
高瓴人工智能学院师生10篇论文被CCF A类会议SIGIR 2021录用

4月15日,中国计算机学会(CCF)推荐的A类国际学术会议SIGIR 2021论文接收结果公布。高瓴人工智能学院师生有10篇论文被录用,其中长文9篇,学院主要作者论文7篇,Resource论文1篇,并有多篇短文录用。SIGIR是人工智能领域智能信息检索方向最权威的国际会议。第44届国际计算机学会信息检索大会(The 44rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2021)计划于2021年7月11日-7月15日以线上会议形式召开。这次会议共收到720篇长文投稿,仅有151篇长文被录用,录用率约21%。
附:论文介绍
论文题目:Counterfactual Reward Modification for Streaming Recommendation with Delayed Feedback
作者:张骁,贾浩男,苏函晶,王文瀚,徐君,文继荣
通讯作者:徐君
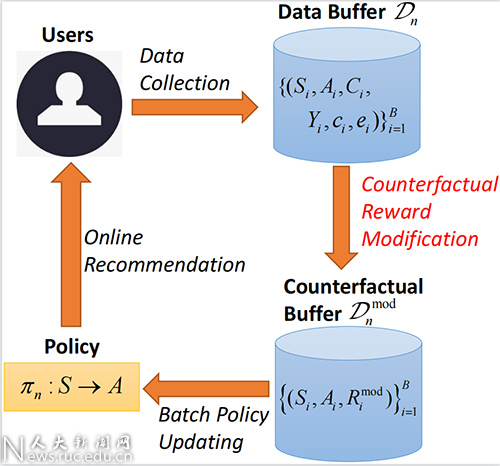
论文概述:推荐系统中普遍存在用户延迟反馈问题。例如,在优惠券推荐场景中,用户对所推荐优惠券的反馈通常包含即时领取和延迟核销两部分。用户的延迟反馈问题会使得收集到的用户历史数据中存在标签缺失或标签错误的情形,导致学习到的推荐模型存在偏差,对推荐效果造成了负面影响。该问题在推荐模型需要频繁更新、训练样本收集时间较短的流式场景中尤为突出。本文提出了一种可自动修正用户反馈的反事实批量化赌博机算法(Counterfactual Bandit with Delayed Feedback,CBDF)。CBDF将延迟反馈下的推荐问题归约为序列决策问题并应用批量化赌博机建模。对于延迟反馈,CBDF在序列决策中的每一幕中,应用反事实采样方法修正用户反馈,生成修正后的奖励值,并应用批量化赌博机策略实现在线推荐。理论分析表明所提出的奖励修正方法是统计无偏的,并且学习到的推荐策略序列较最优策略具有亚线性的后悔界。在人工数据、公开数据和腾讯实际产品数据上的实验结果表明:所提出的CBDF较已有推荐算法具有较高的CVR和CTCVR,且具有较高的计算效率。
论文题目:Counterfactual Data-Augmented Sequential Recommendation
作者:王振磊,张景森,许洪腾,陈旭,张永峰,赵鑫,文继荣
通讯作者:陈旭
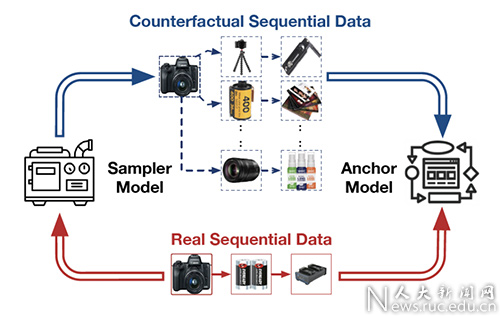
论文概述:序列化推荐旨在根据用户历史行为来预测用户未来的喜好。然而,真实的推荐数据往往非常稀疏,这使得现有的序列化推荐模型不能很好的发挥作用。为了缓解这一问题,本文提出一种新的基于反事实数据增强的训练框架。具体来说,该框架由Sampler模型和Anchor模型组成。Sampler模型旨在生成新的用户行为序列,而Anchor模型则基于真实序列和生成序列进行联合训练,并最终输出推荐列表。该框架所关心的反事实问题是:“如果用户以前购买的商品发生了改变,那么他/她下一时刻会购买什么?”。围绕这一问题,本文提出了三种方法来实现Sampler模型,并在理论上分析,如果sampler模型存在噪声,它将如何影响Anchor模型的训练以及需要生成的样本数。为了验证该框架的普适性和优越性,本文在九个真实数据集和三种当前主流的序列化推荐模型上对所提出的方法进行了验证。
论文题目:Knowledge-based Review Generation by Coherence Enhanced Text Planning
作者:李军毅,赵鑫,魏志成,袁晶,文继荣
通讯作者:赵鑫
