信息来源:人大高瓴人工智能学院 发布日期:2026年2月19日

论文题目
LawThinker: A Deep Research Legal Agent in DynamicEnvironments
作者
杨欣羽、邓琛龙、文同钰、谢缤雨、窦志成*
论文链接
https://arxiv.org/pdf/2602.12056
GitHub项目链接
https://github.com/yxy-919/LawThinker-agent
摘要
法律推理不仅要求得出正确的结论,还要求推理过程在程序上合法合规。然而,现有方法缺乏对中间推理步骤进行验证的机制,导致诸如引用不适用法条等错误在推理链条中传播而难以及时发现。为此,我们提出了LawThinker,一种面向动态司法环境的自主法律研究智能体,采用“探索-验证-记忆”(Explore-Verify-Memorize)策略。其核心思想是在每一次知识探索之后,将“验证”作为原子化操作强制执行。具体而言,DeepVerifier模块从知识准确性、事实与法条相关性以及程序合规性三个维度对每一次检索结果进行审查,同时结合记忆模块以支持长期任务中的跨轮知识复用。在动态基准J1-EVAL上的实验表明,LawThinker相较于直接推理方法提升了24%,相较于工作流方法提升了11%,在过程导向指标上表现尤为显著。在三个静态基准上的评估进一步验证了其良好的泛化能力。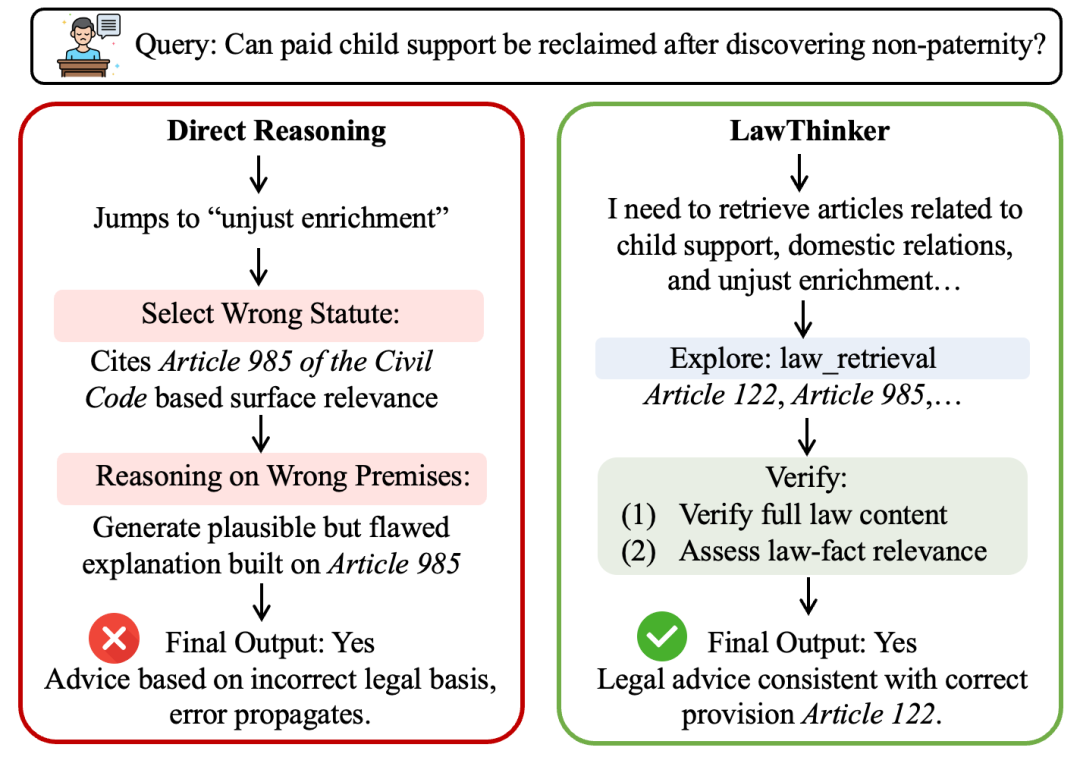
图1:一个由错误法条引用导致的错误传播示例。
引言
