信息来源:人大高瓴人工智能学院 发布日期:2026年4月1日
「硅基温度-牛导力荐」栏目,每周力邀一位AI领域的顶尖导师,从浩如烟海的论文中,亲自为您挑选一篇“必读好文”。它或许预示着一个崭新的方向,或许内藏着一个精妙的巧思。
在这里,让最具慧眼的领路人,带你穿透信息的迷雾,触摸AI未来的脉搏。
论文信息:The Platonic Representation Hypothesis
作者:Minyoung Huh, Brian Cheung, Tongzhou Wang, Phillip Isola
论文链接:https://arxiv.org/pdf/2405.07987
推荐人:宋睿华
中国人民大学高瓴人工智能学院
长聘副教授 博士生导师

宋睿华老师是国家高层次人才特聘教授,曾任微软亚洲研究院主管研究员、微软小冰首席科学家。近期研究兴趣为多模态理解、创作和交互。发表学术论文100余篇,申请专利30余项。曾获2022年度教育部自然科学一等奖、WWW 2004最佳论文提名奖,AIRS 2012最佳论文奖,和MMM 2025最佳论文奖。她的算法完成了人类史上第一本人工智能创作的诗集《阳光失了玻璃窗》。2020-2022年作为学术带头人,发布文澜系列多模态预训练大模型,并成功落地快手、OPPO等企业。2023年,参与发布玉兰大语言模型,完成从基础模型到对话模型的自研训练。曾担任SIGIR短文和讲习班主席,ACL的领域主席,EMNLP的资深领域主席,和Information Retrieval Journal的主编。
引言:AI模型为何越来越"像"?
过去十年间,人工智能领域经历了一场静默而深刻的范式迁移。2014年,计算机视觉的主流架构是卷积神经网络CNN,自然语言处理依赖循环神经网络RNN;到了2024年,两个领域都几乎被Transformer架构统一了。不仅架构在趋同,模型的内部表征也在趋同——不同的模型、不同的训练目标、甚至不同的数据模态,正在以越来越相似的方式组织和理解数据。