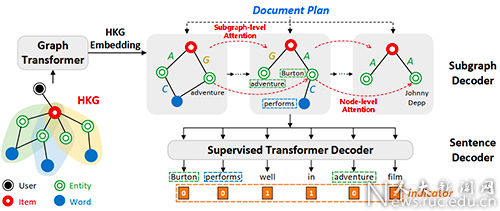
论文概述:生成信息丰富、连贯性强的评论文本是自然语言生成中一个具有挑战性的任务。为了丰富文本内容,现有的解决方案通常从知识图谱中学习如何复制实体或三元组。然而,这些方法对如何选择和安排知识图谱缺乏整体的考虑,容易造成文本不连贯问题。为了解决上述问题,我们以实体为中心,利用知识图谱的语义结构提高生成评论文本的连贯性。在本文中,我们提出了一种基于知识图谱的增强连贯性文本规划模型(CETP),以提高生成评论文本的全局连贯性和局部连贯性。我们的模型学习生成两个阶段的文本规划:(1)文档规划为一个句子规划序列;(2)每个句子规划是一个基于实体的知识图谱子图。局部连贯性可以自然而然地通过子图上实体与实体间的句内关系实现。对于全局连贯性,我们设计了一个层次自注意架构,学习子图在节点级和子图级的关系,以增强子图之间的全局连贯性。
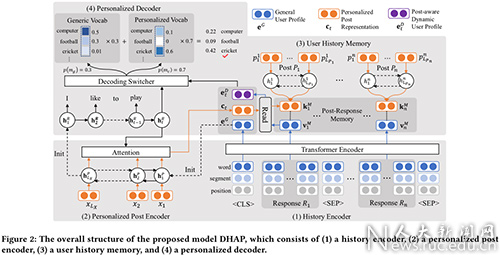
论文题目:One Chatbot Per Person: Creating Personalized Chatbots based on Implicit User Profiles
作者:马正一,窦志成,朱余韬,钟函汛,文继荣
通讯作者:窦志成
论文概述:个性化聊天机器人希望赋予聊天机器人一种能保持高度一致性的个性,从而使聊天机器人能够表现的像一位真正的用户,给出更多有信息量的回复,进一步可用作个性化助理服务人类。现有的个性化方法试图根据显式的用户画像来生成个性化回复,这种显式用户画像往往是几个人工标注的用于描述一位用户性格的句子。但是,我们认为,获取显式用户画像的过程是极其昂贵而耗时的,这使得此类个性化方法在现实世界无法得到大规模应用。同时,这种严格事先定义好的描述语句忽略了真实用户的聊天习惯,且在使用中无法随着用户兴趣的变化而实时更新。因此,在本文中,我们提出了一种从用户的大规模对话历史中自动学习用户的隐式画像,并利用该隐式用户画像进行回复生成的方法。具体来说,借助Transformer在语言建模方面的优势,我们设计了一个个性化语言模型,来从用户的历史回复中构建用户的通用用户画像。进一步地,为了能够强调与当前输入最相关的历史回复,我们构建了一个键值对记忆神经网络来存储用户的历史输入-回复对,并计算了用户的动态用户画像。动态用户画像主要反映了用户在历史中针对相似输入回复了什么,以及如何回复的。为了显式地利用用户的常用词汇,我们设计了一个融合了两种解码策略的个性化解码器,包括从通用词表中生成单词,以及从用户的个性化词表中复制单词两种策略。我们在微博与Reddit两个大规模对话数据集上进行了实验,实验结果表明我们的模型相比现有方法有明显的效果提升。
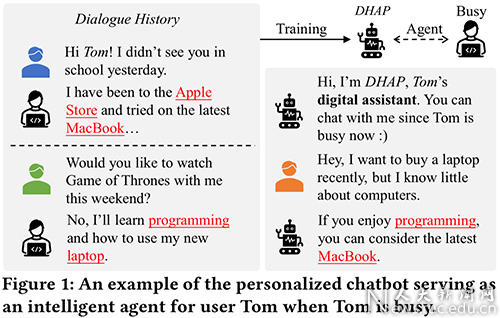
(一个个性化聊天机器人作为用户Tom的智能助理的例子)
(模型结构图)
论文题目:Modeling Intent Graph for Search Result Diversification
作者:苏展,窦志成,朱余韬,秦绪博,文继荣
通讯作者:窦志成
论文概述:搜索结果的多样化旨在提供覆盖尽可能多意图的文档。现有的大多数隐式多样化方法都是通过文档表示的相似性来建模文档的多样性,这种间接的方式显得不太自然。为了更精确地建模文档的多样性,我们提出通过意图覆盖的相似性来衡量两个文档的相似性。具体来说,我们建立一个分类器,根据文件的内容判断两个不同的文档是否包含相同的意图。然后,我们构造一个意图图来表示文档和查询之间的复杂关系。在初始状态时相似的文档相互连接,在文档选择的过程中查询和文档根据文档选择的结果依次连接。在意图图上,我们使用图卷积神经网络来聚集其邻居结点信息,从而更新查询和每个文档的表示。通过这种方式,我们可以在文档选择过程中获得上下文感知的查询表示和意图感知的文档表示。最后,我们融合了基于图的表示和多种特征对文档进行最终的排序。实验结果表明,这种隐式多样化模型不逊色于目前最好的显式多样化模型。