近年来,大型推理模型(LRMs)在数学、代码生成和科学推理等领域展现出强大的多步问题求解能力,这也推动了其在法律推理任务中的应用探索。然而,法律推理在本质上与其他领域存在关键差异:一个法律上有效的结论,不仅要求结果正确,还必须建立在准确且程序合规的推理过程之上。若引用了不适用的法条,或遗漏了必要的推理步骤,即便最终答案“碰巧”正确,整个法律分析仍然是有缺陷的。这一挑战在真实司法场景中尤为突出,法律咨询往往是多轮交互式对话,文书撰写需要跨轮次反复补充信息,庭审过程则必须严格遵循分阶段的程序流程。这些动态、交 互式环境对智能体在长时程推理中持续保持事实准确性与程序合规性提出了更高要求。
图1中的典型案例揭示了当前方法的局限性。当被问及“在发现非亲生关系后是否可以追回已支付的抚养费”时,直接推理方法基于表层关键词“不当得利”匹配,错误地选择了《民法典》第985条,并在此基础上构建出看似连贯的论证。虽然最终答案为“可以”,但其法律依据并不适用,正确的法条应为第122条。这一例子表明,法条选择阶段引入的错误并不会在后续推理中被纠正,而是被吸收进推理链条之中,使得最终结论看似合理却缺乏合法基础。更为关键的是,仅通过结果层面的评估难以发现此类问题,因为最终答案可能偶然正确。现有方法要么仅依赖参数化知识,容易产生幻觉;要么引入外部检索却缺乏对检索内容准确性与相关性的验证;即便有逐步验证机制,也多关注是否导向正确结果,而非推理过程是否符合 法律程序规范。因此,现有系统未能在整个推理过程中同时保障知识准确性、事实法条相关性与程序合规性。
为解决上述问题,我们提出了面向动态司法环境的自主法律研究智能体 LawThinker。该方法采用“探索-验证-记忆”(Explore-Verify-Memorize)策略,将知识探索与显式验证深度融合。当模型遇到知识缺口时,会自主检索相关法条、案例及程序规则;每一次检索后,均通过DeepVerifier模块进行核查,从知识准确性、事实关联性与程序合规性三个维度进行系统审查,并将结构化验证结果反馈至后续推理过程,从源头上阻断错误传播。