这种趋势仅仅是偶然,还是存在更深层的规律?
MIT的Minyoung Huh、Brian Cheung、Tongzhou Wang和Phillip Isola提出了一个大胆的假说:
柏拉图表征假说(The Platonic Representation Hypothesis):
以不同目标、在不同数据和模态上训练的神经网络,正在其表征空间中收敛到一个共享的、关于现实的统计模型。
换言之,图像和文本都只是底层现实的不同投影。就像同一个三维物体可以在不同的墙面上投射出不同形状的影子一样,现实世界中的同一事件可以被相机捕捉为图像,也可以被人用文字描述下来。柏拉图表征假说认为,表征学习算法最终会穿透这些表面差异,收敛到对底层现实本身的共享表示——而模型规模、数据量和任务多样性的增长正是驱动这种收敛的力量(如图1所示)。
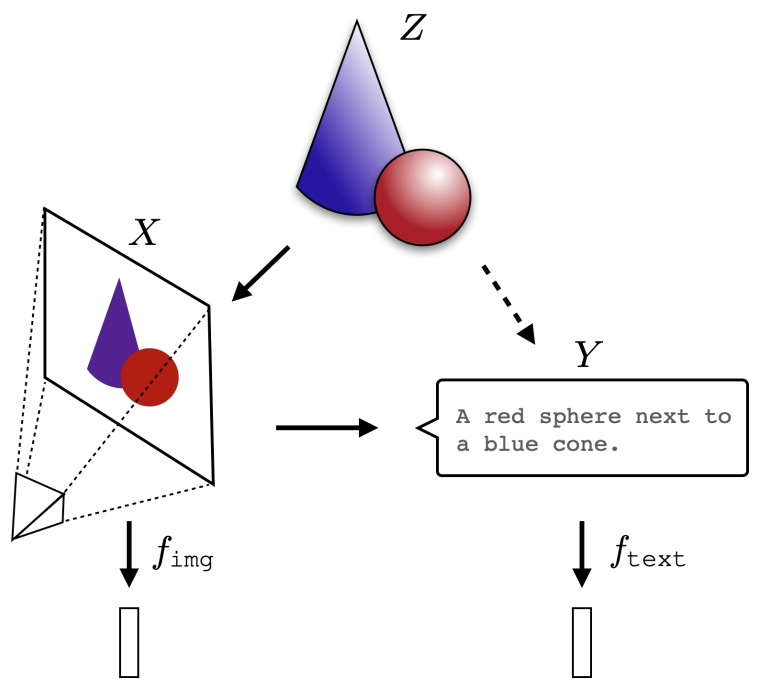
图1 图像(X)和文本(Y)都是底层现实(Z)的不同投影。柏拉图表征假说认为,表征学习算法将收敛到对Z的共享表示,而模型规模、数据量和任务多样性的增长驱动这种收敛。
这一假说的命名借鉴了柏拉图的"洞穴寓言"——我们的训练数据如同洞壁上的影子,而模型正在逐步恢复洞穴之外那个真实世界的表征。
核心证据:表征正在收敛
1.同模态内的收敛:强模型殊途同归
作者首先在视觉模态内部验证了收敛的存在。他们选取了78个视觉模型,涵盖不同架构(ViT、ResNet)、不同训练目标(ImageNet分类、MAE、DINO、CLIP)和不同数据集,使用互近邻度量(Mutual k-Nearest Neighbor, MNN) 衡量任意两个模型的表征对齐程度。
