
信息学院金琴教授团队多篇长文被ACM Multimedia 2021和ACL 2021 录用

中国人民大学信息学院多媒体计算实验室金琴教授团队2篇长文被多媒体领域顶级会议ACMMM 2021(main conference)录用,另有2篇长文被自然语言处理领域顶级会议 ACL 2021 (main conference) 录用。ACM 国际多媒体会议(ACM International Conference on Multimedia)是计算机科学领域中多媒体领域的首要国际会议,是CCF-A类推荐会议,每年举办一次。ACMMM 2021将于2021年10月20日-24日在中国成都举办。计算语言学协会年会 (ACL Annual Meeting of the Association for Computational Linguistics) 是计算语言学和自然语言处理领域的顶级国际会议之一,由国际计算语言学协会组织,每年举办一次,是CCF-A类推荐会议。ACL 2021 将于2021年8月1日至6日在泰国曼谷举办。


论文题目:Question-controlled Text-aware Image Captioning(ACMMM 2021)
作者:胡安文,陈师哲,金琴
通讯作者:金琴
论文概述:

对于一张包含了许多文字信息的图片,不同的人感兴趣的文字信息可能是不同的。然而目前对于图片文字敏感的图像描述模型并不能根据不同的信息需求生成个性化的描述。为了研究如何生成个性化的关于图片文字的描述,我们定义了一个新的具有挑战的任务,名为“问题控制的图片文字敏感的图像描述”(Qc-TextCap)。这个任务采用问题作为控制信号,要求模型首先理解问题,然后找到对应的图片文字,最后结合图像中的对象用流利的人类语言描述出来。我们基于已有的两个“图片文字敏感的图像描述”数据集自动构建了两个适合Qc-TextCap的数据集:ControlTextCaps和ControlVizWiz。我们进一步提出了一个新颖的对空间位置和问题敏感的模型(GQAM),可以逐步地编码相关的视觉特征和文本特征以支持最后的描述生成。考虑到图像中对象区域和文字区域的空间关系,GQAM首先应用一个空间视觉编码器去融合相关的视觉特征。然后使用问题导向的编码器为每个问题挑选最相关的视觉特征。最后,GQAM使用一个多模态解码器生成图像描述。我们的模型在两个数据集上的效果都超过了基准模型。通过问题作为控制信号,我们的模型可以得到更加多样,更有信息量的图像描述。
论文题目: Product-oriented Machine Translation with Cross-modal Cross-lingual Pre-training(ACMMM 2021)
作者:宋宇晴,陈师哲,金琴,罗维,谢军,黄非
通讯作者:金琴
论文概述:
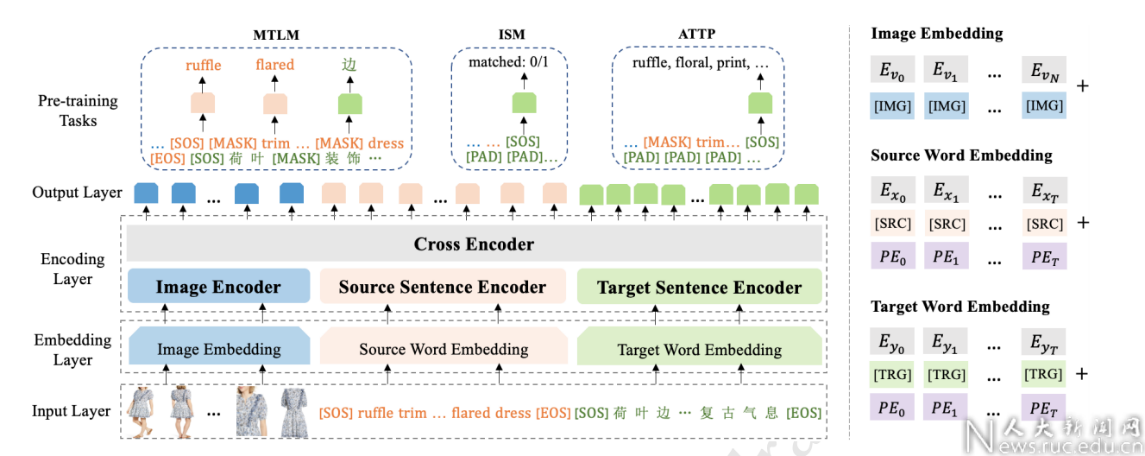
多模态机器翻译近些年来逐渐成为vision-and-language方向下的热门研究任务之一。它旨在利用视觉模态信息提升文本机器翻译的质量。其最大的应用场景是电商产品描述翻译。为了更好地服务全球化电商用户,产品描述往往需要自动翻译至多种语言。而产品的图片可以帮助模型更好地理解文本的语义信息,从而实现更准确的多语言翻译。然而,目前的多模态机器翻译工作均在日常图片描述数据集上进行模型设计与实验,与真实的电商场景差异巨大。比如,在电商场景下,文本与图片的语义相关性更加复杂,既包括客观的商品细节,又包括主观的风格等。除此之外,电商产品描述中包含了更多的专业术语,使得文本更加具有歧义性,从而为翻译带来困难。
为了更好地模拟真实应用场景,我们构建了一个新的大规模电商领域多模态机器翻译数据集Fashion-MMT,并提出了一个多模态多语言预训练模型和三种预训练任务来更好地学习商品图片与描述之间的视觉语义对齐关系。经实验发现,无论在通用多模态机器翻译任务上,还是电商多模态机器翻译任务上,我们的模型即便在不扩充任何训练数据的情况下,都明显优于非预训练模型,在两个数据集上均取得了SOTA结果。
论文题目:Missing Modality Imagination Network for Emotion Recognition with Uncertain Missing Modalities(ACL 2021)
作者:赵金明,李瑞晨,金琴
通讯作者:金琴
论文概述:

在以往的多模态情感识别工作中,多模态融合技术往往可以提高情感识别模型的识别能力。但是在实际应用中,经常遇到模态缺失的问题,同时并不知道具体哪种模态的信息会丢失。在这种情况下,在完整模态上训练的模型的情感识别能力会遇到很大的影响。
在这项工作中,团队提出了缺失模态想象网络(MMIN),这是一个可以应用于各种不同的缺失模态场景的统一模型。 MMIN学习鲁棒的联合多模态表示,根据已有模态的信息预测缺失模态的特征表示。团队在两个基准数据集上的实验表明,在不确定的缺失模态测试条件和全模态测试条件下,提出的MMIN模型都能显著提高多模态情感识别的性能。
论文题目:MMGCN: Multimodal Fusion via Deep Graph Convolution Network for Emotion Recognition in Conversation(ACL 2021)
作者:胡景文,刘宇辰,赵金明,金琴
通讯作者:金琴
论文概述:
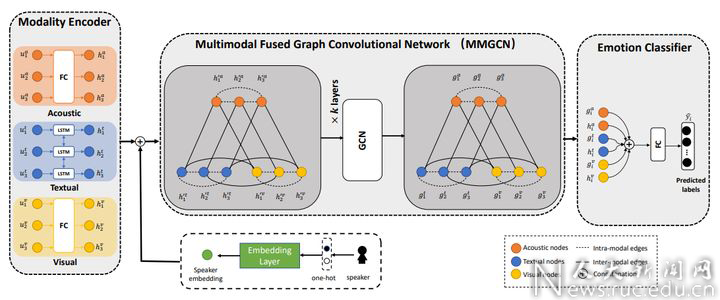
对话中的情感识别(ERC)是情感对话系统中的重要组成部分,这个任务能够帮助系统理解用户的情感并生成富含情感的回答。目前ERC任务上的大多数工作主要基于文本模态对对话者信息和上下文信息进行建模,或者简单地对多模态特征进行拼接来利用多模态信息,没有有效地利用多模态的信息。
为了探索一种更有效的方式来对多模态信息和长距离上下文依赖进行建模,团队提出了一种多模态的图卷积神经网络(MMGCN)。MMGCN不仅能够充分利用多模态依赖,而且能够利用speaker的信息来对对话者之间的依赖和对话者内部的依赖进行建模。团队在两个公开的数据集(IEMOCAP和MELD)上进行了实验,结果证明了MMGCN的有效性,在多模态的设置下超过了这个任务上其他SOTA的方法。
来源:信息学院