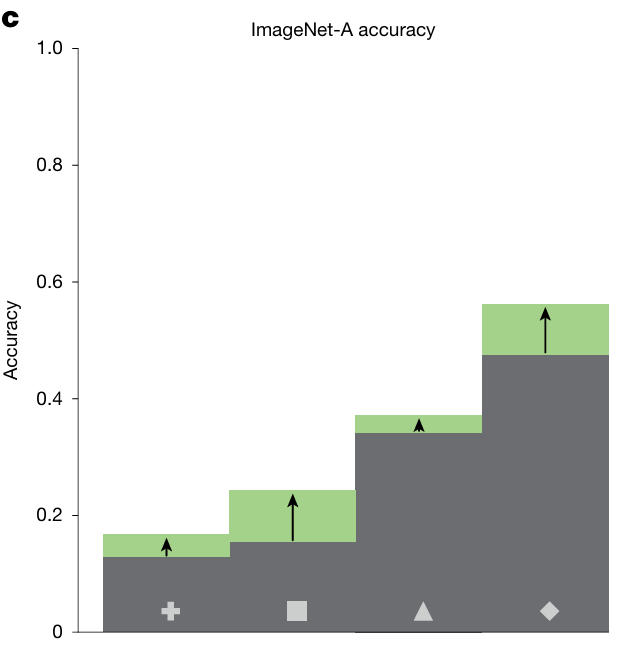
结语:迈向更可信的AI
AligNet所代表的"人类对齐"范式有望扩展到更广泛的AI领域。经过AligNet对齐的模型不仅在人类相似性判断任务上表现优异,在下游应用中也展现出更强的泛化能力和鲁棒性。这证明,拥抱人类认知特性不仅不会损害模型性能,反而能够提升其在真实世界中的实用价值。
从视觉到语言,从感知到推理,将人类的多层次认知结构注入机器学习系统,或许是我们迈向真正可信AI的关键路径。当机器能够以更接近人类的方式理解和回应世界时,我们才能建立起真正可靠、透明、可解释的人工智能伙伴。
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号