结果揭示了一个清晰的规律:模型能力越强,彼此之间的表征越相似。具体而言,在VTAB多任务迁移基准上能解决更多任务的模型,其两两之间的MNN对齐分数显著更高(图2左)。当把这78个模型的表征相似度嵌入到二维空间中可视化后,这一趋势更加直观——能力强的模型紧密聚集在一起,而弱模型则分散在四周,各自占据不同的位置(图2右)。
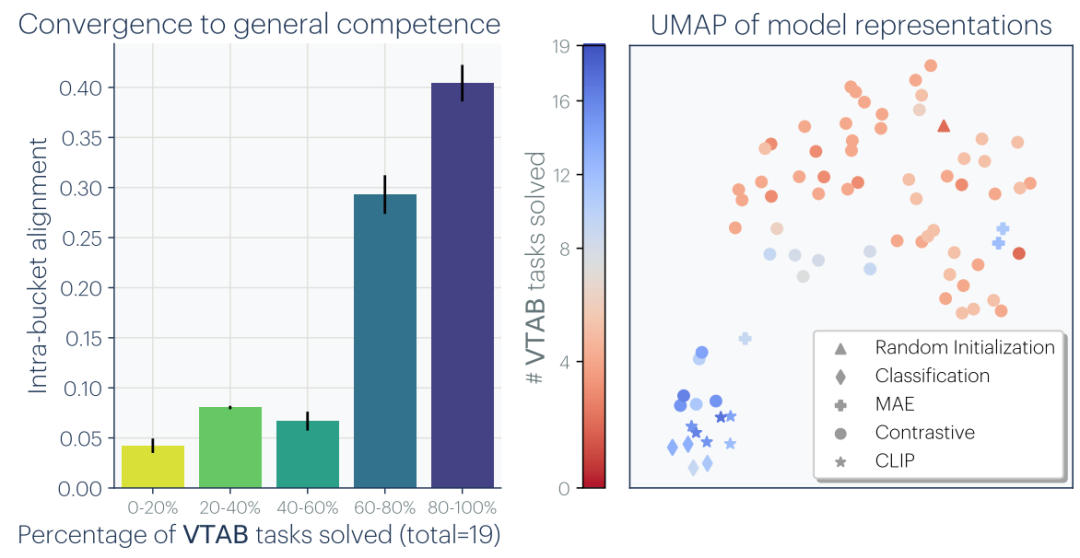
图2 (左):在VTAB多任务迁移基准上能解决更多任务的模型,彼此之间的表征对齐度更高。(右):将78个模型嵌入二维空间可视化。能力越强的模型(蓝色)聚集越紧密,弱模型(红色)则各有各的"弱法"。
这一发现呼应了Bansal等人提出的"安娜·卡列尼娜场景"——正如托尔斯泰所言"幸福的家庭都是相似的,不幸的家庭各有各的不幸",所有表现良好的模型都以相似的方式表征世界,而表现不佳的模型则各有各的"弱法"。
2.跨模态的收敛:视觉与语言的"不谋而合"
更令人惊叹的发现来自跨模态对齐实验。作者让纯视觉模型处理图像、纯语言模型处理图像对应的文字描述(来自Wikipedia图文数据集WIT),然后比较两种模型在各自模态上诱导的核(kernel)的相似度。
实验结果显示,跨模态对齐的程度与两边模型的能力均呈正相关,并且表现出清晰的线性趋势:更强大的语言模型与更强大的视觉模型之间的对齐度更高(图3)。这意味着语言和视觉这两条独立的优化路径,正在自发地走向同一个表征目标。
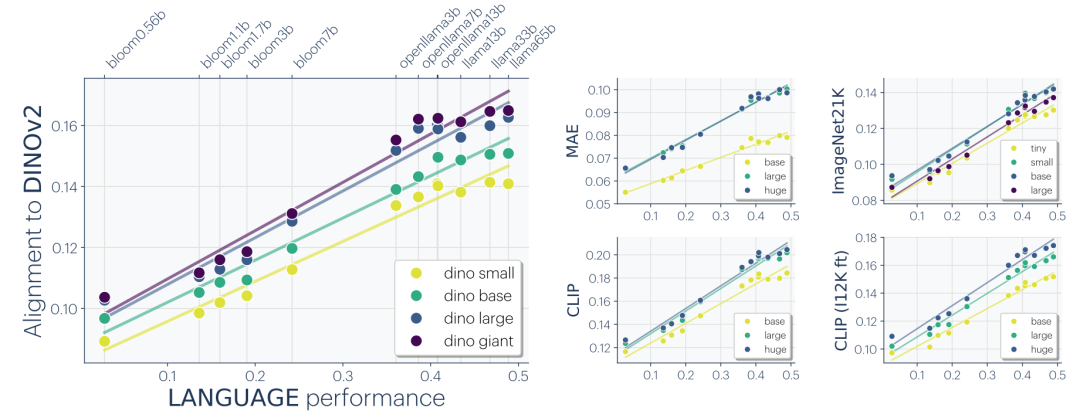
图3 横轴为语言模型的性能(1 - bits-per-byte),纵轴为与不同视觉模型的对齐分数。更强大的语言模型与更强大的视觉模型之间的对齐度更高,且呈现出清晰的线性趋势。
关键发现:
语言模型越大、性能越好,与视觉模型的对齐度越高