同时,记忆模块会持久化存储经验证的法律知识与关键案情信息,以支持跨轮次、长时程任务中的稳定推理。我们在动态基准J1-EVAL以及多个静态法律基准上进行了系统评测。结果显示,LawThinker在J1-EVAL上相较于直接推理方法整体提升 24%,相较于工作流方法提升 11%,在格式遵循与程序遵循等过程导向指标上提升尤为显著;在庭审模拟场景中,其各阶段完成率亦显著领先。进一步在LawBench、LexEval与UniLaw-R1-Eval上的实验表明,其平均准确率较直接推理提升约 6%,验证了该策略在动态与静态法律任务中的良好泛化能力。
本文的主要贡献:
1
我们提出了LawThinker,一种面向动态司法环境的自主法律研究智能体,采用“探索-验证-记忆”策略。特别地,我们设计了DeepVerifier模块,从知识准确性、事实与法条相关性以及程序合规性三个维度对每一次探索步骤进行验证,从而在推理过程中有效防止错误的累积与传播。
2
我们设计了涵盖探索、验证与记忆三个维度的 15 种法律工具,使智能体能够在法律知识空间中自主导航,校验中间推理步骤,并在长时程任务中复用经验证的信息。
3
在涵盖六类司法场景的动态基准以及三个静态基准上的大量实验表明,LawThinker在结果指标与过程指标上均显著优于现有方法,尤其在程序合规性与庭审阶段完成率等方面取得了明显提升。
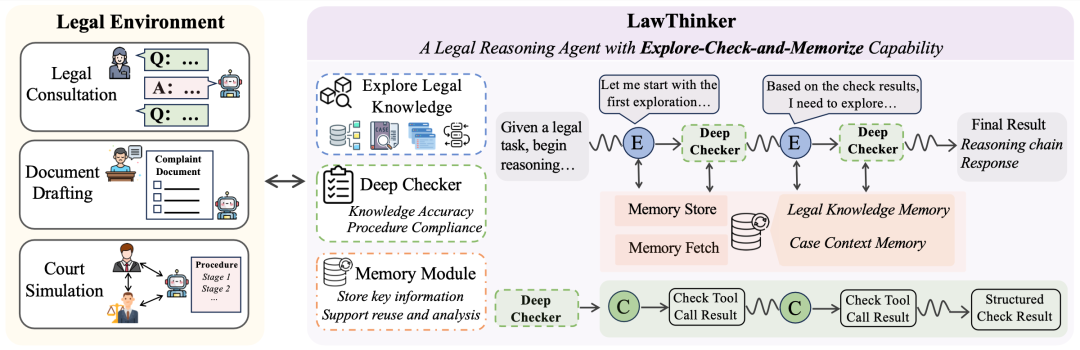
图2:LawThinker概览,采用“探索-验证-记忆”策略,在推理过程中集成迭代探索与验证,并与记忆模块紧密交互。
LawThinker框架介绍
1
任务定义
