
高瓴人工智能学院6篇师生论文被CCF A类会议ACL录用

中国人民大学高瓴人工智能学院6篇师生论文被国际顶级学术会议ACL录用。ACL是计算语言学和自然语言处理领域最重要的顶级国际会议,是中国计算机学会(CCF)推荐的A类国际学术会议。ACL将于8月1日至6日在泰国曼谷举办。
截至目前,2021年高瓴人工智能学院已发表或被录用CCF A类国际期刊或和会议论文43篇、CCF B类期刊和论文5篇,以人大师生为第一作者或通讯作者发表的论文数量为46篇。

论文题目:Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
作者:刘沛羽,高泽峰,赵鑫,谢志远,卢仲毅,文继荣
通讯作者:赵鑫,卢仲毅
论文概述:基于量子多体物理问题中的矩阵乘积算符(MPO)表示方法,本文提出了一种新颖的预训练语言模型压缩方法。其中,MPO表示可以将权重矩阵表示为中间张量(包含主要信息)和辅助张量(包含极少参数量)的乘积形式。基于此,我们借助矩阵的MPO表示形式,提出了一种新颖的微调策略,即只需要更新包含极少参数的辅助张量就能实现对整体权重矩阵的更新。同时,我们也设计了一种新的优化方法来训练MPO表式下的多层网络结构。除此之外,本文提出的方法具有通用性,不论是原始的模型还是已经压缩过的模型上,均可以极大程度地降低需要微调的参数量。在本文实验中也说明了该方法在模型压缩上的有效性,最终可以减少平均93%的待微调参数量。
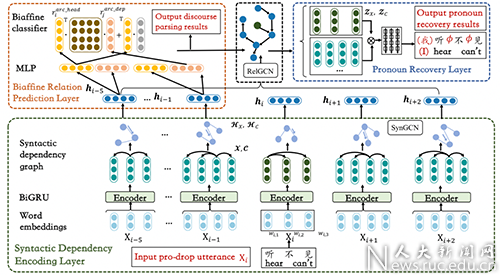
论文题目:A Joint Model for Dropped Pronoun Recovery and Conversational Discourse Parsing in Chinese Conversational Speech
作者: 杨婧璇,许珂瑞,徐君,李思,高升,郭军,薛念文,文继荣
通讯作者:徐君
论文概述:在中文自然语言对话中,对话语篇分析和代词补全是互相关联的两个任务:语篇分析可以帮助对话模型更好地理解对话片段语意信息,更准确地找出代词所指;补全被省略的代词则可以使得对话中文本信息更加完整,能够更准确地预测任意两句话间的语篇关系。本论文提出一个可以同时解决上述两个任务的联合训练模型,通过参数共享和目标函数的联合优化实现了两个任务的知识共享。实验结果表明,此联合优化方式可使两个任务互相促进,同时提升代词补全和对话语篇分析的精度,为对话相关的下游任务提供精确的语义信息编码。
论文题目:A Pre-training Strategy for Zero-Resource Response Selection in Knowledge-Grounded Conversations
作者:陶重阳,陈畅与,冯家展,文继荣,严睿
通讯作者:严睿
论文概述:近年来,许多关于检索式对话系统的研究正关注于如何在与人类交谈时有效地利用背景知识(例如文档等)。然而,收集大规模基于特定背景文档进行对话的数据集并不容易,这阻碍了我们对系统中知识选择模块和回复选择模块进行有效充分的训练。为了克服这一挑战,我们将基于知识进行回复选择的训练分解为三个任务:1)查询与文档的匹配;2)问题与对话历史的匹配;3)多轮对话的回复匹配,并在统一的预训练语言模型中对所有这些任务进行联合的学习。前两个任务可以帮助模型进行知识选择和理解,而最后一个任务可以让模型在给定查询和背景知识(对话历史)后,选择合适的回复。通过这种方法,模型可以借助ad-hoc检索数据和大量的自然的多轮对话数据,学习如何选择相关的知识和适当的回复。我们在基于知识进行对话的两个Benchmark上进行了实验,结果表明,与现有的几种基于众包数据的训练方法相比,该模型能够取得相当的效果提升。
论文题目:Few-shot Knowledge Graph-to-Text Generation with Pretrained Language Models
作者:李军毅,唐天一,赵鑫,魏志成,袁晶,文继荣
通讯作者:赵鑫
论文概述:本文研究如何自动生成描述知识图谱(KG)中事实的自然语言文本。借助预训练语言模型(PLMs)在语言理解和生成方面的能力,我们主要考虑少样本场景。我们提出了三个主要的技术贡献,即用于弥合KG编码和PLM之间语义差距的表示对齐,用于生成更好的输入表示的基于关系的KG线性化策略,以及用于学习KG和文本之间对应关系的多任务学习。在三个基准数据集上进行的大量实验证明了我们的模型在KG到文本生成任务上的有效性。特别是,我们的模型可以实现在只有几百个标记样本的情况下取得非常好的效果。
论文题目:Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval
作者:任瑞阳,吕尚文,曲瑛琪,刘璟,赵鑫,佘俏俏,吴华,王海峰,文继荣
通讯作者:刘璟,赵鑫
论文概述:近年来,dense passage retrieval已经成为多种NLP任务中召回相关信息的主流方法,双塔式检索模型是该方法广泛采用的模型结构。现有方法在训练中主要考虑了query和段落之间的相似度关系,我们提出在双塔式检索模型训练时,同时考虑query和段落间、正负例段落间的相似度关系,来捕捉到更复杂的相似度关系。另外,我们提出了一个高效的两阶段训练过程,同时利用知识蒸馏的方法,构造了高质量的伪标签数据,保证了训练的效果。我们在MSMARCO和Natural Questions两个公开数据集上进行了大量实验,证明了方法的有效性,并验证了学习到的相似度关系。
论文题目:Enhancing the Open-Domain Dialogue Evaluation in Latent Space
作者:产张明,刘乐茂,李俊涛,张海松,赵东岩,史树明,严睿
通讯作者:严睿
论文概述:开放域对话中“one-to-many”特性导致了其自动评估方法的设计成为一个巨大的挑战。最近的研究试图通过直接考虑生成的回复与对话上下文的匹配度来解决该问题,并利用判别模型从多个正样本中学习。尽管这类方法取得了令人兴奋的进展,但它们无法应用于没有多个合理回复的训练数据——而这正是真实世界数据集的一般情况。为此,我们提出通过隐空间建模增强的对话评估指标——EMS。具体来说,我们利用自监督学习来获得一个平滑的隐空间,该空间既可提取对话的上下文信息,也可以对该上下文可能的合理回复进行建模。然后我们利用隐空间中捕捉的信息对对话评测过程进行增强。在两个真实世界对话数据集上的实验结果证明了我们方法的优越性,其中与人类判断相关的Pearson和Spearman相关性分数均胜过所有基线模型。
来源:高瓴人工智能学院