视觉模型越大、性能越好,与语言模型的对齐度越高
CLIP(带有语言监督信号的视觉模型)表现出更高的对齐度,但在ImageNet上微调后对齐度反而下降——这表明专门化可能削弱通用对齐
3.与大脑的对齐
神经网络与生物大脑之间也存在显著的表征对齐。尽管计算基质完全不同(硅基 vs 碳基),但模型和大脑面对的根本问题是相同的:从图像、文本、声音等信号中高效提取底层结构。研究表明,模型在视觉任务上的性能越好,其表征与大脑视觉皮层的对齐度就越高。
4.对齐度预测下游性能
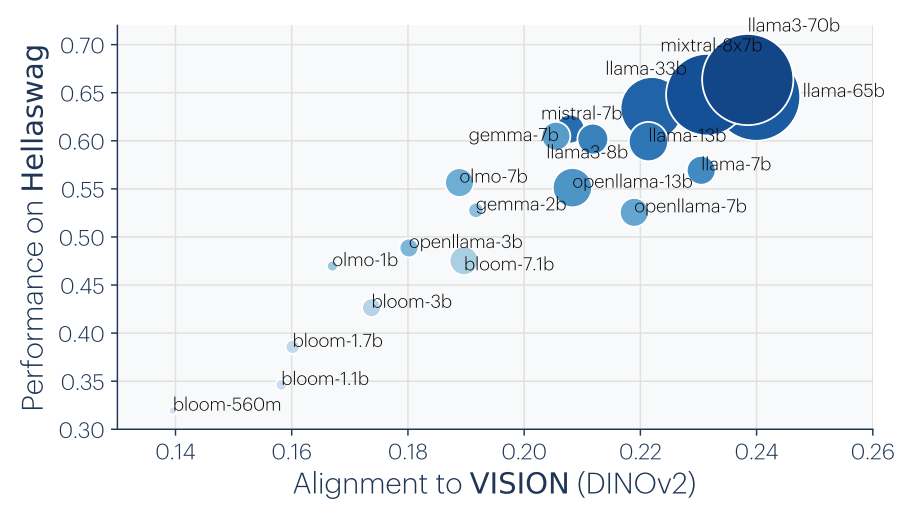
图4 对齐度与下游任务性能的关系
如果模型正在收敛到一个更准确的现实模型,那么对齐度应该与下游任务性能正相关。实验证实了这一预测:在常识推理(HellaSwag)和数学问题求解(GSM8K)等任务上,与视觉模型对齐度更高的语言模型确实表现更好(图4)。这说明表征对齐不仅仅是一个有趣的现象,它与模型的实际能力直接相关——越接近"柏拉图表征"的模型,泛化能力越强。
为什么会收敛?三重压力驱动
作者从机器学习优化的视角,识别了驱动收敛的三种核心压力:
1.任务通用性压力(Task Generality)
为什么要求模型解决更多任务会推动收敛?直觉上,每一个新的训练任务都是对模型表征的一个额外约束。随着需要同时满足的任务数量增加,能够满足所有约束的表征空间会越来越小(图5)。互联网规模的数据意味着海量约束——满足所有约束的表征集合必然非常狭小。
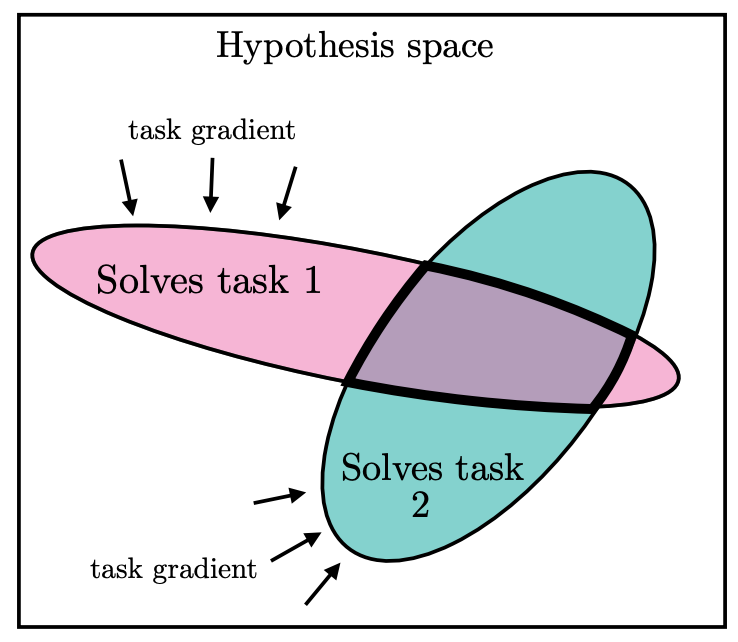
图5 随着训练任务数量增加,满足所有任务约束的表征空间越来越小。
多任务缩放假说:
能解决 N 个任务的表征数量,少于能解决 M < N 个任务的表征数量。当我们训练更通用的模型来同时解决更多任务时,可能的解空间必然更小。