我们关注动态司法环境中的交互式法律任务。在此类场景中,法律智能体扮演特定司法角色(如律师或法官),与环境中的其他参与者进行多轮对话。在每一轮中,智能体基于当前对话历史和可用工具生成推理过程及相应回复,直至完成任务目标,例如解答法律咨询、撰写法律文书或完成司法程序。由于相关信息并非一次性给出,智能体需要在多轮交互中逐步获取关键知识与案件背景,当前推理依赖于此前各轮累积的信息,因此必须在长时交互过程中保持知识的准确性与合规性,避免早期错误在后续推理中不断放大。
为此,我们将每一轮的推理过程拆解为多个细粒度步骤。在每个步骤中,智能体可以调用探索工具获取外部信息,随后系统对该步骤进行专门验证,从知识准确性、事实与法律条文的相关性以及程序合规性等方面进行结构化评估。根据验证结果,智能体可以选择接受当前信息、修正推理逻辑,或重新构造查询并再次探索。通过在步骤级别实施验证机制,系统能够在错误扩散之前及时发现并纠正问题。
2
LawThinker框架
在此基础上,我们提出LawThinker框架,采用“探索-验证-记忆”的整体策略,如图2所示。其核心设计是在系统层面将“探索”与“验证”绑定为强制执行的原子操作,每一次探索之后都会自动触发验证模块,从而防止未经审查的信息直接进入后续推理流程。探索与验证可以在单轮对话中多次迭代,直至获得充分且经过验证的知识后再生成最终回复。同时,框架引入记忆模块,用于持续存储已验证的法律知识和关键案件信息,主推理模块与验证模块均可向记忆中写入内容,并在后续轮次中进行检索,以减少重复探索并提升整体推理的稳定性与效率。
该框架包含三项关键设计决策:
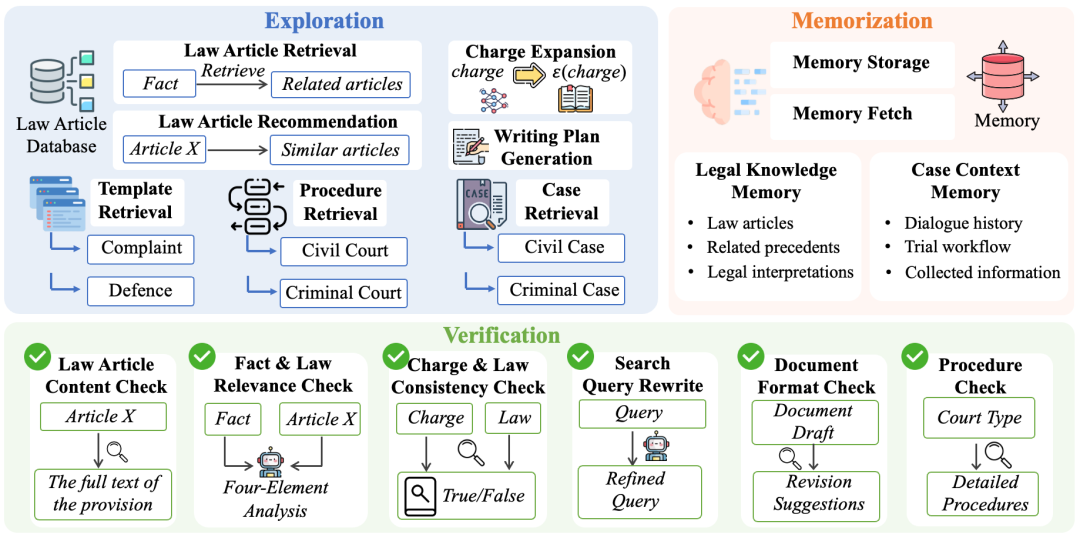
图3:探索、验证和记忆中所用工具概览。
“探索-验证-记忆”机制
我们设计了涵盖探索、验证与记忆三个维度的 15 种法律工具,如图3所示。接下来我们将详细介绍“探索-验证-记忆”机制中的内容:
1
法律知识探索
在法律知识探索过程中,我们将法律知识视为一个多源、紧密关联的结构化空间,而非扁平化的文档集合。为支持智能体在这一复杂空间中的系统化检索与推理,我们构建了一个综合法律知识库,包含法条、罪名、案例库,以及明确连接罪名与相关法条的法条–罪名映射字典。基于该知识体系,我们设计了七种探索工具,分为三类:
所有工具的调用均由智能体自主决策,根据推理过程中识别的知识缺口动态选择工具与构造查询,而无需预设触发规则或固定调用流程。
2
DeepVerifier:混合式的步骤级验证机制
传统自我反思无法访问外部权威事实,当模型生成虚构法条时难以自行发现错误;同时,其验证仍处于原有推理语境中,往往默认此前生成内容为既定前提,难以主动质疑。为此,DeepVerifier一方面通过“法条内容核查”等工具直接查询权威数据库,对引用法条进行真实性与完整性校验,提供独立于模型参数知识的硬性事实约束;另一方面采用独立的验证提示与角色设定,使验证过程在与主推理链分离的语境下进行,从批判性视角对每一步探索结果进行审查。围绕法律推理的核心要求,DeepVerifier 从三个维度开展验证:
六种工具结合“基于权威数据库的事实核查”与“基于明确标准的分析性推理”两种策略,在消除事实性错误的同时处理复杂法律判断。所有验证结果将结构化反馈至主推理链,由智能体自主决定继续推进、修正分析或重新探索。
3
记忆机制
在动态法律任务中,信息随着多轮对话逐步获取,智能体需要保留已验证的关键内容以供后续推理使用。为此,LawThinker 设计了记忆模块,包含两类内容:一是“法律知识记忆”,存储在推理过程中已探索并验证的法条、相关罪名、类案及法律解释等规范性信息;二是“案件情境记忆”,存储具体任务相关的信息,如对话历史、当事人身份、争议焦点、证据情况以及庭审流程进展。这种划分体现了两类信息的不同作用:法律知识提供规范依据,案件情境则为推理提供具体语境。