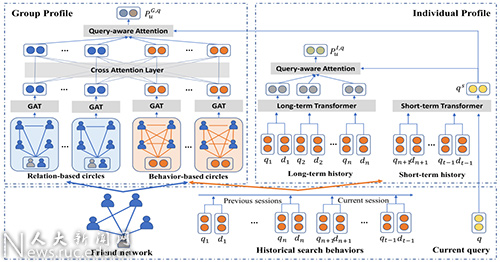
论文题目:Group based Personalized Search by Integrating Search Behaviour and Friend Network
作者:周雨佳,窦志成,魏秉政,谢若冰,文继荣
通讯作者:窦志成
论文概述:个性化搜索的关键是基于历史行为构建用户画像。针对缺乏历史数据的用户,基于组的个性化模型被提出,这些方法在对结果重排时,将相似用户的画像考虑在内。然而,现有的寻找相似的用户的方法大多简单地基于搜索行为中词汇或主题的相似性。本文提出了一种基于神经网络的增强方法,在语义空间中突出相似用户的作用。此外,我们认为,当用户只包含有限的历史行为时,基于行为的相似用户仍然不足以帮助用户理解新的查询。为了解决这个问题,我们将朋友网络引入个性化搜索中,以另一种方式确定用户之间的亲密度关系。由于朋友关系往往是基于相似的背景或兴趣而形成的,所以在朋友网络中自然隐藏着大量个性化的信息。在搜索行为和朋友关系的融合下,相似用户在基于组的个性化搜索中更为可靠地得到了强化。具体来说,我们分别针对用户的搜索行为和朋友关系将其划分到多个朋友圈。这两种朋友圈是互补的,从而构建一个更全面的群体画像来实现搜索结果个性化。实验结果表明,与现有个性化模型相比,本文提出的模型有了显著的提升。
论文题目:Pchatbot: A Large-Scale Dataset for Personalized Chatbot(Resource Paper)
作者:钱泓锦,李小禾,钟函汛,郭宇,马跃元,朱余韬,刘占亮,窦志成,文继荣
通讯作者:窦志成
论文概述:近年来,对话系统发展迅速,其中大多数对话系统依赖于大规模、高质量的数据集。本文介绍了一个大规模的对话数据集PChatbot。这个数据集是迄今最大规模的中文对话数据集,它由两个子数据集组成,分别来自于微博和司法论坛。为了更合理地使用原始数据,我们对其进行了匿名化、去重、分词、过滤等清洗操作。此外,现有个性化对话数据集往往通过几句人格描述或人物属性来刻画个性化信息。与这些个性化数据集不同的是,PChatbot提供经过匿名化处理的用户ID和问答对的时间戳。这使得我们能够构建用户的对话历史,从而从中直接学习隐式的个性化信息。我们使用了几个前沿模型在PChatbot上进行了实验,为之后使用我们数据集的工作提供了参照。目前,PChatbot数据集和相应的代码工具都已开源。
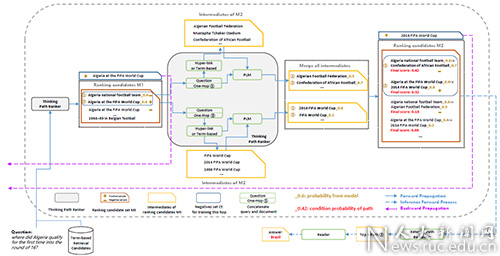
论文题目:Answer Complex Questions: Path Ranker Is All You Need
作者:张鑫宇,詹珂,胡恩瑞,付成真,罗兰,蒋昊,贾岩涛,于璠,曹朝,窦志成,陈雷
论文概述:在多跳问答领域中常用的方法是采用多轮迭代检索和排序的方式获得全面的支撑文档,最后再由阅读器提取答案。然而现有的迭代排序器都是利用当前跳的正负样本进行训练的,而并不在意到当前跳为止的全局排序情况,这种贪心策略往往会导致检索出的排序文档与真实的支撑文档存在较大的差距。