这本质上是一个约束传播过程。不同的模型即使起点不同,当面临相同的大规模约束集合时,它们被"挤压"到了表征空间中同一个狭小的区域。
2.模型容量压力(Model Capacity)
第二个驱动力来自模型规模本身。如果存在一个全局最优表征,那么小模型由于假设空间有限,可能根本无法表达这个最优解,因此不同的小模型只能各自找到不同的次优解。而当模型变大时,其假设空间足够宽广,能够覆盖最优解所在的区域——于是不同的大模型即使出发点不同,都有可能到达同一个最优点(图6)。
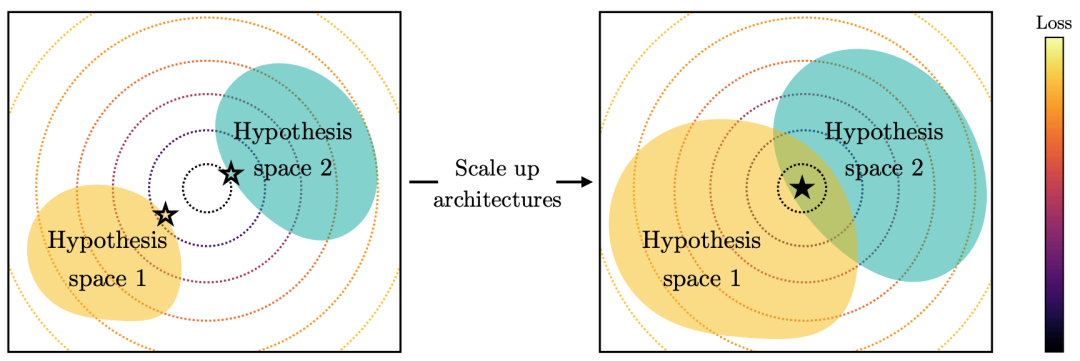
图6 (左)两个小模型的假设空间可能不包含最优解,因此找到不同的解。(右)当模型变大时,假设空间覆盖最优解,两个模型收敛到同一解。
容量假说:
更大的模型比更小的模型更可能收敛到共享的表征。
3.简洁性偏好(Simplicity Bias)
仅有大容量是不够的——更大的模型有更多拟合数据的方式,那为什么不会找到更多样的解,反而更趋同呢?答案在于深度网络固有的简洁性偏好。深度学习中的显式正则化(如权重衰减、Dropout)和隐式正则化(梯度下降的低秩偏好)共同推动模型趋向简洁解。模型越大,这种偏好在更宽广的假设空间中筛选后,收敛到的解空间反而更小(图7)。如果自然法则本身就是简洁的函数(正如物理学家所相信的那样),那么这种偏好恰好指向了正确的方向。
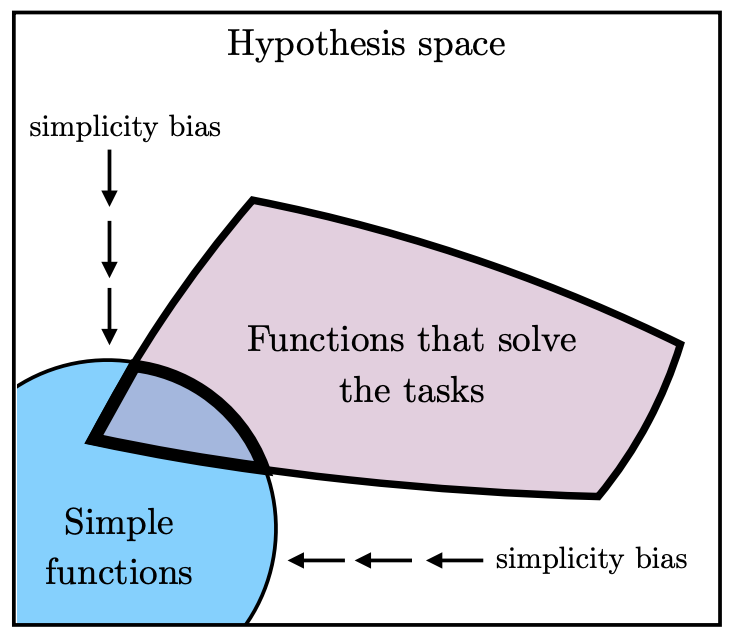
图7 更大的模型有更多拟合数据的方式,但深度网络的隐式偏好引导它们找到其中最简洁的那个解。
简洁性偏好假说:
深度网络偏向于找到数据的简洁拟合。模型越大,这种偏好越强。因此,随着模型变大,我们应预期收敛到更小的解空间。
收敛到什么?共现统计与PMI核
如果表征确实在收敛,那么收敛的终点是什么?
1.理想化世界模型