记忆模块通过记忆存储和记忆获取两个工具实现交互,智能体可根据推理需要自主决定何时存储与检索。主推理智能体主要存储案件相关的情境信息,而 DeepVerifier则负责存储经验证的法律知识,如确认无误的法条内容或已核实的事实-法条映射关系。该双通道机制确保进入记忆的法律知识均经过验证,从而避免未核实信息在后续推理中被再次引入。
实验
表1展示了主要结果:(1)直接推理在复杂场景下因幻觉问题和缺乏程序意识而表现较差;(2)引入外部知识但缺乏系统性的验证机制难以保证法律推理的准确性与程序合规性;(3)通过探索-验证-记忆策略进行结构化的探索与步骤级的验证,在准确率和过程性指标上均取得最佳表现。
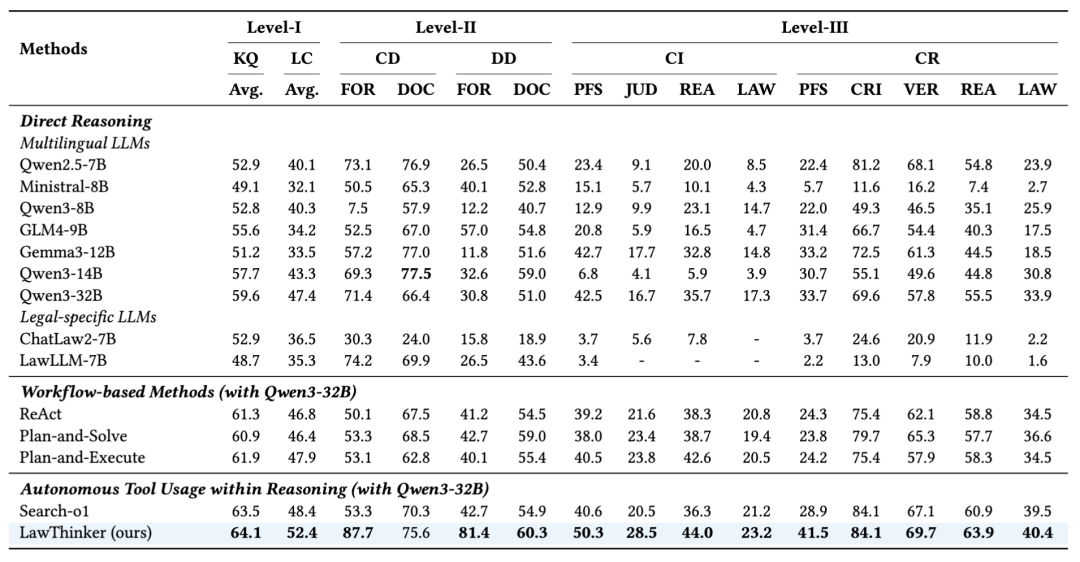
表1:模型在J1-EVAL基准的六类场景上的表现。
为了验证LawThinker的泛化性,我们在三个法律基准(LawBench、LexEval、Unilaw-R1-Eval)上将其与多个基线方法进行对比分析。如表2所示,LawThinker在三个数据集上都表现很好,相比直接推理方法平均提升了约6%的准确率,验证了其在静态法律场景上的有效性和泛化能力。
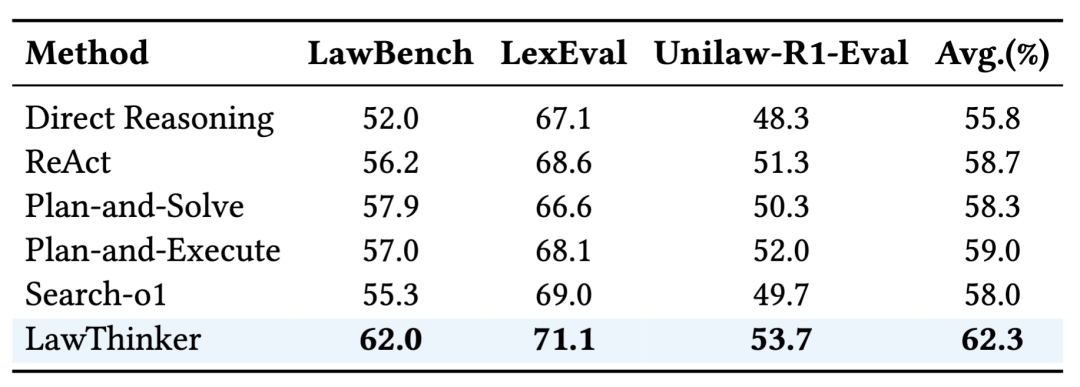
表2:LawThinker在不同法律基准上的表现。
为了研究LawThinker中探索、验证与记忆的重要性,我们进行了消融实验。结果如图4所示,DeepVerifier对整体性能至关重要,尤其是在知识密集型与程序要求严格的任务中,说明步骤级验证能有效减少幻觉与推理错误;记忆模块对长程任务贡献显著;总体来看,探索、验证与记忆三者协同策略带来最大性能提升。