为了解决上述问题,本文提出了一种可思考的路径重排模型,Thinking Path Re-Ranker (TPRR);该模型的Thinking Path Ranker(TPR)部分首先使用Term方法做粗召,并建立了排序路径概念,即以上一跳的排序文档为条件生成下一跳的排序文档,进而形成一条排序路径;接下来使用预训练语言模型对每跳候选文档计算分数并形成概率,再根据条件概率建模推出在Query条件下整条排序路径的概率,并用截止到当前跳的路径概率来筛选当前跳的文档;同时在训练过程中,为了进一步增强每跳模型训练时负样本的难度,利用当前检索结果的TopK作为负样本,并由这些负样本构建下一跳的候选文档,由于条件概率建模,整条排序路径端到端可导,随着监督信号的回传不断加大TopK负样本的难度,并使得当前跳的监督信号也对之前跳的模型产生监督作用,该方法大幅改善了排序器的鲁棒性。在模型的External Path Ranker(EPR)部分,为了防止TPR迭代排序出现过拟合问题,采用单独训练的外部排序器EPR对TPR筛选出的Top8路径做进一步重排,提升Top1的准确率。本文在业界多跳问答权威数据集HotpotQA上进行验证,并在Top8和Top1 PEM上成为了业界SOTA,同时在榜单上取得了业界第一名的成绩。
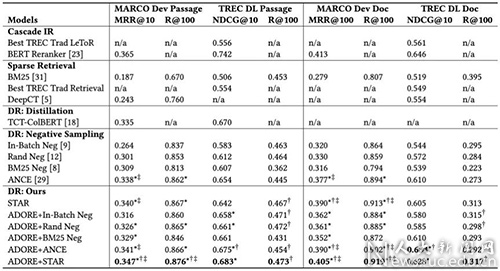
论文题目:Optimizing Dense Retrieval Model Training with Hard Negatives
作者:詹靖涛,毛佳昕,刘奕群,郭嘉丰,张敏,马少平
论文概述:搜索结果排序一直是信息检索领域核心的研究问题。传统的检索模型主要依靠词级别的匹配信息,近年来随着深度表示学习技术的出现,一些研究者开始尝试使用基于稠密向量的检索模型(Dense Retrieval)来进一步提升检索性能。训练一个好的稠密向量检索模型依赖于训练数据的采样。本文针对如何有效的采样用以训练稠密向量检索模型负样本进行了研究。我们首先在理论上对现有的训练方式进行了深入分析,并尝试解释为什么在训练中采样难负样本(hard negatives)比随机采样排序效果更好。通过分析,我们进一步发现,被广泛使用的静态的难负样本采样策略会给训练带来潜在的风险。因此,我们提出了两种新的名为STAR和ADORE训练策略。STAR策略把静态的难负样本采样和随机采样结合,在优化top k排序指标的同时保证训练过程稳定;ADORE策略进一步用动态难负例(dynamic hard negatives)来训练查询编码器,提升检索性能。在公开数据集上的实验表明,这两种训练策略能有效的提升现有稠密向量检索模型的检索性能。同时,这两种训练策略的运行效率也显著优于现有的基线模型。
(表 STAR和ADORE策略在MS MARCO和TREC DL数据集上的检索性能)
论文题目:Investigating User Behavior in Legal Case Retrieval
作者:邵韵秋,吴玥悦,刘奕群,毛佳昕,张敏,马少平
论文概述:类案检索是一类特殊的信息检索任务,其目标是在给定一个查询案件时,检索能支持该案件判决的相关案件。当前类案检索方面的研究主要针对如何提升类案检索模型的性能,但很少有研究者关注在实际的类案检索过程中用户是如何与检索系统完成交互的。因此,在该研究中,我们通过组织了一次有45个被试参加的类案检索用户实验,对用户在类案检索场景下的搜索行为进行了细致的研究分析。基于用户实验收集到的数据,我们首先对类案检索任务的特征进行了分析,并观察到了一些类案检索和普通搜索任务间存在的显著差异。接着,我们从任务难度、用户专业程度等角度,分析了影响用户类案搜索行为的各种因素。最后,我们还分析了类案检索环境下用户的隐式反馈,并设计了一个在该环境下基于用户搜索行为预测结果相关性的模型。作为少数针对类案检索环境用户行为研究,该研究有加深了对类案检索中用户行为的理解,并有助于设计更好的类案检索系统。
来源:高瓴人工智能学院