作者构建了一个优雅的形式化框架。设世界由一系列离散事件 Z = [z_1, ..., z_t] 组成,服从未知分布 P(Z)。每个事件可以通过不同的双射、确定性观测函数映射到不同的模态空间(像素、声音、文字等)。
2.对比学习收敛到PMI核
考虑一个对比学习器,它试图区分"正样本对"(时间上邻近的共现观测)和"负样本对"(随机抽取的独立观测)。作者证明,当模型充分优化时,学到的表征满足:
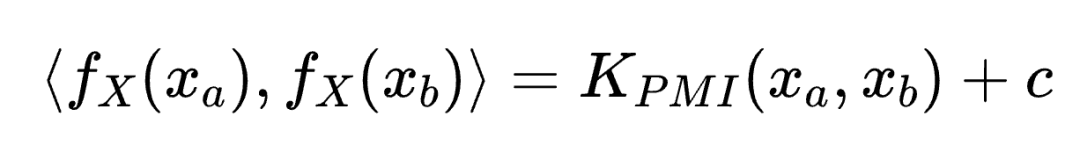
其中 K_PMI 是逐点互信息(Pointwise Mutual Information)核:
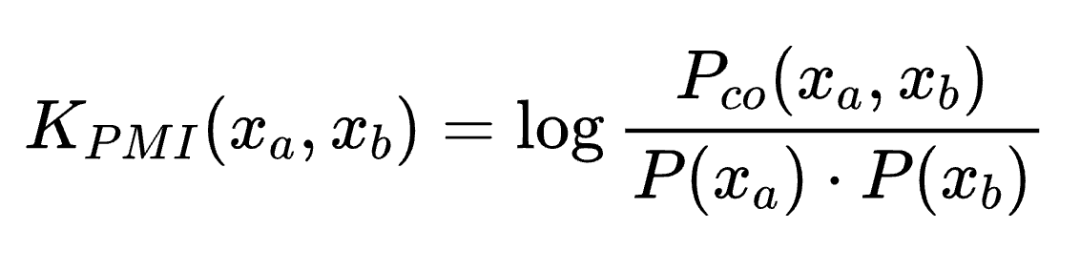
也就是说,对比学习最终学到的是:两个数据点在表征空间中的相似度等于它们的逐点互信息。
3.跨模态的不变性
由于观测函数是双射的,在离散随机变量上保概率:
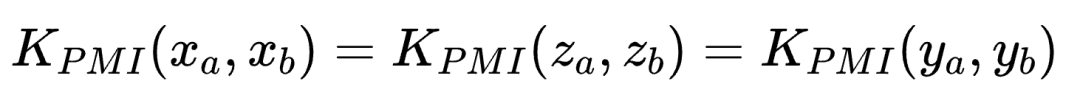
因此,无论在哪种模态上训练对比学习器,都将收敛到同一个PMI核——这就是柏拉图表征跨模态收敛的数学基础。
4.颜色案例研究
作者用一个直观的颜色实验为上述理论提供了精美的验证。他们分别从图像像素的空间共现关系和语言中颜色词的文本共现关系出发,让不同模态的模型各自学习颜色的表征。结果令人惊叹:视觉共现和语言共现恢复出了几乎相同的感知色彩空间结构(图8),与人类感知色彩空间(CIELAB)高度一致。
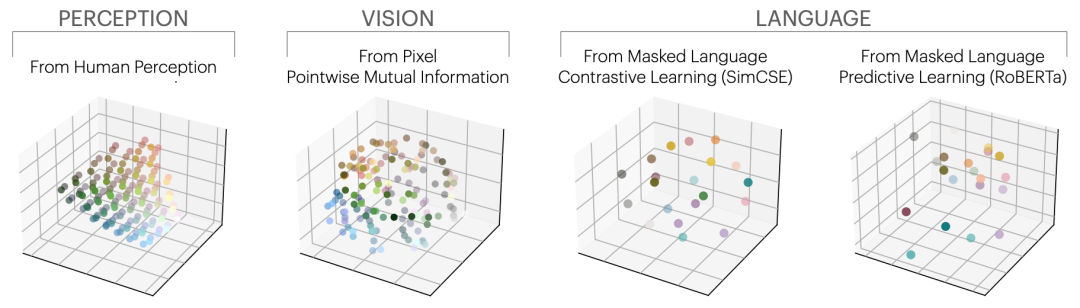
图8 从左到右依次为——CIELAB感知色彩空间、CIFAR-10图像中的像素共现统计学习到的颜色表征、以及语言模型(SimCSE和RoBERTa)学到的颜色表征。视觉共现和语言共现竟然恢复了几乎相同的感知色彩结构。