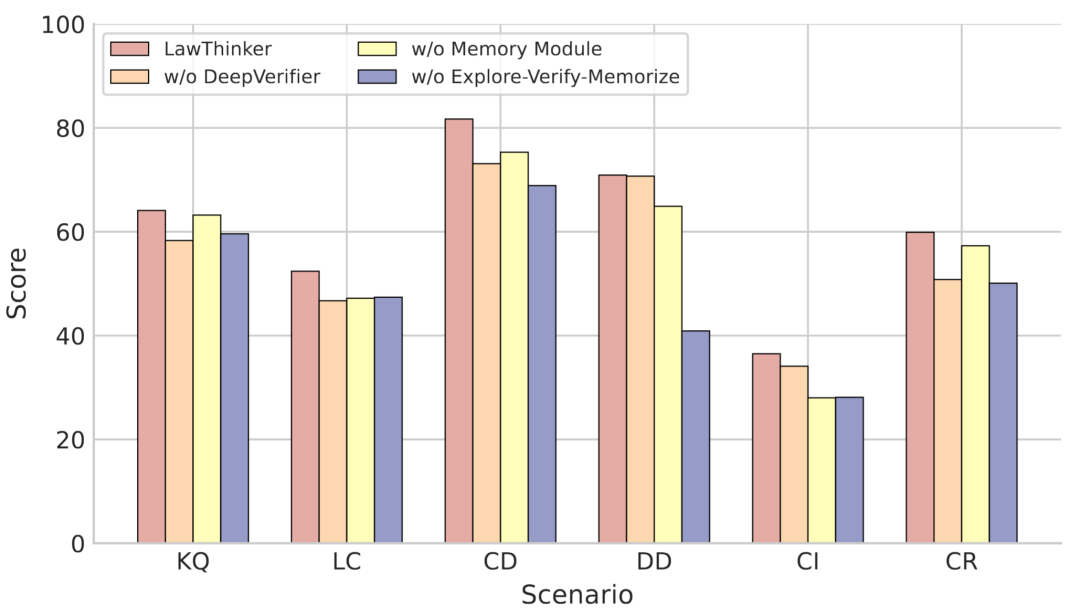
图4:在六个法律场景中的消融实验结果。
为了全面评估LawThinker,我们从结果准确性和过程合规性两个维度进行分析。结果如图5所示,LawThinker在两项指标上均最优,不仅提升了最终结果的正确率,也显著增强了推理过程的程序合规性。庭审流程完整性的分析结果如图6所示,LawThinker在民事与刑事各阶段的完成率均为最高,尤其在准备和调查等细粒度阶段优势明显。
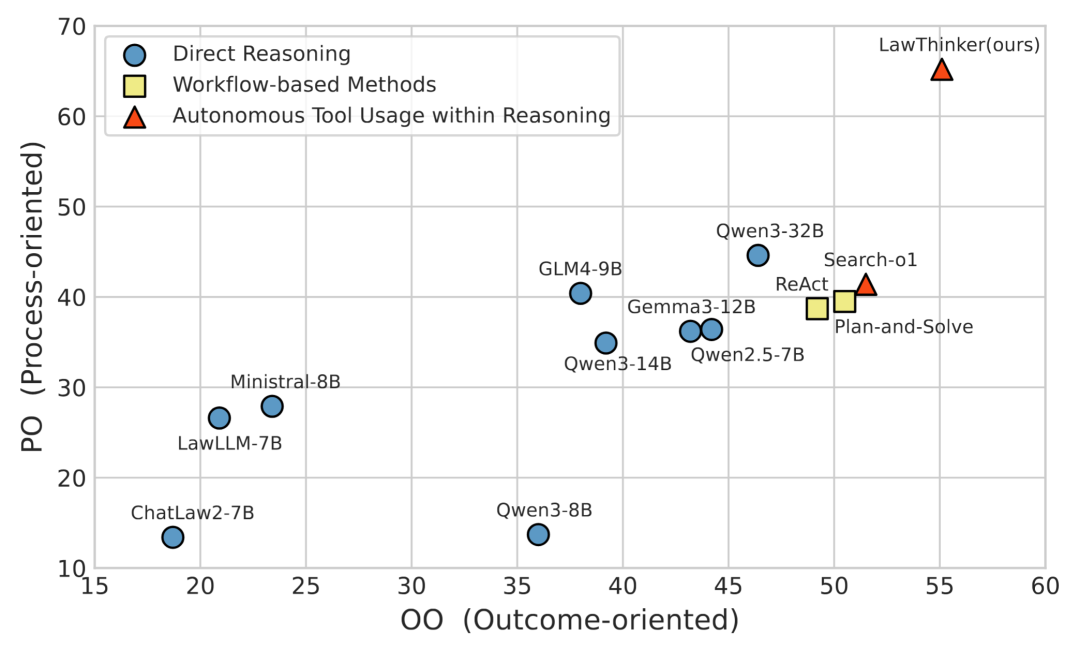
图5:各模型及推理范式在面向结果和面向过程指标上的表现。
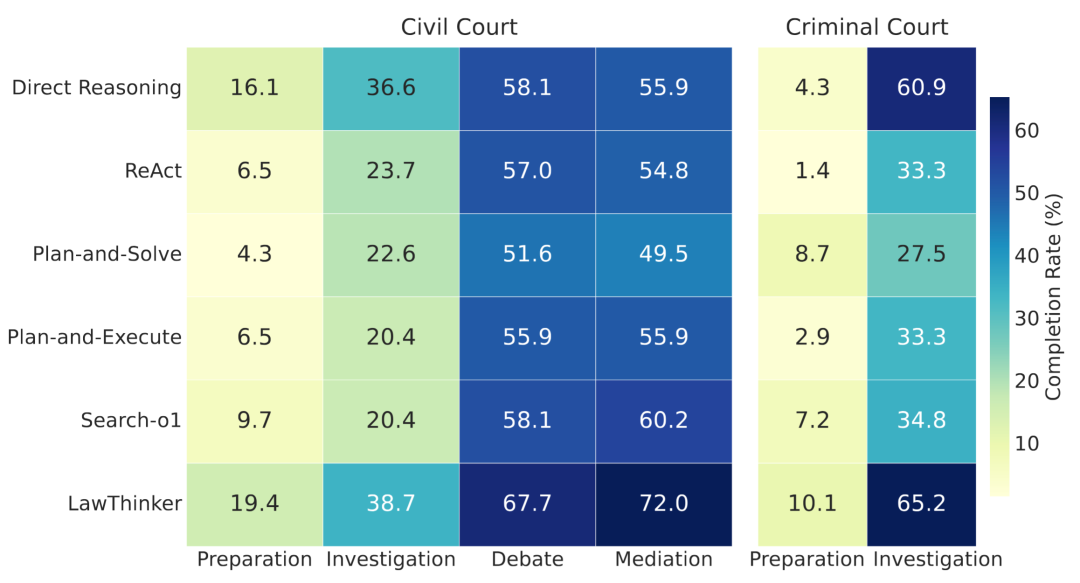
图6:不同方法的阶段完成率。
总结
本文提出了LawThinker,这是一种面向动态司法环境的自主法律研究智能体。该系统采用探索-验证-记忆策略,将迭代式知识探索与显式步骤级验证相结合,并设计了覆盖探索、验证与记忆三大模块的 15 种专用工具,实现对法律知识的系统化获取与严格校验。实验结果表明,无论在动态法律基准还是多个静态基准上,LawThinker均显著优于现有方法,不仅提升了最终结果的准确性,也确保了推理过程的合法性与程序合规性。
Copyright ©2016 中国人民大学科学技术发展部 版权所有
地址:北京市海淀区中关村大街59号中国人民大学明德主楼1121B 邮编:100872
电话:010-62513381 传真:010-62514955 电子邮箱: ligongchu@ruc.edu.cn
京公网安备110402430004号