这正是不同模态收敛到同一底层现实统计结构的直接体现——无论是通过看到颜色还是阅读关于颜色的文字,模型都恢复了同一套关系结构。
深远启示
1.规模化是充分但非充要的
本文的论证与"规模即一切"的主张方向一致:随着参数量、数据量和计算量的增长,表征在收敛——不论建模选择甚至数据模态如何。但不同方法的效率不同,成功方法仍需满足基本要求(如作为一致估计量、能建模P(Z)的成对统计量)。
2.训练数据可跨模态共享
如果确实存在模态无关的柏拉图表征,那么要训练最好的视觉模型,不仅应该用图像训练,还应该用文本训练。反之亦然:训练最好的LLM,也应该在图像数据上训练。OpenAI的GPT-4V已经证实,在图像上训练可以提升文本性能。
3.跨模态迁移变得容易
当两个表征对齐时,它们之间的转换应该是一个简单的函数。这或许解释了为什么条件生成比无条件生成更容易、为什么LLaVA仅需一个2层MLP就能将视觉特征投影到语言模型中取得卓越效果,以及为什么无配对数据的跨域翻译(如CycleGAN)能够成功。
4.规模化或可缓解幻觉和偏见
如果模型确实在收敛到更准确的现实模型,我们有理由期待随着规模增长,幻觉会减少。同样,尽管大模型可能放大训练数据中的偏见,但更大的模型应该放大得更少——其偏见将更准确地反映数据的偏见,而非夸大它们。
局限性与反例
作者诚实地讨论了假说的局限:
1.不同模态可能包含不同信息
文字能否描述日全食的震撼体验?图像能否传达"言论自由"的概念?当观测函数非双射时,完全收敛的数学论证不再严格成立。作者通过实验发现,对图像的文字描述越详细、信息量越大,语言-视觉之间的对齐度就越高(图9)。这表明信息损失是跨模态收敛的主要瓶颈之一——如果一种模态无法完整表达另一种模态中的信息,完全收敛就不可能实现。
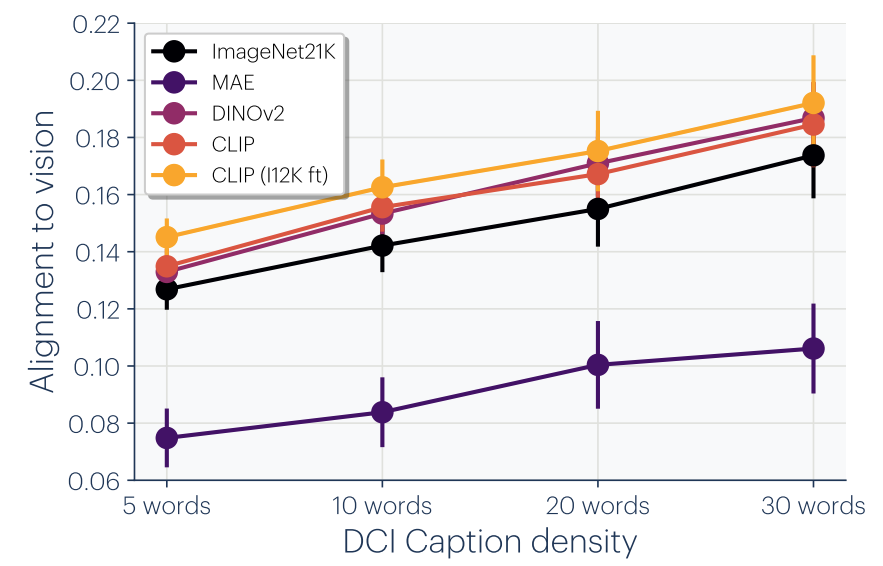
图9使用不同密度的图像描述测量跨模态对齐。描述越详细(信息量越大),语言-视觉对齐度越高—表明信息损失是跨模态收敛的主要瓶颈之一。
2.并非所有模态都已收敛
目前的证据主要集中在视觉和语言。机器人领域由于硬件成本高、数据获取困难,尚未观察到同等水平的收敛。
3.专用智能可能不收敛
该假说仅适用于被优化为在多个任务上表现优秀的系统。对于专门化的窄域任务,可能存在更高效的"捷径"表征。
4.社会学偏见
AI社区隐含地以模仿人类智能为目标,这可能导致人为的收敛趋势。
5.度量的局限
互近邻度量在最强实验中也仅达到0.16(理论最大值为1),这究竟代表强对齐还是弱对齐,仍是一个开放问题。
总结与思考
本文的核心贡献不在于某个特定的技术突破,而在于提供了一个统一的视角来审视AI表征学习中一系列看似独立的现象——模型拼接、零样本迁移、跨模态对齐、与大脑的相似性——并给出了一个优雅的理论解释。
柏拉图表征假说为我们理解AI的发展方向提供了一个引人深思的框架:
它为"Scale is all you need"提供了理论支撑,但同时指出效率仍然重要
它解释了为什么多模态训练能互相促进
它暗示了通用人工智能可能的形态——一个足够精确的现实统计模型
它提出了一种乐观的前景:随着模型变大变强,它们对世界的理解将越来越准确和一致
当然,这仍然是一个假说——一个需要更多实证和理论工作来验证或证伪的方向。但正如好的科学假说应该做到的那样,它为未来的研究指明了清晰的方向,并激发了关于AI本质的深层思考。
关于「硅基温度」系列文章
我们希望在当前信息爆炸、浅阅读盛行的环境中将大模型相关的知识冷凝萃取,输出专业、深度、高质量的硬核文章。我们期待与你一起在浮躁的时代静下心来,共品一杯“思想冷萃”。
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号